编辑:鉴于粒子被分割成网格单元(比如16^3网格),让每个网格单元运行一个工作组和一个工作组中的多个工作项是一个更好的想法,因为可以有最大数量的每格网格的粒子?
在这种情况下,我可以将相邻单元格中的所有粒子加载到本地内存中,并通过它们迭代计算一些属性.然后我可以将特定值写入当前网格单元格中的每个粒子.
这种方法是否有利于为所有粒子运行内核以及每次迭代(大多数时间是相同的)邻居?
另外,理想的比例是number of particles/number of grid cells多少?
我正在尝试为OpenCL 重新实现(和修改)CUDA Particles,并使用它来查询每个粒子的最近邻居.我创建了以下结构:
P保持所有粒子的3D位置(float3)缓冲Sp存储int2粒子id对及其空间哈希值.Sp根据哈希值排序.(哈希只是从3D到1D的简单线性映射 - 还没有Z-indexing.)
缓冲区L存储缓冲区int2中特定空间哈希值的起始和结束位置对Sp.示例:L[12] = (int2)(0, 50).
L[12].x是具有空间散列Sp的第一个粒子的索引(in )12.L[12].y是具有空间散列Sp的最后一个粒子的索引(in )12.现在我拥有了所有这些缓冲区,我想迭代遍历所有粒子P并为每个粒子迭代它们最近的邻居.目前我有一个看起来像这样的内核(伪代码):
__kernel process_particles(float3* P, int2* Sp, int2* L, int* …(如何)我可以在 Metal 中同时运行多个计算内核(我不一定需要它们同时并行运行,并发执行就足够了)?
MTLCommandBuffer2 个不同的 s(在同一设备上)中的sMTLCommandQueue是否同时执行(即队列的行为是否像 CUDA 流?)?
注意:我无法进一步将内核拆分为更小的子内核。
我需要强制 Metal 编译器在我的内核计算函数中展开一个循环。到目前为止,我已经尝试放在循环#pragma unroll(num_times)之前for,但编译器忽略了该语句。
似乎编译器不会自动展开循环——我比较了 1) 带有for循环的代码2) 相同代码但带有手动展开循环的执行时间。手动展开的版本快了 3 倍。
例如:我想从这个开始:
for (int i=0; i<3; i++) {
do_stuff();
}
对此:
do_stuff();
do_stuff();
do_stuff();
