标签: sorting-network
最快的固定长度6 int数组
回答另一个Stack Overflow问题(这个)我偶然发现了一个有趣的子问题.排序6个整数数组的最快方法是什么?
由于问题是非常低的水平:
- 我们不能假设库可用(并且调用本身有它的成本),只有普通的C.
- 避免排空指令流水线(具有非常高的成本),我们也许应该尽量减少分支机构,跳跃,和所有其他类型的控制流断裂的(像那些隐藏在背后的序列点
&&或||). - 房间受限制,最小化寄存器和内存使用是一个问题,理想情况下,排序可能是最好的.
真的这个问题是一种高尔夫,其目标不是最小化源长度而是执行时间.我把它叫做"Zening"代码在本书的标题中的代码优化禅由迈克尔·亚伯拉什及其续集.
至于为什么它很有趣,有几个层次:
- 这个例子很简单,易于理解和衡量,并没有太多的C技能
- 它显示了为问题选择好算法的效果,以及编译器和底层硬件的效果.
这是我的参考(天真的,未优化的)实现和我的测试集.
#include <stdio.h>
static __inline__ int sort6(int * d){
char j, i, imin;
int tmp;
for (j = 0 ; j < 5 ; j++){
imin = j;
for (i = j + 1; i < 6 ; i++){
if (d[i] < d[imin]){
imin = i;
}
}
tmp = d[j];
d[j] = d[imin];
d[imin] = …推荐指数
解决办法
查看次数
排序10个数字的最快方法?(数字是32位)
我正在解决一个问题,它涉及非常快速地排序10个数字(int32).我的应用程序需要尽可能快地对10个数字进行数百万次排序.我正在对数十亿个元素的数据集进行采样,每次我需要从中挑选10个数字(简化)并对它们进行排序(并从排序的10个元素列表中得出结论).
目前我正在使用插入排序,但我想我可以实现一个非常快速的自定义排序算法,针对10个数字的特定问题,这将超过插入排序.
有没有人知道如何处理这个问题?
推荐指数
解决办法
查看次数
快速算法实现以排序非常小的列表
这是我很久以前遇到的问题.我想我可能会问你的想法.假设我有一个非常小的数字列表(整数),4或8个元素,需要快速排序.什么是最好的方法/算法?
我的方法是使用max/min函数(10个函数来排序4个数字,没有分支,iirc).
// s(i,j) == max(i,j), min(i,j)
i,j = s(i,j)
k,l = s(k,l)
i,k = s(i,k) // i on top
j,l = s(j,l) // l on bottom
j,k = s(j,k)
我想我的问题更多地与实现有关,而不是算法的类型.
此时它变得有点依赖于硬件,所以让我们假设带有SSE3的Intel 64位处理器.
谢谢
推荐指数
解决办法
查看次数
使用比较器网络快速排序固定长度阵列
我有一些性能关键代码,涉及在C++中对大约3到10个元素之间的非常短的固定长度数组进行排序(参数在编译时更改).
在我看来,专门针对每个可能的输入大小的静态排序网络可能是一种非常有效的方法:我们进行必要的比较以确定我们所处的情况,然后进行最佳的交换数量以进行排序数组.
要应用此功能,我们使用一些模板魔法来推断数组长度并应用正确的网络:
#include <iostream>
using namespace std;
template< int K >
void static_sort(const double(&array)[K])
{
cout << "General static sort\n" << endl;
}
template<>
void static_sort<3>(const double(&array)[3])
{
cout << "Static sort for K=3" << endl;
}
int main()
{
double array[3];
// performance critical code.
// ...
static_sort(array);
// ...
}
显然,编写所有这些代码非常麻烦,所以:
- 有没有人对是否值得努力有任何意见?
- 有谁知道这种优化是否存在于任何标准实现中,例如std :: sort?
- 是否有一个容易实现这种排序网络的代码?
- 也许有可能使用模板魔法静态生成这样的排序网络.
现在我只使用带有静态模板参数的插入排序(如上所述),希望它会鼓励展开和其他编译时优化.
欢迎你的想法.
更新: 我写了一些测试代码来比较'static'插入short和std :: sort.(当我说静态时,我的意思是数组大小是固定的并在编译时推断出来(可能是允许循环展开等).我至少得到20%的NET改进(请注意,生成包含在时间中).平台: clang,OS X 10.9.
