小编got*_*nes的帖子
有关使用C扩展或Cython优化非平凡Python应用程序的教程
Python社区发布了有用的参考资料,展示了如何分析Python代码,以及C或Cython中Python扩展的技术细节.我仍在搜索教程,但是,对于非平凡的Python程序,显示如下:
- 如何通过转换为C扩展来识别将从优化中受益的热点
- 同样重要的是,如何识别不会从转换为C扩展中受益的热点
- 最后,如何使用Python C-API或(甚至可能更好)使用Cython进行从Python到C的适当转换.
一个好的教程将为读者提供一种方法,通过完成一个完整的例子来说明如何推理优化问题.我没有成功找到这样的资源.
你知道(或有你写过)这样的教程吗?
为了澄清,我对仅涵盖以下内容的教程不感兴趣:
- 使用(c)Profile来分析Python代码以测量运行时间
- 使用工具检查配置文件(我推荐RunSnakeRun)
- 通过选择更合适的算法或Python构造进行优化(例如,用于成员资格测试而不是列表的集合); 本教程应该假设算法和Python代码已经是最优的,并且我们处于C扩展是下一个逻辑步骤的位置
- 重新编写关于编写C扩展的Python文档,这已经很好地作为参考,但作为显示何时以及如何从Python移动到C的资源无用.
推荐指数
解决办法
查看次数
在matplotlib中创建方形子图(高度和宽度相等)
当我运行此代码时
from pylab import *
figure()
ax1 = subplot(121)
plot([1, 2, 3], [1, 2, 3])
subplot(122, sharex=ax1, sharey=ax1)
plot([1, 2, 3], [1, 2, 3])
draw()
show()
我得到两个在X维度上"压扁"的子图.对于两个子图,如何获得这些子图,使得Y轴的高度等于X轴的宽度?
我在Ubuntu 10.04上使用matplotlib v.0.99.1.2.
更新2010-07-08:让我们看看一些不起作用的东西.
谷歌搜索了一整天后,我认为它可能与自动缩放有关.所以我试着摆弄它.
from pylab import *
figure()
ax1 = subplot(121, autoscale_on=False)
plot([1, 2, 3], [1, 2, 3])
subplot(122, sharex=ax1, sharey=ax1)
plot([1, 2, 3], [1, 2, 3])
draw()
show()
matplotlib坚持自动缩放.
from pylab import *
figure()
ax1 = subplot(121, autoscale_on=False)
plot([1, 2, 3], [1, 2, 3])
subplot(122, sharex=ax1, sharey=ax1, autoscale_on=False)
plot([1, …推荐指数
解决办法
查看次数
matplotlib matshow标签
我一个月前开始使用matplotlib,所以我还在学习.
我正在尝试用matshow做热图.我的代码如下:
data = numpy.array(a).reshape(4, 4)
cax = ax.matshow(data, interpolation='nearest', cmap=cm.get_cmap('PuBu'), norm=LogNorm())
cbar = fig.colorbar(cax)
ax.set_xticklabels(alpha)
ax.set_yticklabels(alpha)
其中alpha是django中带有4个字段的模型:'ABC','DEF','GHI','JKL'
事情是,我不知道为什么,标签'ABC'没有出现,留下最后一个没有标签的单元格.
如果有人想知道如何修改我的脚本以显示'ABC'的方式我将不胜感激:)
推荐指数
解决办法
查看次数
OS X终端中Python解释器的Tab-completion
几个月前,我写了一篇博客文章,详细介绍了如何在标准的Python交互式解释器中实现tab-completion - 这个功能我曾经认为只在IPython中可用.由于IPython unicode问题,我有时不得不切换到标准解释器,因此我发现它非常方便.
最近我在OS X中做了一些工作.令我不满的是,脚本似乎不适用于OS X的终端应用程序.我希望你们中的一些有OS X经验的人可以帮助我解决问题,这样它也可以在终端中运行.
我正在复制下面的代码
import atexit
import os.path
try:
import readline
except ImportError:
pass
else:
import rlcompleter
class IrlCompleter(rlcompleter.Completer):
"""
This class enables a "tab" insertion if there's no text for
completion.
The default "tab" is four spaces. You can initialize with '\t' as
the tab if you wish to use a genuine tab.
"""
def __init__(self, tab=' '):
self.tab = tab
rlcompleter.Completer.__init__(self)
def complete(self, text, state):
if text == '':
readline.insert_text(self.tab)
return …推荐指数
解决办法
查看次数
在使用Sphinx文档时,我应该告诉VCS忽略哪些文件?
