小编use*_*_12的帖子
如何在自定义数据集上微调超正方体?
我知道这个问题可能不是一个新问题,但训练/微调超正方体是最难的部分之一,我永远找不到任何可以正确解释它的文章。所有的教程或文档都没有人完整地解释它,浏览它们会提出更多的问题而不是答案。
所以我真的希望我能在几个方面得到一些澄清,如果可能的话,用外行的话来说。
{kind=link}
{kind=link}
{kind=link}
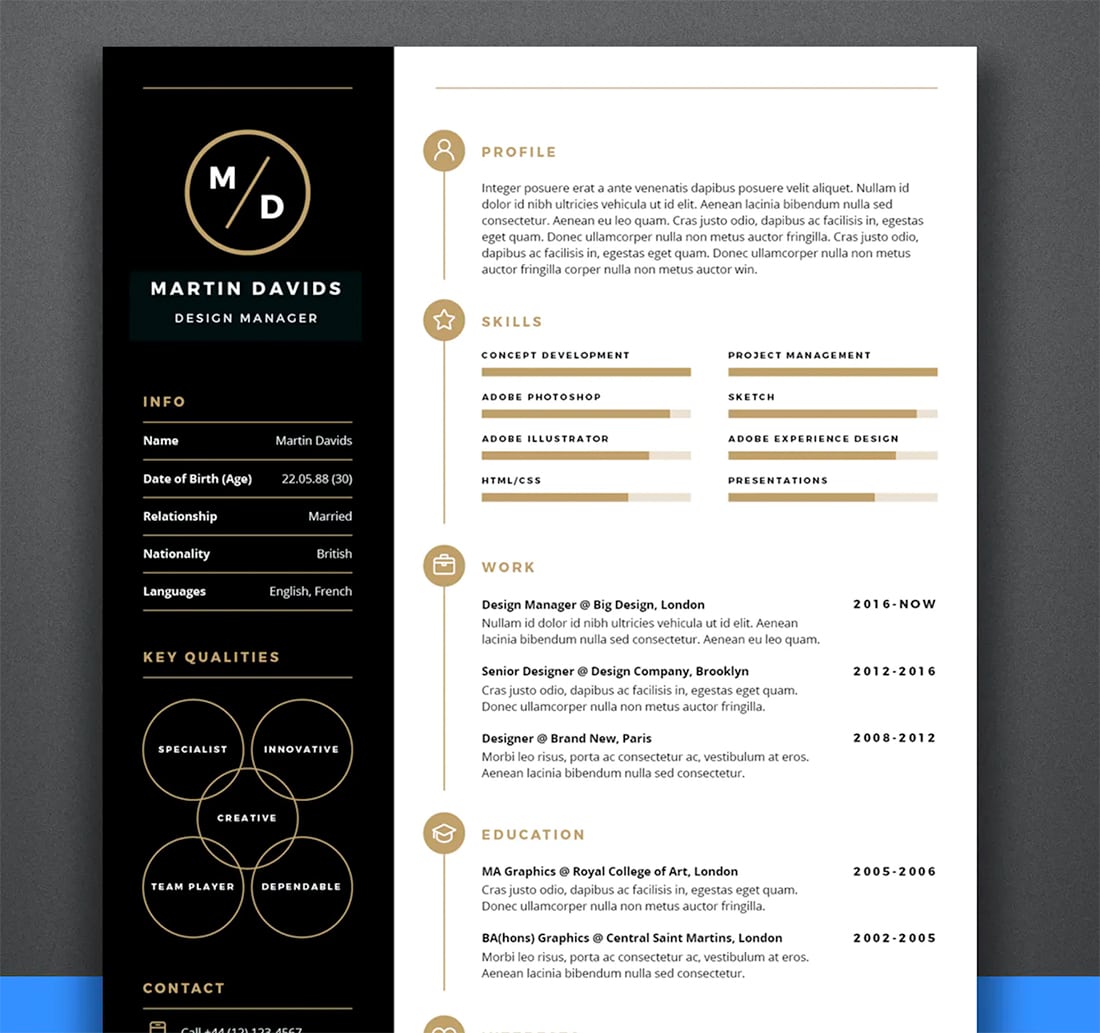
这些是一些复杂的简历,训练它们需要 tesseract 了解是否从左到右提取文本,特别是在两列简历中,它需要解析一列文本,然后解析另一列文本。
现在,我如何为此目的微调超正方体,因为在尝试时它没有正确解析它?
