小编eva*_*rix的帖子
Java Regex中matches()和find()之间的区别
根据Javadoc(根据我的理解),matches()即使它找到了它正在寻找的东西,它也会搜索整个字符串,并find()在它找到它所寻找的内容时停止.
如果这个假设是正确matches()的find(),除非你想要计算它找到的匹配数,否则我无法看到你想要使用的代替.
在我看来,String类应该具有find()而不是matches()作为内置方法.
总结一下:
- 我的假设是否正确?
- 何时使用
matches()而不是find()?
推荐指数
解决办法
查看次数
混淆Python代码?
我正在寻找如何隐藏我的Python源代码.
print "Hello World!"
我如何编码这个例子,以便它不是人类可读的?我被告知使用base64,但我不知道如何.
推荐指数
解决办法
查看次数
如何增加DOSBox窗口的大小?
我在Ubuntu 12.04上的DOSBox上运行Turbo C.
问题是两个黑色条纹都出现在屏幕上.我想删除它们.
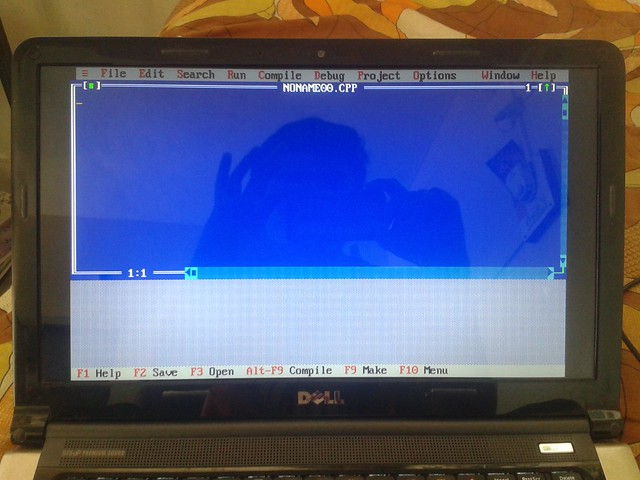
我的电脑是戴尔Studio 15z,屏幕分辨率为1366x768.即使发生扭曲,我也没有问题.
我的dosbox.conf文件的相关部分:
[sdl]
fullscreen=true
fulldouble=false
fullresolution=1366x768
windowresolution=1366x768
output=overlay
autolock=true
sensitivity=100
waitonerror=true
priority=higher,normal
mapperfile=mapper-0.74.map
usescancodes=true
推荐指数
解决办法
查看次数
Python PIL字节到图像
import PIL
from PIL import Image
from PIL import ImageDraw
from PIL import ImageFont
import urllib.request
with urllib.request.urlopen('http://pastebin.ca/raw/2311595') as in_file:
hex_data = in_file.read()
print(hex_data)
img = Image.frombuffer('RGB', (320,240), hex_data) #i have tried fromstring
draw = ImageDraw.Draw(img)
font = ImageFont.truetype("arial.ttf",14)
draw.text((0, 220),"This is a test11",(255,255,0),font=font)
draw = ImageDraw.Draw(img)
img.save("a_test.jpg")
即时尝试将二进制转换为图像,然后绘制文本.但我得到错误:
img = Image.frombuffer('RGB', (320,240), hex_data)
raise ValueError("not enough image data")
ValueError: not enough image data
我已经在这里http://pastebin.ca/raw/2311595上传了字节字符串,
图片大小我可以肯定是320x240
额外
这里是我可以肯定的图片字节字符串是来自320x240,只需运行代码就会从字节字符串中创建一个图像
import urllib.request
import binascii
import struct
# Download the data. …推荐指数
解决办法
查看次数
什么是Mongoose(Nodejs)复数规则?
我是Node.js,Mongoose和Expressjs的新手.我试图通过以下代码在MongoDB中使用Mongoose创建一个表"feedbackdata".但它被创建为"feedbackdata*s*".通过谷歌搜索,我发现Mongoose使用复数规则.有人请帮我删除复数规则吗?或者我的代码应该如何用于"feedbackdata"表?
以下是我的代码:
app.post("/save",function(req,res){
mongoose.connect('mongodb://localhost/profiledb');
mongoose.connection.on("open", function(){
console.log("mongo connected \n");
});
// defining schemar variables
Schema = mongoose.Schema,
ObjectId = Schema.ObjectId;
// define schema for the feedbackdata table
var feedback_schema = new Schema({
_id: String,
url:String,
username:String,
email:String,
subscribe:String,
types:String,
created_date: { type: Date, default: Date.now },
comments: String
});
// accessing feeback model object
var feedback_table = mongoose.model('feedbackdata', feedback_schema);
var tableObj = new feedback_table();
var URL = req.param('url');
var name = req.param('name');
var email = req.param('email');
var subscribe …推荐指数
解决办法
查看次数
如何在lua中找出对象的所有属性?
