标签: python-tesseract
训练 Tesseract 来标记图标
我正在尝试为 Tesseract 4.0 创建训练数据来识别屏幕截图中的图标(例如,评论,分享,保存)。这是一个示例屏幕截图:
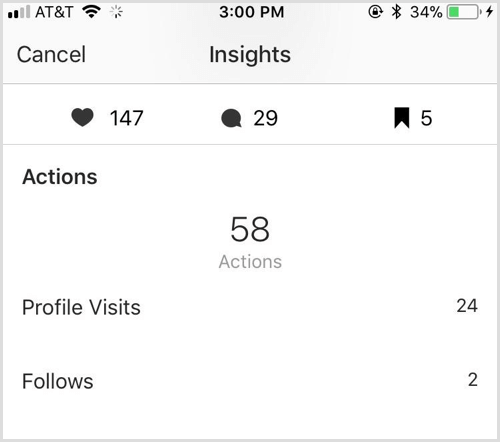
我想微调 Tesseract 以实现如下输出:
Like 147
Comment 29
Saved 5
Actions
58
Actions
Profile Visits 24
Follows 2
我已按照https://pretius.com/how-to-prepare-training-files-for-tesseract-ocr-and-improve-characters-recognition/中所述逐步进行操作
我修改了盒子文件如下:
- 心:喜欢
- 语音气泡:评论
- 书签:已保存
- 箭头:分享
但是,最终的训练数据未能按照我想要的方式读取图标。我遇到的错误示例是“Like is not in unicharset”。在为图标创建 unicharset 时我需要做一些不同的事情吗?
推荐指数
解决办法
查看次数
使用 cv2 / pytesseract 增强数字识别的局部对比度
我想使用 pytesseract 从图像中读取数字。图像如下:


数字是点状的,为了能够使用 pytesseract,我需要白色背景上的黑色连接数字。为此,我考虑使用侵蚀和扩张作为预处理技术。正如您所看到的,这些图像很相似,但在某些方面却截然不同。例如,第一幅图像中的点比背景更暗,而第二幅图像中的点比背景更白。这意味着,在第一张图像中,我可以使用侵蚀来获得黑色连接线,在第二张图像中,我可以使用扩张来获得白色连接线,然后反转颜色。这导致以下结果:


使用适当的阈值,可以使用 pytesseract 轻松读取第一张图像。第二张图片,不管是谁,都比较棘手。问题是,例如“4”的某些部分比“3”周围的背景更暗。所以简单的阈值是行不通的。我需要诸如局部阈值或局部对比度增强之类的东西。这里有人有想法吗?
编辑:
OTSU、平均阈值和高斯阈值导致以下结果:

推荐指数
解决办法
查看次数
如何提高该图像的 OCR 准确性?
我将使用 Python 中的 OpenCV 和 OCR by 来从图片中提取文本pytesseract。我有这样的图像:

然后我编写了一些代码来从该图片中提取文本,但它没有足够的精度来正确提取文本。
这是我的代码:
import cv2
import pytesseract
img = cv2.imread('photo.jpg')
img = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
_,img = cv2.threshold(img,110,255,cv2.THRESH_BINARY)
custom_config = r'--oem 3 --psm 6'
text = pytesseract.image_to_string(img, config=custom_config)
print(text)
cv2.imshow('pic', img)
cv2.waitKey(0)
cv2.destroyAllWindows()
我已经测试过cv2.adaptiveThreshold,但它不起作用cv2.threshold。
最后,这是我的结果,与图片中的结果不同:
Color Yellow RBC/hpf 4-6
Appereance Semi Turbid WBC/hpf 2-3
Specific Gravity 1014 Epithelial cells/Lpf 1-2
PH 7 Bacteria (Few)
Protein Pos(+) Casts Negative
Glucose Negative Mucous (Few)
Keton Negative
Blood Pos(+)
Bilirubin Negative …推荐指数
解决办法
查看次数
分割多列图像以进行 OCR
我正在尝试从这样的几页中裁剪两列,以便以后进行 OCR,查看沿垂直线分割页面