在 Metal C++ 语言中甚至有类似循环展开的东西吗?如果是,我怎么可能让编译器知道我想展开一个循环?
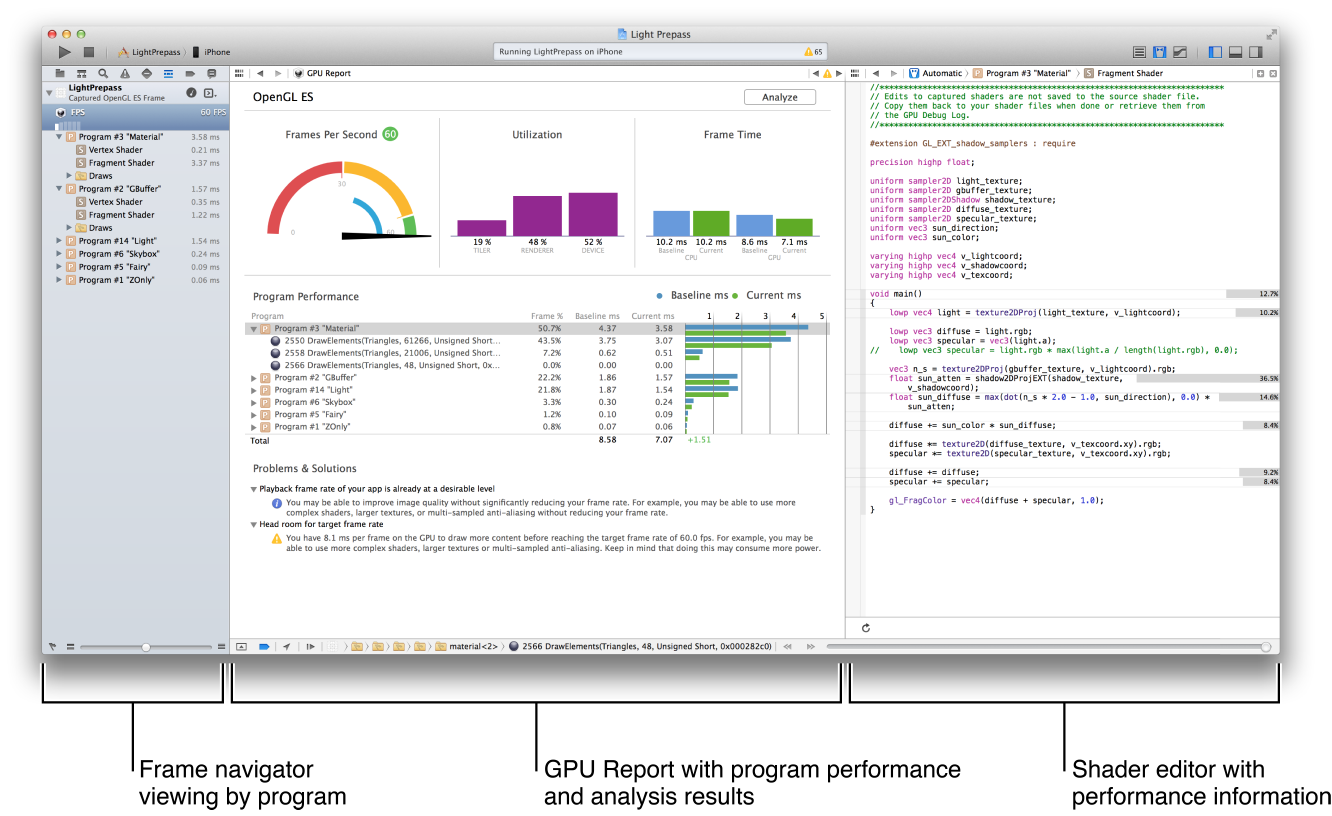
我正在尝试通过捕获 GPU 帧来分析 Metal 内核。在具有 Metal runloop 的应用程序中,我会单击调试区域中的“相机按钮”,但是每个应用程序生命周期我只调度内核一次,因此我无法单击“相机按钮”(它保持灰色)。
\n\n因此,我尝试通过在第一次调用之前使用“捕获 GPU 帧”操作设置断点来解决此问题mQueue.insertDebugCaptureBoundary()(请参阅下面的代码)。
我期望发生的事情是这样的\ xe2\x80\x93 ,即每个内核函数的执行持续时间的概述,以及执行各行内核函数所花费的时间百分比。
\n\n实际发生的情况是:我很少得到所描述的预期分析概述。大多数时候(大约 95% 的时间)我没有得到这样的分析概述,而是在构建并运行应用程序后发生以下情况之一:
\n\n下面的代码显示了我的问题的简化示例(如果您想知道;不,我在 ViewController 中没有计算逻辑 - 下面的代码只是一个玩具示例;))。
\n\nclass ViewController : UIViewController { \n // initialize Metal, create buffers, etc. \n\n override func viewDidLoad() { \n tick() …问题:
我需要补MTLBuffer的Float具有恒定值s -比方说1729.68921。我还需要尽快。
因此,禁止我填充CPU端的缓冲区(即UnsafeMutablePointer<Float>从MTLBuffer并以串行方式分配)。
我的方法
理想情况下,我会使用MTLBlitCommandEncoder.fill(),但是AFAIK只能用UInt8值填充缓冲区(假定UInt8长度为1字节,长度Float为4字节,我不能指定Float常量的任意值)。
到目前为止,我只能看到2个选项,但这两个选项似乎都太过分了:
B填充有常量值的缓冲区,然后通过以下方式将其内容复制到我的缓冲区中MTLBlitCommandEncoderkernel将填充缓冲区的函数问题
什么是填充的最快方法MTLBuffer的Float具有恒定值s?
{kind=link}
{kind=link}
{kind=link}
{kind=link}