这就是我问这个问题的原因: 去年我制作了一些C++代码来计算特定类型模型的后验概率(由贝叶斯网络描述).该模型工作得很好,其他一些人开始使用我的软件.现在我想改进我的模型.由于我已经为新模型编写了略微不同的推理算法,因此我决定使用python,因为运行时并不重要,python可以让我制作更优雅和易于管理的代码.
通常在这种情况下我会在python中搜索现有的贝叶斯网络包,但我正在使用的推理算法是我自己的,我也认为这将是一个很好的机会,可以在python中学习更多有关优秀设计的知识.
我已经为网络图(networkx)找到了一个很棒的python模块,它允许你将字典附加到每个节点和每个边缘.从本质上讲,这将让我给出节点和边缘属性.
对于特定网络及其观察数据,我需要编写一个函数来计算模型中未分配变量的可能性.
例如,在经典的"亚洲"网络(http://www.bayesserver.com/Resources/Images/AsiaNetwork.png)中,以"XRay Result"和"Dyspnea"状态着称,我需要编写一个函数计算其他变量具有某些值的可能性(根据某些模型).
这是我的编程问题: 我将尝试一些模型,将来我可能会想要尝试另一种模型.例如,一个模型看起来可能与亚洲网络完全一样.在另一个模型中,可以从"访问亚洲"到"有肺癌"添加有针对性的边缘.另一个模型可能使用原始有向图,但给定"肺结核或癌症"和"支气管炎"节点的"呼吸困难"节点的概率模型可能不同.所有这些模型都将以不同的方式计算可能性.
所有模型都会有很大的重叠; 例如,如果所有输入都为"0",则进入"或"节点的多个边将始终为"0",否则为"1".但是一些模型将具有在某个范围内采用整数值的节点,而其他模型将是布尔值.
在过去,我一直在努力解决如何编程这样的事情.我不会撒谎; 有相当数量的复制和粘贴代码,有时我需要将单个方法中的更改传播到多个文件.这次我真的想花时间以正确的方式做到这一点.
一些选择:
非常感谢你的帮助.
Update: Object oriented ideas help a lot here (each node has a designated set of predecessor nodes of a certain node subtype, and each node has a likelihood function that computes its likelihood of different outcome states given the states of the predecessor nodes, etc.). OOP FTW!
我曾经使用过系统监视器应用程序中内置的漂亮的Apple探查器.只要您的C++代码是使用调试信息编译的,您就可以对正在运行的应用程序进行采样,并打印出一个缩进的树,告诉您父函数在此函数中花费的时间百分比(以及正文与其他函数调用) .
例如,如果main调用function_1and function_2,function_2调用function_3,然后是main调用function_3:
main (100%, 1% in function body):
function_1 (9%, 9% in function body):
function_2 (90%, 85% in function body):
function_3 (100%, 100% in function body)
function_3 (1%, 1% in function body)
我会看到这一点,然后想一想,"有些东西需要花费很长时间function_2才能完成代码.如果我希望我的程序更快,那就是我应该开始的地方."
我怎样才能最轻松地获得Python程序的精确分析输出?
我见过有人说这样做:
import cProfile, pstats
prof = cProfile.Profile()
prof = prof.runctx("real_main(argv)", globals(), locals())
stats = pstats.Stats(prof)
stats.sort_stats("time") # Or cumulative
stats.print_stats(80) # 80 = how many to print
但与优雅的呼叫树相比,它相当混乱.如果你能轻易做到这一点,请告诉我,这会有所帮助.
如果我有std::tuple<double, double, double>(类型是同类的),是否有转换为的股票函数或构造函数std::array<double>?
编辑::我能够使用递归模板代码(我在下面发布的草稿答案).这是处理这个问题的最佳方法吗?这似乎会有一个库存函数......或者如果你对我的答案有所改进,我会很感激.我会留下未回答的问题(毕竟,我想要一个好方法,而不仅仅是一种可行的方式),并且更愿意选择别人的[希望更好]答案.
谢谢你的建议.
今天,我决定把基准和比较的GCC可优化一些分歧std::vector和std::array.通常,我发现了我的预期:在每个短数组上执行任务比在集合等效向量上执行任务要快得多.