有人说我需要创建一个包含图像中每个字符坐标的框文件,一些文档说您需要一个图像文件和一个包含文本的同名文本文件?这里哪个是正确的格式?这比我这样的问题有优势。
现在,如果我需要获取每个字符坐标,我可以使用像 google Vision api 这样的在线 ocr 平台来生成此类数据,因为手动注释它们永远不是一件容易的任务。即使谷歌视觉 API 返回文本和每个字符边界坐标,它可能不是 tesseract 正在寻找的坐标?
另外,tesseract 是否可以解决我的问题,或者我是否需要构建一个单独的 ocr 模型(我可以利用的任何 github 链接或预训练模型)?
请对我的问题提供任何形式的帮助,我已经到处寻找答案几个星期了,但没有运气。请帮帮我。
编辑:期待更详细的答案。
推荐指数
解决办法
查看次数
如何正确设置基本的 traefik 反向代理?
假设我当前的公共 IP 是101.15.14.71,我有一个名为的域example.com,我使用 cloudflare 配置了该域,并且我创建了多个指向我的公共 ip 的 DNS 条目。
例如:
1) new1.example.com - 101.15.14.71
2) new2.example.com - 101.15.14.71
3) new3.example.com - 101.15.14.71
现在,这是我的示例项目结构,
??? myapp
? ??? app
? ? ??? main.py
? ??? docker-compose.yml
? ??? Dockerfile
??? myapp1
? ??? app
? ? ??? main.py
? ??? docker-compose.yml
? ??? Dockerfile
??? traefik
??? acme.json
??? docker-compose.yml
??? traefik_dynamic.toml
??? traefik.toml
这里我有两个 fastAPI(即 myapp、myapp1)
这是我在myapp 和 myapp1中的main.py中的示例代码,它完全相同,但返回 staement 不同,仅此而已
from fastapi import …推荐指数
解决办法
查看次数
如何在异步函数中并行化 for 循环并跟踪 for 循环执行状态?
最近,我问了一个关于如何在部署的 API 中跟踪 for 循环进度的问题。这是链接。
对我有用的解决方案代码是,
from fastapi import FastAPI, UploadFile
from typing import List
import asyncio
import uuid
context = {'jobs': {}}
app = FastAPI()
async def do_work(job_key, files=None):
iter_over = files if files else range(100)
for file, file_number in enumerate(iter_over):
jobs = context['jobs']
job_info = jobs[job_key]
job_info['iteration'] = file_number
job_info['status'] = 'inprogress'
await asyncio.sleep(1)
jobs[job_key]['status'] = 'done'
@app.get('/')
async def get_testing():
identifier = str(uuid.uuid4())
context['jobs'][identifier] = {}
asyncio.run_coroutine_threadsafe(do_work(identifier), loop=asyncio.get_running_loop())
return {"identifier": identifier}
@app.get('/status/{identifier}')
async …推荐指数
解决办法
查看次数
如何连接到 sqlite3 db 文件并在 fastapi 中获取内容?
我有一个 sqlite.db 文件,有 5 列和 1000 万行。我已经使用 fastapi 创建了一个 api,现在在其中一个 api 方法中我想连接到 sqlite.db 文件并根据某些条件(基于存在的列)获取内容。我主要会使用 SELECT 和 WHERE。
我怎样才能通过利用异步请求来做到这一点。我遇到过 Tortoise ORM,但我不知道如何正确使用它来获取结果。
from fastapi import FastAPI, UploadFile, File, Form
from fastapi.middleware.cors import CORSMiddleware
DATABASE_URL = "sqlite:///test.db"
@app.post("/test")
async def fetch_data(id: int):
query = "SELECT * FROM tablename WHERE ID={}".format(str(id))
# how can I fetch such query faster from 10 million records while taking advantage of async func
return results
推荐指数
解决办法
查看次数
如何将表情符号替换为文本中的单词?
想象一下我有这样的文字?
text = "game is on "
如何将文本中的表情符号转换为单词?