到目前为止我所得到的是找到标题,以便可以将其裁剪掉:
image = cv2.imread('014-page1.jpg')
im_h, im_w, im_d = image.shape
base_image = image.copy()
gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
blur = cv2.GaussianBlur(gray, (7,7), 0)
thresh = cv2.threshold(blur, 0, 255, cv2.THRESH_BINARY_INV + cv2.THRESH_OTSU)[1]
# Create rectangular structuring element and dilate
kernel = cv2.getStructuringElement(cv2.MORPH_RECT, (50,10))
dilate = cv2.dilate(thresh, kernel, iterations=1)
# Find contours and draw rectangle
cnts = cv2.findContours(dilate, cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE)
cnts = cnts[0] if len(cnts) == 2 else cnts[1]
cnts = sorted(cnts, key=lambda x: cv2.boundingRect(x)[1])
for c in cnts:
x,y,w,h = cv2.boundingRect(c) …推荐指数
解决办法
查看次数
KeyError:使用 pytesseract.image_to_data 时出现“PNG”
我尝试使用 pytesseract function 在图像文件中的文本周围放置方框image_to_data,但在 colab 上遇到以下错误:
KeyError Traceback (most recent call last)
<ipython-input-10-a92a28892aac> in <module>()
6 img = cv2.imread("a.jpg")
7
----> 8 d = pytesseract.image_to_data(img, output_type=Output.DICT)
9 print(d.keys())
5 frames
/usr/local/lib/python3.7/dist-packages/PIL/Image.py in save(self, fp, format, **params)
2121 expand=0,
2122 center=None,
-> 2123 translate=None,
2124 fillcolor=None,
2125 ):
KeyError: 'PNG'
我正在使用的代码是:
import cv2
import pytesseract
from pytesseract import Output
from PIL import Image
img = cv2.imread("a.jpg")
d = pytesseract.image_to_data(img, output_type=Output.DICT)
print(d.keys())
考虑到可能image_to_data只能使用 PNG 而不能使用 jpeg (这很奇怪),我添加了几行来将 jpeg …
推荐指数
解决办法
查看次数
pytesseract临时输出文件“没有这样的文件或目录”错误
我正在使用 pytesseract 和以下行:
text = image_to_string(temp_test_file,
lang='eng',
boxes=False,
config='-c preserve_interword_spaces=1 hocr')
并得到错误
pytesseract.py
135| f = open(output_file_name, 'rb')
No such file or directory:
/var/folders/j3/dn60cg6d42bc2jwng_qzzyym0000gp/T/tess_EDOHFP.txt
在这里查看 pytesseract 的源代码,似乎无法找到用于存储 tesseract 命令输出的临时输出文件。
我在这里看到了其他答案,这些答案已通过检查 tesseract 是否已安装并可从命令终端调用来解决,对我来说是这样,所以这不是这里的问题。任何想法这可能是什么以及如何解决它?谢谢
推荐指数
解决办法
查看次数
字符串比较在python中不起作用
我正在编写一个与tesseract-ocr. 我从屏幕上获取文本,然后我需要将它与字符串进行比较。问题是即使我确定字符串相同,比较也会失败。
我怎样才能让我的代码工作?
这是我的代码:
import pyscreenshot as pss
import time
from pytesser import image_to_string
buy=str("VENDI")
buyNow=str("VENDI ADESSO")
if __name__ == '__main__':
while 1:
c=0
time.sleep(2)
image=pss.grab(bbox=(1104,422,(1104+206),(422+30)))
text = str(image_to_string(im))
print text
if text==buy or text==buyNow:
print 'ok'
例如作为输入:

