标签: apache-spark-mllib
处理Spark MLlib中的不平衡数据集
我工作在一个特定的二元分类问题具有高度不平衡的数据集,我想知道是否有人试图实现特定的技术来处理数据集不平衡(如SMOTE)的分类问题,用放电的MLlib.
我正在使用MLLib的随机森林实现,并且已经尝试了最简单的方法来随机地对较大的类进行采样,但它没有像我预期的那样工作.
如果您对类似问题的体验有任何反馈,我将不胜感激.
谢谢,
classification machine-learning apache-spark apache-spark-mllib
推荐指数
解决办法
查看次数
如何从CrossValidatorModel中提取最佳参数
我想ParamGridBuilder在Spark 1.4.x中找到CrossValidator中最佳模型的参数,
在Spark文档中的Pipeline示例中,它们通过在管道中使用来添加不同的参数(numFeatures,regParam)ParamGridBuilder.然后通过以下代码行创建最佳模型:
val cvModel = crossval.fit(training.toDF)
现在,我想知道从中产生最佳模型的参数(numFeatures,regParam)是什么ParamGridBuilder.
我已经使用了以下命令但没有成功:
cvModel.bestModel.extractParamMap().toString()
cvModel.params.toList.mkString("(", ",", ")")
cvModel.estimatorParamMaps.toString()
cvModel.explainParams()
cvModel.getEstimatorParamMaps.mkString("(", ",", ")")
cvModel.toString()
有帮助吗?
提前致谢,
pipeline scala cross-validation apache-spark apache-spark-mllib
推荐指数
解决办法
查看次数
在PySpark中编码和组合多个功能
我有一个Python类,我用它来加载和处理Spark中的一些数据.在我需要做的各种事情中,我正在生成一个从Spark数据帧中的各个列派生的虚拟变量列表.我的问题是我不确定如何正确定义用户定义函数来完成我需要的东西.
我做目前有,当映射了潜在的数据帧RDD,解决了问题的一半(记住,这是在一个更大的方法等data_processor类):
def build_feature_arr(self,table):
# this dict has keys for all the columns for which I need dummy coding
categories = {'gender':['1','2'], ..}
