保存ML模型以备将来使用
Alb*_*nto 23 apache-spark pyspark apache-spark-ml apache-spark-mllib
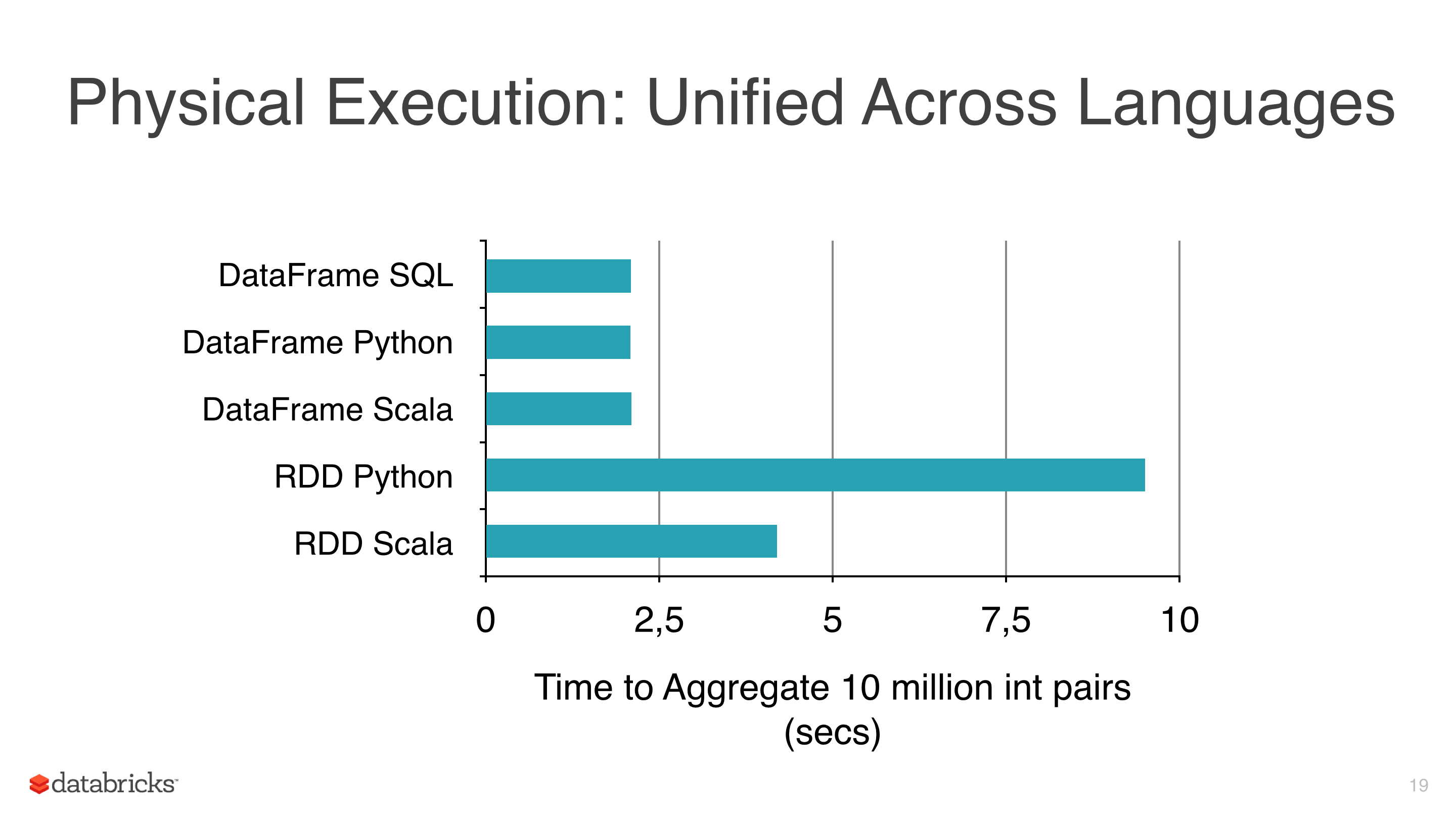
我正在将一些机器学习算法(如线性回归,Logistic回归和朴素贝叶斯)应用于某些数据,但我试图避免使用RDD并开始使用DataFrame,因为RDD比pyspark下的Dataframe 慢(见图1).