作为输出,我得到:
文迪阿德索
哪个是我需要比较的相同字符串,但在执行过程中我没有进入ok控制台?
推荐指数
解决办法
查看次数
Pytesseract Image_to_string 返回 Windows 错误:Python 中的访问被拒绝错误
我尝试使用 Pytesseract 从图像中读取文本。运行以下脚本时收到拒绝访问消息。
from PIL import Image
import pytesseract
import cv2
import os
filename=r'C:\Users\ychandra\Documents\teaching-text-structure-3-728.jpg'
pytesseract.pytesseract.tesseract_cmd = r'C:\Python27\Lib\site-packages\pytesseract'
image=cv2.imread(filename)
gray=cv2.cvtColor(image,cv2.COLOR_BGR2GRAY)
gray=cv2.threshold(gray,0,255,cv2.THRESH_BINARY|cv2.THRESH_OTSU)[1]
gray=cv2.medianBlur(gray,3)
filename='{}.png'.format(os.getpid())
cv2.imwrite(filename,gray)
text=pytesseract.image_to_string(Image.open(filename))
print text
cv2.imshow("image",image)
cv2.imshow("res",gray)
cv2.waitKey(0)
当我运行脚本时,我遇到了错误
Traceback (most recent call last):
File "F:\opencv\New_folder_3\text_from_image.py", line 17, in <module>
text=pytesseract.image_to_string(Image.open(filename))
File "C:\Python27\lib\site-packages\pytesseract\pytesseract.py", line 122, in image_to_string
config=config)
File "C:\Python27\lib\site-packages\pytesseract\pytesseract.py", line 46, in run_tesseract
proc = subprocess.Popen(command, stderr=subprocess.PIPE)
File "C:\Python27\lib\subprocess.py", line 390, in __init__
errread, errwrite)
File "C:\Python27\lib\subprocess.py", line 640, in _execute_child
startupinfo)
WindowsError: [Error 5] Access is denied
推荐指数
解决办法
查看次数
pytesseract image_to_string 不拉字符串,但没有错误
我在 pytesseract 包中使用 image_to_string 函数将单个图片文件的多个部分转换为字符串。除此图像外,所有部件均正常工作:

这是我用来转换它的脚本:
from PIL import Image
import pytesseract
pytesseract.pytesseract.tesseract_cmd = 'C:/Program Files (x86)/Tesseract-OCR/tesseract'
im = Image.open('image.png')
text = pytesseract.image_to_string(im)
print(text)
这给出了输出:
—\—\—\N—\—\—\—\—\N
我尝试将图像分解成更小的部分,并将图像处理为 jpg 和 png。我该怎么做才能让它输出图像中的值?
image image-processing python-imaging-library python-3.x python-tesseract
推荐指数
解决办法
查看次数
如何在py-opencv中保存dpi信息?
import cv2
def clear(img):
back = cv2.imread("back.png", cv2.IMREAD_GRAYSCALE)
img = cv2.bitwise_xor(img, back)
ret, img = cv2.threshold(img, 120, 255, cv2.THRESH_BINARY_INV)
return img
def threshold(img):
ret, img = cv2.threshold(img, 120, 255, cv2.THRESH_BINARY_INV)
img = cv2.cvtColor(img, cv2.COLOR_RGB2GRAY)
ret, img = cv2.threshold(img, 248, 255, cv2.THRESH_BINARY)
return img
def fomatImage(img):
img = threshold(img)
img = clear(img)
return img
img = fomatImage(cv2.imread("1566135246468.png",cv2.IMREAD_COLOR))
cv2.imwrite("aa.png",img)
这是我的代码。但是当我尝试用 tesseract-ocr 识别它时,我收到了警告。
Warning: Invalid resolution 0 dpi. Using 70 instead.
我应该如何设置dpi?
推荐指数
解决办法
查看次数
标签 统计
python-tesseract ×10
python ×5
opencv ×4
tesseract ×4
ocr ×3
python-2.7 ×2
comparison ×1
image ×1
opencv3.0 ×1
python-3.x ×1
string ×1
windowserror ×1