# there are actually two differnt dataframes that I need to do this for, this just specifies which I'm looking at, and grabs the relevant features from a config file
if table == 'users':
iter_over = self.config.dyadic_features_to_include
elif table == 'activty':
iter_over = self.config.user_features_to_include
def _build_feature_arr(row):
result = []
row = row.asDict()
for …python apache-spark apache-spark-sql apache-spark-ml apache-spark-mllib
推荐指数
解决办法
查看次数
保存ML模型以备将来使用
我正在将一些机器学习算法(如线性回归,Logistic回归和朴素贝叶斯)应用于某些数据,但我试图避免使用RDD并开始使用DataFrame,因为RDD比pyspark下的Dataframe 慢(见图1).
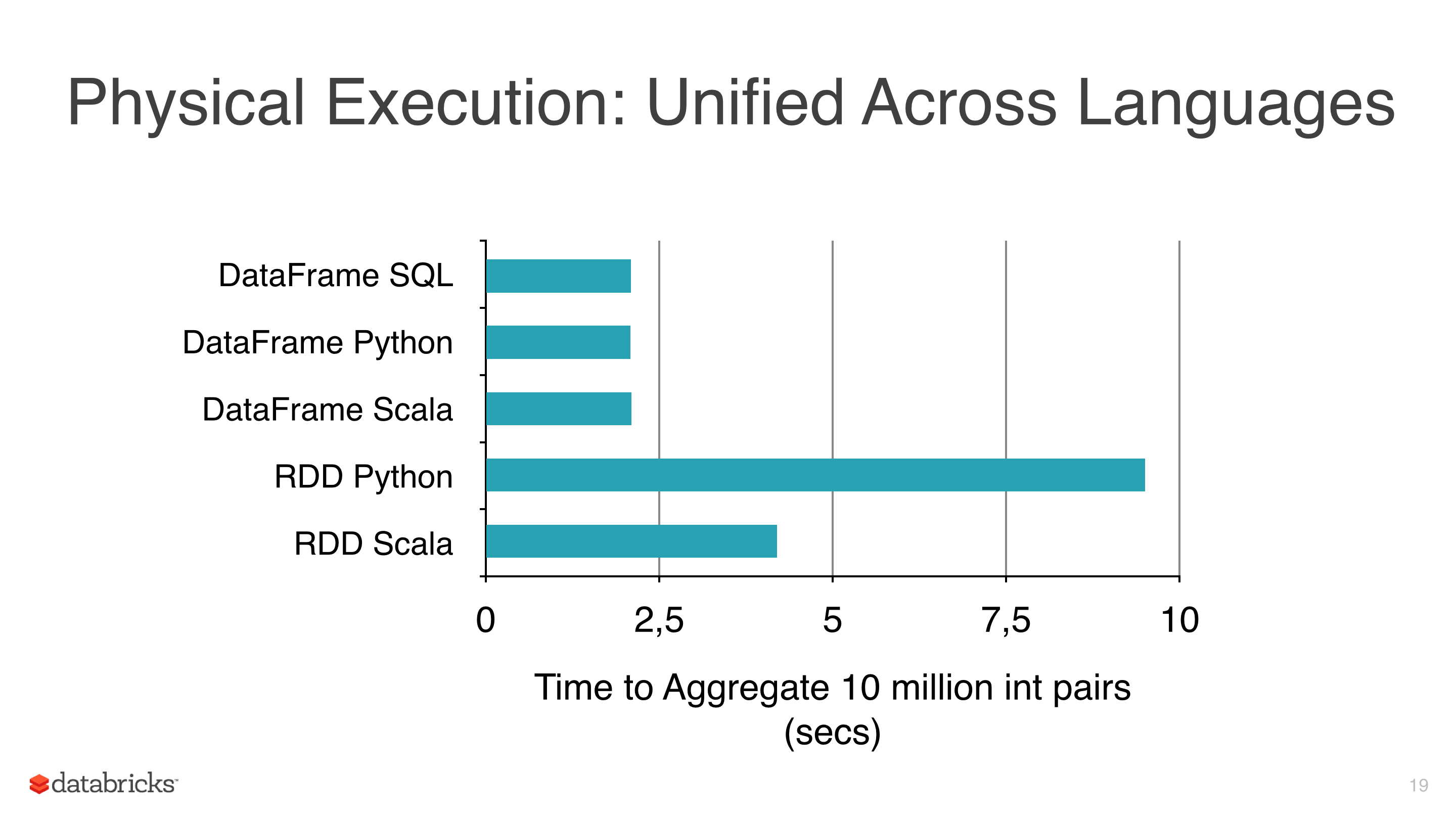
我使用DataFrames的另一个原因是因为ml库有一个非常有用的类来调整模型,CrossValidator这个类在拟合之后返回一个模型,显然这个方法必须测试几个场景,然后返回一个拟合的模型(与参数的最佳组合).
我使用的集群不是那么大,数据相当大,有些适合需要几个小时,所以我想保存这些模型以便以后重用它们,但我还没有意识到,有什么我忽略的东西?
笔记:
- mllib的模型类有一个保存方法(即NaiveBayes),但mllib没有CrossValidator并使用RDD,所以我有预谋地避免它.
- 目前的版本是spark 1.5.1.
推荐指数
解决办法
查看次数
Spark中的HashingTF和CountVectorizer有什么区别?
试图在Spark中进行doc分类.我不确定HashingTF中的散列是做什么的; 它会牺牲任何准确性吗?我对此表示怀疑,但我不知道.spark文档说它使用了"散列技巧"......只是工程师使用的另一个非常糟糕/混乱命名的例子(我也很内疚).CountVectorizer还需要设置词汇量大小,但它有另一个参数,一个阈值参数,可用于排除出现在文本语料库中某个阈值以下的单词或标记.我不明白这两个变形金刚之间的区别.使这一点很重要的是算法中的后续步骤.例如,如果我想在生成的tfidf矩阵上执行SVD,那么词汇量大小将决定SVD矩阵的大小,这会影响代码的运行时间,以及模型性能等.我一般有困难在API文档之外找到关于Spark Mllib的任何来源以及没有深度的非常简单的例子.
推荐指数
解决办法
查看次数
如何交叉验证RandomForest模型?