但是,我发现了一些意想不到的事情:std::vector用于存储数组集合比使用更快std::array.为了防止它是堆栈上大量数据的一些工件的结果,我还尝试将它作为一个数组分配在堆上和堆上的C风格数组中(但结果仍然类似于一个数组堆栈上的数组和数组的向量).
任何想法,为什么std::vector会永远跑赢大盘std::array(上编译器有更多的编译时间信息)?
我编译使用gcc-4.7 -std=c++11 -O3(gcc-4.6 -std=c++0x -O3也应该导致这个难题).使用bash-native time命令(用户时间)计算运行时.
码:
#include <array>
#include <vector>
#include <iostream>
#include <assert.h>
#include <algorithm>
template <typename VEC>
double fast_sq_dist(const VEC & lhs, const VEC & rhs) {
assert(lhs.size() == rhs.size());
double result = 0.0;
for (int k=0; k<lhs.size(); ++k) {
double tmp = lhs[k] - rhs[k];
result += tmp * …我最近碰到了这个难题,终于能够解决一个hacky的答案(使用索引数组),并想分享它(下面的答案).我确信有些答案使用模板递归和使用的答案boost; 如果您有兴趣,请分享其他方法来做到这一点.我认为将这些全部放在一个地方可能会让其他人受益,并且对于学习一些很酷的C++ 11模板元编程技巧很有用.
问题: 给出两个长度相等的元组:
auto tup1 = std::make_tuple(1, 'b', -10);
auto tup2 = std::make_tuple(2.5, 2, std::string("even strings?!"));
你如何创建一个将两个元组"压缩"成异构元组的函数?
std::tuple<
std::pair<int, double>,
std::pair<char, int>,
std::pair<int, std::string> > result =
tuple_zip( tup1, tup2 );
哪里
std::get<0>(result) == std::make_pair(1, 2.5);
std::get<1>(result) == std::make_pair('b', 2);
std::get<2>(result) == std::make_pair(-10, std::string("even strings?!"));
我有一些代码来迭代(多变量)数值范围:
#include <array>
#include <limits>
#include <iostream>
#include <iterator>
template <int N>
class NumericRange : public std::iterator<double, std::input_iterator_tag>
{
public:
NumericRange() {
_lower.fill(std::numeric_limits<double>::quiet_NaN());
_upper.fill(std::numeric_limits<double>::quiet_NaN());
_delta.fill(std::numeric_limits<double>::quiet_NaN());
}
NumericRange(const std::array<double, N> & lower, const std::array<double, N> & upper, const std::array<double, N> & delta):
_lower(lower), _upper(upper), _delta(delta) {
_state.fill(std::numeric_limits<double>::quiet_NaN());
}
const std::array<double, N> & get_state() const {
return _state;
}
NumericRange<N> begin() const {
NumericRange<N> result = *this;
result.start();
return result;
}
NumericRange<N> end() const {
NumericRange<N> result = *this;
result._state = _upper; …这个问题类似,但是关于从类中调用函数:如果我重写它,我可以调用基类的虚函数吗?
在这种情况下,您将指定Base::function()而不是function(),将调用重写的定义.
但是有没有办法在课外做到这一点?我的类没有定义复制构造函数,所以我无法弄清楚如何作为基类进行转换:
Base( derived_object ).function()
是适当的事情在这里施展& derived_object作为Base*,然后调用->function()?
感谢您的见解.
我正在使用matplotlib在python中渲染一些图形,并将它们包含在LaTeX文件中(使用LaTex的漂亮表格对齐而不是摆弄matplotlib ImageGrid等).我想创建并保存一个独立的颜色条savefig,而无需使用imshow.
(vlim, vmax参数,以及cmap可以明确提供)
我能找到的唯一方法是相当复杂的(根据我的理解)在画布上绘制一个硬编码的矩形:http: //matplotlib.org/examples/api/colorbar_only.html
有没有一种优雅的方法来创建一个matplotlib独立颜色条?
我正在使用NetworkX使用python进行图形模型项目.NetworkX使用词典提供简单而好的功能:
import networkx as nx
G = nx.DiGraph() # a directed graph
G.add_edge('a', 'b')
print G['a'] # prints {'b': {}}
print G['b'] # prints {}
我想使用有向图,因为我正在编写具有方向的依赖项(在上面的例子中,我有'b'的封闭形式,条件是'a',而不是相反).