有没有办法获得对象的所有非零参数/属性?我发现了这个:getmetadata(self.xxxx)我正在寻找类似的东西:getalldata(self).
我目前正在开展一个涉及lua的项目.不幸的是,没有完整的参考,我必须使用预编译的东西.
我希望你能理解我想说的话.
推荐指数
解决办法
查看次数
在python中排序并获取uniq文件行
我总是使用这个命令行来排序并获得uniq行,即使有大文件(超过500,000行)它也可以作为魅力
sort filename.txt | uniq | sponge filename.txt
最短的等效python代码
f = open("filename.txt", "r")
lines = [line for line in f]
lines = lines.sort()
lines = set(lines)
但当然这是不可扩展的,因为内存约束和在python中编写可伸缩代码需要时间,所以我想知道什么是python中最短的等效代码(包)
推荐指数
解决办法
查看次数
下载Google幻灯片演示文稿(发布到网络上)
我想以PDF格式下载此链接:
不幸的是,这个URL使用我认可并可以操作的非标准格式.
将其修改为类似的东西
不起作用.
Google云端硬盘文件ID应为44个字母数字字符,但显然这长度为86个字符.
任何人都可以帮忙解释这是什么格式?
推荐指数
解决办法
查看次数
访问obb扩展文件中的文件
我正在关注所有官方扩展文件指南,但我找不到它.我无法访问我需要的包含的obb文件.
我需要6个音频文件(80Mb),我在zip文件中"存储"(未压缩)并重命名为"main.2001.test.expansion.proj.obb"并存储在'/ mnt/sdcard/Android/obb/test中.expansion.proj /"
我会尝试访问这些文件
String mainFileName = Helpers.getExpansionAPKFileName(this,true,2001);
if(!Helpers.doesFileExist(this, mainFileName, 27959282L, false))
{
//download
} else {
Log.d("test_file","file exist");
}
ZipResourceFile expansionFile = APKExpansionSupport.getAPKExpansionZipFile(this,2001,2001);
if(expansionFile!=null)
{
ZipEntryRO[] ziro = expansionFile.getAllEntries();
for (ZipEntryRO entry : ziro) {
Log.d("test_files_zip", "fileZip filename: "+entry.getZipFileName());
try{
AssetFileDescriptor ro = entry.getAssetFileDescriptor();
Log.d("test_files_zip", "--fileZip getfiledescriptor.tostring: "+ro.getFileDescriptor().toString());
Log.d("test_files_zip", "--fileZip createinputstring.tostring: "+ro.createInputStream().toString());
AssetFileDescriptor assetFileDescriptor = expansionFile.getAssetFileDescriptor(entry.getZipFileName()+"/audio02.mp3");
if(assetFileDescriptor!=null) {
Log.d("test_files_mp3", "length: "+assetFileDescriptor.getLength()); //checking it exists
}
}catch (IOException e){ Log.e("test_exp","IoExcp: "+e.getMessage()); }
}
}
In - > assetFileDescriptor = …
推荐指数
解决办法
查看次数
无法安装nvidia驱动程序,在函数'block_cpu_fault_locked'中:错误隐式声明函数'task_stack_page
我试图在计算机崩溃后在台式计算机上重新安装Ubuntu和NVIDIA驱动程序.但崩溃后NVIDIA驱动程序无法成功安装.第一个问题是Ubuntu usb安装后计算机进入低分辨率模式,要求我"重新启动"计算机.我遇到的第二个问题是按ctrl-alt-F1切换到文本命令模式后屏幕变为黑屏.我学会了通过编辑解决黑屏文本命令模式 /etc/default/grub,并将'nomodeset'添加到GRUB_CMDLINE_LINUX_DEFAULT变量并重新启动计算机.
然后我下载https://us.download.nvidia.com/XFree86/Linux-x86_64/384.130/NVIDIA-Linux-x86_64-384.130.run 并安装此NVIDIA驱动程序.但由于以下错误导致安装失败:
/tmp/selfgz1982/NVIDIA-Linux-x86_64-384.130/krenel/nvidia-uvm/uvm8_va_block.c:在函数'block_cpu_fault_locked'中:
./ arch/x86/inlcude/asm/process.h:820:39:错误隐式声明函数'task_stack_page'[-Werror = implicit-function-declaration]
unsigned long __ptr =(unsigned long)task_stack_page(task);
显卡坏了吗?
nvidia驱动器在崩溃时是否会更改母偏置或显卡设置?
Ubuntu安装可以完成安装并显示出很好的分辨率.
我有什么建议可以解决它吗?
推荐指数
解决办法
查看次数