我使用DataFrames的另一个原因是因为ml库有一个非常有用的类来调整模型,CrossValidator这个类在拟合之后返回一个模型,显然这个方法必须测试几个场景,然后返回一个拟合的模型(与参数的最佳组合).
我使用的集群不是那么大,数据相当大,有些适合需要几个小时,所以我想保存这些模型以便以后重用它们,但我还没有意识到,有什么我忽略的东西?
笔记:
- mllib的模型类有一个保存方法(即NaiveBayes),但mllib没有CrossValidator并使用RDD,所以我有预谋地避免它.
- 目前的版本是spark 1.5.1.
zer*_*323 24
Spark 2.0.0+
乍一看都Transformers和Estimators实施MLWritable具有以下接口:
def write: MLWriter
def save(path: String): Unit
并MLReadable使用以下界面
def read: MLReader[T]
def load(path: String): T
例如,这意味着您可以使用save方法将模型写入磁盘
import org.apache.spark.ml.PipelineModel
val model: PipelineModel
model.save("/path/to/model")
并稍后阅读:
val reloadedModel: PipelineModel = PipelineModel.load("/path/to/model")
PySpark中也使用MLWritable/ JavaMLWritable和MLReadable/ JavaMLReadable分别实现了等效方法:
from pyspark.ml import Pipeline, PipelineModel
model = Pipeline(...).fit(df)
model.save("/path/to/model")
reloaded_model = PipelineModel.load("/path/to/model")
SparkR提供write.ml/ read.ml功能,但截至今天,它们与其他支持的语言 - SPARK-15572不兼容.
请注意,loader类必须匹配存储的类PipelineStage.例如,如果你保存LogisticRegressionModel你应该使用LogisticRegressionModel.load没有LogisticRegression.load.
如果您使用Spark <= 1.6.0并遇到模型保存的一些问题,我建议您切换版本.
除Spark特定方法外,还有越来越多的库设计用于使用Spark独立方法保存和加载Spark ML模型.请参阅示例如何提供Spark MLlib模型?.
Spark> = 1.6
从Spark 1.6开始,可以使用该save方法保存模型.因为几乎每个都model实现了MLWritable接口.例如,LinearRegressionModel拥有它,因此可以使用它将模型保存到所需的路径.
Spark <1.6
我相信你在这里做出了错误的假设.
DataFrames可以对a上的某些操作进行优化,并将其转换为与plain相比改进的性能RDDs.DataFrames提供高效的缓存和SQLish API可以说比RDD API更容易理解.
ML Pipelines非常有用,交叉验证器或不同评估器等工具在任何机器管道中都是必备的,即使上述任何一个都没有特别难以在低级别MLlib API上实现,最好还是准备好使用,通用和相对良好测试的解决方案.
到目前为止一直很好,但有一些问题:
- 至于我可以告诉简单的操作
DataFrames类似select或withColumn显示类似性能的RDD等价物,如map, - 在某些情况下,与良好调整的低级转换相比,增加典型管道中的列数实际上会降低性能.您当然可以在正确的方式上添加drop-column-transformer,
- 许多ML算法,包括
ml.classification.NaiveBayes简单的mllibAPI 包装, - PySpark ML/MLlib算法将实际处理委托给Scala对应物,
- 最后但并非最不重要的是RDD仍然在那里,即使隐藏在DataFrame API背后
我相信,在一天结束时,使用ML over MLLib可以获得相当优雅的高级API.您可以做的一件事是将两者结合起来创建一个自定义的多步骤管道:
- 使用ML加载,清理和转换数据,
- 提取所需数据(参见例如extractLabeledPoints方法)并传递给
MLLib算法, - 添加自定义交叉验证/评估
MLLib使用您选择的方法保存模型(Spark模型或PMML)
它不是最佳解决方案,但鉴于当前的API,它是我能想到的最佳解决方案.
似乎保存模型的API功能现在还没有实现(参见Spark问题跟踪器SPARK-6725).
发布了一个替代方案(如何将模型从ML Pipeline保存到S3或HDFS?),这只涉及序列化模型,但它是一种Java方法.我希望在PySpark中你可以做类似的事情,即挑选模型写入磁盘.
| 归档时间: |
|
| 查看次数: |
17228 次 |
| 最近记录: |