我想开始使用Sphinx记录我的项目.我告诉Sphinx在使用过程中使用单独的源代码和构建目录sphinx-quickstart.现在我的目录布局如下:
MyProject/
myproject/
__init__.py
mymodule.py
docs/
source/
.static/
.templates/
conf.py
index.rst
build/
Makefile
应该从Sphinx项目的VCS存储库中排除哪些文件(即,因为我使用Git,我应该将什么添加到我的.gitignore文件中)?例如,我是否应该忽略该docs/build/目录,以便不跟踪从Sphinx生成的HTML页面中的更改?
推荐指数
解决办法
查看次数
SQLAlchemy中Query的单元测试
如何在SQLAlchemy中测试查询?例如,假设我们有这个models.py
from sqlalchemy import (
Column,
Integer,
String,
)
from sqlalchemy.ext.declarative import declarative_base
Base = declarative_base()
class Panel(Base):
__tablename__ = 'Panels'
id = Column(Integer, primary_key=True)
category = Column(Integer, nullable=False)
platform = Column(String, nullable=False)
region = Column(String, nullable=False)
def __init__(self, category, platform, region):
self.category = category
self.platform = platform
self.region = region
def __repr__(self):
return (
"<Panel('{self.category}', '{self.platform}', "
"'{self.region}')>".format(self=self)
)
还有这个 tests.py
import unittest
from sqlalchemy import create_engine
from sqlalchemy.orm import sessionmaker
from models import Base, Panel
class TestQuery(unittest.TestCase): …推荐指数
解决办法
查看次数
C/C++与Python标准库的等价物
我在很大程度上取决于Python的标准库,既为有用的数据结构和操纵(例如,collections和itertools)和公用事业(如optparse,json和logging),跳过样板,只是把工作的事情.通过关于C++标准库的文档,它似乎完全与数据结构有关,而在Python的标准库中几乎没有"包含电池"的方式.
Boost库是我所知道的唯一类似于Python标准库的开源C++库集合,但是它确实有实用程序库,例如正则表达式支持,其中大部分也专用于数据结构.令我感到非常惊讶的是,即使是确保解析和编写CSV文件这样简单的事情,使用Python csv模块变得非常简单,看起来需要在C++中自己滚动(即使你利用Boost的一些解析库).
是否有其他开源库可供C++提供"电池"?如果没有,你作为一个C++程序员做什么:寻找个人实用程序库(如果是这样,如何),或者只是自己动手(这看起来很烦人和浪费)?
推荐指数
解决办法
查看次数
访问了模拟实例上的断言属性
如何断言a Mock和/或a 上的属性MagicMock被访问?
例如,
from unittest.mock import MagicMock
def foo(x):
a = x.value
m = MagicMock()
foo(m)
m.attr_accessed('value') # method that does not exist but I wish did; should return True
检查foo试图访问的实际方法是什么m.value?
推荐指数
解决办法
查看次数
urllib2没有检索整个HTTP响应
我很困惑,为什么我无法使用urllib2从FriendFeed下载一些JSON响应的全部内容.
>>> import urllib2
>>> stream = urllib2.urlopen('http://friendfeed.com/api/room/the-life-scientists/profile?format=json')
>>> stream.headers['content-length']
'168928'
>>> data = stream.read()
>>> len(data)
61058
>>> # We can see here that I did not retrieve the full JSON
... # given that the stream doesn't end with a closing }
...
>>> data[-40:]
'ce2-003048343a40","name":"Vincent Racani'
如何使用urllib2检索完整响应?
推荐指数
解决办法
查看次数
在等式中将LaTeX分数项排版更大
基于Fisher精确检验,我在LaTeX中有以下公式.(注意:需要使用amsmath包\binom.)
\begin{equation}
P(i,j) = \sum_{x=|N(V_i) \cap V_j|}^{\min\{|V_j|, |N(V_i)|}
\frac{ \binom{|V_j|}{x} \binom{|V - V_j|}{|N(V_i)| - x}}
{\binom{|V|}{|N(V_i)|}}
\end{equation}
这使得小数部分呈现非常小的,难以阅读的文本:
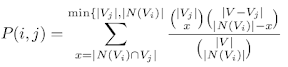
我希望我的文本更具可读性,如下例所示:
我可以使用什么技巧让LaTeX同样渲染我的方程式?
推荐指数
解决办法
查看次数
标签 统计
python ×9
matplotlib ×2
unit-testing ×2
c ×1
c++ ×1
cython ×1
django ×1
equation ×1
formula ×1
git ×1
http ×1
interpreter ×1
labels ×1
latex ×1
macos ×1
mocking ×1
optimization ×1
sqlalchemy ×1
urllib2 ×1