这是我尝试过的,下面的代码将表情符号转换为单词,但如何将其替换为原始文本中的表情符号。我想不通。
import emot
[emot.emoji(i).get('mean').replace(':','').replace('_',' ').replace('-',' ') for i in text.split()]
预期输出:
game is on fire fire
我遇到过这两个python模块
Emoji,
Emot但我不知道如何成功地将表情符号转换为文本并在文本句子中替换它。
任何人都可以帮忙吗?
推荐指数
解决办法
查看次数
如何将初始隐藏状态传递给 lstm 层?
我想将自定义初始状态传递给 lstm 输出,但我只有一个隐藏状态,因此如何传递零初始状态。
from tensorflow.keras import layers
x = layers.Input((None,))
x = layers.Embedding(....)(x)
x = layers.Flatten()(x)
imp_vec = Dense()(x)
现在我想使用 imp_vec 作为隐藏的初始状态并将其传递给解码器 lstm
out, states = layers.LSTM(...., return_state=True)(inputs, initial_state=[imp_vec])
上面的代码返回值错误:,
ValueError: An `initial_state` was passed that is not compatible with `cell.state_size`. Received `state_spec`=ListWrapper([InputSpec(shape=(None, 200), ndim=2)]); however `cell.state_size` is [10, 10]
我发现 lstm 需要两个状态作为初始状态(即 hidden_state、cell_state)对吗?但我只有一个隐藏状态向量将它传递给模型,所以我如何只初始化 hidden_state 并使 lstm 自动用零初始化另一个?
推荐指数
解决办法
查看次数
字典、json(转储、加载)、defaultdict 是否保留了 python 3.7 的顺序?
我一直认为字典是无序的,这意味着我们必须使用像 OrderedDict 这样的东西来让它记住插入顺序。
当我看到 python 文档时,有人提到从 python 3.7 dict 是订购的。
我对此几乎没有怀疑,
- 如果 dict 保留插入顺序,这是否意味着即使
defaultdict在集合中也会这样做? - 如果我有如下数据,那么 json.dumps 和 json.loads 功能如何使用 defaultdict 数据,
编辑:https : //docs.python.org/3/library/json.html (json 文档)
在 Python 3.7 之前,不能保证 dict 是有序的,因此输入和输出通常会被打乱,除非 collections.OrderedDict 被特别要求。从 Python 3.7 开始,常规 dict 成为顺序保留,因此不再需要为 JSON 生成和解析指定 collections.OrderedDict。
至于第二个疑问,我在 python json docs 中找到了上面的语句,但我想知道这是否适用于嵌套的 defaultdict 数据。
# example defaultdict data for 2 doubt.
from collections import defaultdict
data = defaultdict(dict)
data["0"]["a"] = "Google"
data["0"]["b"] = "Google"
data["0"]["c"] = "Google"
data["1"]["a"] = "Google"
data["1"]["b"] = …推荐指数
解决办法
查看次数
如何去歪斜文本图像也检索该图像的新边界框?
这是我得到的一张收据图像,我使用 matplotlib 绘制了它,如果您看到图像,其中的文本不是直的。我该如何去歪斜并修复它?
from skimage import io
import cv2
# x1, y1, x2, y2, x3, y3, x4, y4
bbox_coords = [[20, 68], [336, 68], [336, 100], [20, 100]]
image = io.imread('https://i.ibb.co/3WCsVBc/test.jpg')
gray = cv2.cvtColor(image, cv2.COLOR_RGB2GRAY)
fig, ax = plt.subplots(figsize=(20, 20))
ax.imshow(gray, cmap='Greys_r')
# for plotting bounding box uncomment the two lines below
#rect = Polygon(bbox_coords, fill=False, linewidth=1, edgecolor='r')
#ax.add_patch(rect)
plt.show()
print(gray.shape)
(847, 486)

我想如果我们想先去歪斜,我们必须找到边缘,所以我尝试使用精明算法找到边缘,然后得到如下所示的轮廓。
from skimage import filters, feature, measure
def edge_detector(image):
image = filters.gaussian(image, 2, mode='reflect')
edges = feature.canny(image) …推荐指数
解决办法
查看次数
如何将行分成 10 分钟的间隔?