对于给定节点,我想找到该节点的前驱.对于上面的例子,par('b')应该返回['a'].NetworkX确实有一个后继函数,它可以找到任何节点的子节点.显然,通过遍历所有节点并找到那些具有"b"作为子节点的节点将起作用,但节点数量将是Ω(n)(这对于我的应用来说太昂贵了).
我无法想象这个简单的东西会被遗漏在这个制作精良的包装中,但找不到任何东西.
一个有效的选择是存储图的有向和无向版本; 所有无向边缘基本上都是通过添加两个有向边来实现的,因此可以采用相邻节点和子节点(它们是前一个节点)之间的设置差异.
麻烦的是我不确定包装现有的networkx DiGraph和Graph类来实现这一目标的最pythonic方法.真的,我只想得到一个类PGraph,它的行为与networkx DiGraph类完全相同,但predecessors(node)除了函数之外还有一个successors(node)函数.
PGraph应该继承DiGraph并封装Graph(用于前辈函数)吗?那么我应该如何强制将所有节点和边缘添加到它包含的有向图和无向图中?我是否应该重新实现在PGraph中添加和删除节点和边缘的功能(以便在有向和无向版本中添加和删除它们)?我担心,如果我想念一些不为人知的东西,我会在以后头疼,这可能并不意味着好的设计.
或者(并且请让它成为True)有一个简单的方法来获取nodex.DiGraph中的节点的前辈,我完全错过了它?
非常感谢你的帮助.
编辑:
我认为这样做了.PGraph继承自DiGraph,并封装了另一个DiGraph(这个反转).我已经覆盖了添加和删除节点和边缘的方法.
import networkx as nx
class PGraph(nx.DiGraph):
def __init__(self):
nx.DiGraph.__init__(self)
self.reversed_graph = nx.DiGraph()
def add_node(self, n, attr_dict=None, **attr):
nx.DiGraph.add_node(self, n, attr_dict, **attr)
self.reversed_graph.add_node(n, attr_dict, **attr)
def add_nodes_from(self, ns, attr_dict=None, **attr):
nx.DiGraph.add_nodes_from(self, ns, attr_dict, **attr)
self.reversed_graph.add_nodes_from(ns, …我有两套串(中A和B),我想知道的所有字符串对a in A,并b in B在那里a是一个子b.
对此进行编码的第一步如下:
for a in A:
for b in B:
if a in b:
print (a,b)
但是,我想知道 - 使用正则表达式是否有更有效的方法(例如,而不是检查if a in b:,检查正则表达式是否'.*' + a + '.*':匹配'b'.我认为可能使用这样的东西会让我缓存Knuth-莫里斯-普拉特对所有故障的功能a.此外,使用列表理解为内for b in B:循环可能会给出一个相当大的加速(和嵌套列表理解可能会更好).
我对这个算法的渐近运行时间的巨大飞跃并不感兴趣(例如使用后缀树或其他复杂而聪明的东西).我更关心常量(我只需要为几对A和B集合做这个,我不希望它一整周都运行).
您是否知道任何技巧或有任何通用建议来更快地完成此操作?非常感谢您分享的任何见解!
编辑:
使用@ninjagecko和@Sven Marnach的建议,我构建了一个10-mer的快速前缀表:
import collections
prefix_table = collections.defaultdict(set)
for k, b in enumerate(B):
for i in xrange(len(prot_seq)-10):
j …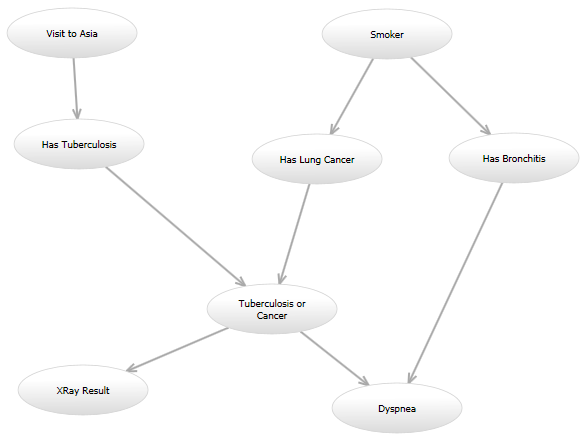{kind=link}