我想评估正在训练某些数据的随机森林.Apache Spark中是否有任何实用程序可以执行相同操作,还是必须手动执行交叉验证?
random-forest cross-validation apache-spark apache-spark-ml apache-spark-mllib
推荐指数
解决办法
查看次数
如何从PySpark中的spark.ml中提取模型超参数?
我正在修补PySpark文档中的一些交叉验证代码,并尝试让PySpark告诉我选择了哪个模型:
from pyspark.ml.classification import LogisticRegression
from pyspark.ml.evaluation import BinaryClassificationEvaluator
from pyspark.mllib.linalg import Vectors
from pyspark.ml.tuning import ParamGridBuilder, CrossValidator
dataset = sqlContext.createDataFrame(
[(Vectors.dense([0.0]), 0.0),
(Vectors.dense([0.4]), 1.0),
(Vectors.dense([0.5]), 0.0),
(Vectors.dense([0.6]), 1.0),
(Vectors.dense([1.0]), 1.0)] * 10,
["features", "label"])
lr = LogisticRegression()
grid = ParamGridBuilder().addGrid(lr.regParam, [0.1, 0.01, 0.001, 0.0001]).build()
evaluator = BinaryClassificationEvaluator()
cv = CrossValidator(estimator=lr, estimatorParamMaps=grid, evaluator=evaluator)
cvModel = cv.fit(dataset)
在PySpark shell中运行它,我可以得到线性回归模型的系数,但我似乎无法找到lr.regParam交叉验证程序选择的值.有任何想法吗?
In [3]: cvModel.bestModel.coefficients
Out[3]: DenseVector([3.1573])
In [4]: cvModel.bestModel.explainParams()
Out[4]: ''
In [5]: cvModel.bestModel.extractParamMap()
Out[5]: {}
In [15]: cvModel.params
Out[15]: [] …modeling cross-validation pyspark apache-spark-ml apache-spark-mllib
推荐指数
解决办法
查看次数
Apache Spark中的矩阵乘法
我正在尝试使用Apache Spark和Java执行矩阵乘法.
我有两个主要问题:
- 如何创建可以代表Apache Spark中的矩阵的RDD?
- 如何将两个这样的RDD相乘?
推荐指数
解决办法
查看次数
"spark.yarn.executor.memoryOverhead"设置的值?
那里,火花作业中"spark.yarn.executor.memoryOverhead"的值是应该分配给App的纱线还是仅仅是最大值?
apache-spark spark-streaming apache-spark-sql apache-spark-mllib
推荐指数
解决办法
查看次数
高斯混合模型:Spark MLlib和scikit-learn之间的区别
我正在尝试在数据集的样本上使用高斯混合模型.我使用了两个MLlib(带pyspark)和scikit-learn得到非常不同的结果,scikit-learn一个看起来更逼真.
from pyspark.mllib.clustering import GaussianMixture as SparkGaussianMixture
from sklearn.mixture import GaussianMixture
from pyspark.mllib.linalg import Vectors
Scikit-learn:
local = pd.DataFrame([ x.asDict() for x in df.sample(0.0001).collect() ])
model1 = GaussianMixture(n_components=3)
model1.fit([ [x] for x in local['field'].tolist() ])
model1.means_
array([[7.56123598e+00],
[1.32517410e+07],
[3.96762639e+04]])
model1.covariances_
array([[[6.65177423e+00]],
[[1.00000000e-06]],
[[8.38380897e+10]]])
MLLib:
model2 = SparkGaussianMixture.train(
sc.createDataFrame(local).rdd.map(lambda x: Vectors.dense(x.field)),
k=3,
convergenceTol=1e-4,
maxIterations=100
)
model2.gaussians
[MultivariateGaussian(mu=DenseVector([28736.5113]), sigma=DenseMatrix(1, 1, [1094083795.0001], 0)),
MultivariateGaussian(mu=DenseVector([7839059.9208]), sigma=DenseMatrix(1, 1, [38775218707109.83], 0)),
MultivariateGaussian(mu=DenseVector([43.8723]), sigma=DenseMatrix(1, 1, [608204.4711], 0))] …推荐指数
解决办法
查看次数
标签 统计
apache-spark ×9
pyspark ×3
python ×2
scala ×2
java ×1
modeling ×1
pipeline ×1
rdd ×1
scikit-learn ×1