假设这是我的示例数据:
ID datetime
0 2 2015-01-09 19:05:39
1 1 2015-01-10 20:33:38
2 1 2015-01-10 20:33:38
3 1 2015-01-10 20:45:39
4 1 2015-01-10 20:46:39
5 1 2015-01-10 20:46:59
6 1 2015-01-10 20:50:39
我想创建一个新列“BIN”,它告诉我们该行属于哪个 10 分钟的 bin。
即)选择最小日期时间并从那里开始。在此示例中,数据第一行是最短时间,但我的真实数据并非如此。我的真实数据没有排序。
ID datetime bin
0 2 2015-01-09 19:05:39 1
1 1 2015-01-10 20:33:38 2
2 1 2015-01-10 20:33:38 2
3 1 2015-01-10 20:45:39 3
4 1 2015-01-10 20:46:39 3
5 1 2015-01-10 20:46:59 3
6 1 2015-01-10 20:50:39 3
推荐指数
解决办法
查看次数
如何使用 predict_generator 对 Keras 中的未标记测试数据进行预测?
我正在尝试构建图像分类模型。这是一个 4 类图像分类。这是我用于构建图像生成器和运行训练的代码:
train_datagen = ImageDataGenerator(rescale=1./255.,
rotation_range=30,
horizontal_flip=True,
validation_split=0.1)
train_generator = image_gen.flow_from_directory(train_dir, target_size=(299, 299),
class_mode='categorical', batch_size=20,
subset='training')
validation_generator = image_gen.flow_from_directory(train_dir, target_size=(299, 299),
class_mode='categorical', batch_size=20,
subset='validation')
model.compile(Adam(learning_rate=0.001), loss='categorical_crossentropy',
metrics=['accuracy'])
model.fit_generator(train_generator, steps_per_epoch=int(440/20), epochs=20,
validation_data=validation_generator,
validation_steps=int(42/20))
我能够完美地进行训练和验证工作,因为训练目录中的图像存储在每个班级的单独文件夹中。但是,正如您在下面看到的,测试目录有 100 个图像,其中没有文件夹。它也没有任何标签,只包含图像文件。
如何使用 Keras对test文件夹中的图像文件进行预测?

推荐指数
解决办法
查看次数
如何根据if条件在for循环中跳过几次迭代?
我有一个 for 循环,我正在寻找一种方法,只要满足该条件就可以跳过几次迭代。我怎样才能在python中做到这一点?
这是第一次满足条件时的示例,
for i in range(0, 200000):
# (when 0 % 300 it meets this criteria)
if (i % 300) == 0:
# whenever this condition is met skip 4 iterations forward
# now skip 4 iterations --- > (0, 1, 2, 3)
# now continue from 4th iteration until the condition is met again
同样,只要满足条件,就会发生这种情况。
推荐指数
解决办法
查看次数
如果列表项在另一个列表中,如何在保持顺序的同时将列表项移到前面
我有两个示例列表,
vals = ["a", "c", "d", "e", "f", "g"]
xor = ["c", "g"]
我想vals根据xor列表对列表进行排序,即,中的值xor应按vals确切顺序排在列表的首位。中存在的其余值vals应保持相同的顺序。
此外,在这些情况下,值xor可能不在,vals只是忽略这些值。而且,在重复的情况下,我只需要一个值。
期望的输出:
vals = ["c", "g", "a", "d", "e", "f"]
# here a, d, e, f are not in xor so we keep them in same order as found in vals.
我的方法:
new_list = []
for x in vals:
for y in xor:
if x == y:
new_list.append(x)
for x in vals: …推荐指数
解决办法
查看次数
如何使用 mysql 连接器执行 .sql 文件并将其保存在 python 数据库中?
我有一个 .sql 文件,我想知道我们是否可以使用我的 mysql 社区提供的 mysql.connector python 类直接在 python 中执行它。
通常我可以使用这些查询在终端中执行 mysql 服务器中的 .sql 文件,
CREATE DATABASE test;
USE test;
source data.sql;
但我想直接用python来做。是否可以?
推荐指数
解决办法
查看次数
标签 统计
python ×11
python-3.x ×7
fastapi ×3
tensorflow ×2
docker ×1
joblib ×1
keras ×1
lstm ×1
mysql ×1
ocr ×1
opencv ×1
pandas ×1
scikit-image ×1
tess4j ×1
tesseract ×1
tesseract.js ×1
traefik ×1