代码在这里https://github.com/rosshemsley/static_sorting如果你想将它与你的stdlib实现进行比较.
我还没有为比较器网络分拣机找到一套很好的实现.
c++ arrays sorting template-meta-programming sorting-network
推荐指数
解决办法
查看次数
分拣网络如何击败通用排序算法?
关于最快排序的固定长度6 int数组,我不完全理解这个排序网络如何击败像插入排序这样的算法.
形成该问题,这里是完成排序所需的CPU周期数的比较:
Linux 32位,gcc 4.4.1,Intel Core 2 Quad Q8300,-O2
- 插入排序(Daniel Stutzbach):1425
- 排序网络(Daniel Stutzbach):1080
使用的代码如下:
插入排序(Daniel Stutzbach)
static inline void sort6_insertion_sort_v2(int *d){
int i, j;
for (i = 1; i < 6; i++) {
int tmp = d[i];
for (j = i; j >= 1 && tmp < d[j-1]; j--)
d[j] = d[j-1];
d[j] = tmp;
}
}
排序网络(Daniel Stutzbach)
static inline void sort6_sorting_network_v1(int * d){
#define SWAP(x,y) if (d[y] < d[x]) { int …推荐指数
解决办法
查看次数
最佳的9元素分类网络,可以减少到最佳的9中间网络?
我正在研究基于双输入最小/最大操作的九个元素的排序和中值选择网络.Knuth,TAOCP Vol.3,第2版.状态(第226页)九元素排序网络需要至少25次比较,这转换为相同数量的SWAP()基元或50分钟/最大值操作.显然,通过消除冗余操作,可以将分拣网络转换为中值选择网络.传统观点似乎是,这不会导致最佳的中值选择网络.虽然这似乎在经验上是正确的,但我在文献中找不到证据证明这一定是必然的.
LukáŝSekanina,"中位电路的进化设计空间探索".在:EvoWorkshops,2004年3月,第240-249页,给出了最佳九输入中值选择网络所需的最小/最大操作次数为30(表1).我通过John L. Smith给出的众所周知的中值选择网络"在XC4000E FPGA中实现中值滤波器"来验证这一点.XCELL杂志,Vol.23,1996,p.来自Chaitali Chakrabarti和Li-Yu Wang早期工作的"9"中间网络,"用于排序过滤器的基于网络的新型排序过滤器".IEEE超大规模集成系统交易,Vol.2,No.4(1994),pp.502-507,其中后者通过简单地消除冗余分量转换成前者.请参阅以下代码中的变体4和5.
通过消除冗余操作,检查公布的最佳九元排序网络是否适合转换为有效的中间选择网络,我设法找到的最佳版本来自John M. Gamble的在线生成器,它需要32分钟/最大操作,所以两个害羞的最佳操作计数.这在下面的代码中显示为变体1.其他最佳分拣网络分别减少到36分钟/最大操作(变体2)和38分钟/最大操作(变体3).
是否有任何已知的九元素分拣网络(即50个双输入最小/最大操作)通过单独消除冗余操作,减少到最佳九输入中值选择网络(具有30个双输入最小/最大操作) ?
下面的代码使用float数据作为测试用例,因为许多处理器为浮点数据提供最小/最大操作,但不提供整数数据,GPU是一个例外.由于特殊浮点操作数的问题(在我的实际用例中没有出现),最佳代码序列通常需要使用编译器提供的"快速数学"模式,例如在Godbolt测试平台中.
#include <cstdlib>
#include <cstdio>
#include <algorithm>
#define VARIANT 1
#define FULL_SORT 0
typedef float T;
#define MIN(a,b) std::min(a,b)
#define MAX(a,b) std::max(a,b)
#define SWAP(i,j) do { T s = MIN(a##i,a##j); T t = MAX(a##i,a##j); a##i = s; a##j = t; } while (0)
#define MIN3(x,y,z) MIN(a##x,MIN(a##y,a##z))
#define MAX3(x,y,z) MAX(a##x,MAX(a##y,a##z))
#define MED3(x,y,z) …推荐指数
解决办法
查看次数
标准排序网络,用于n的小值
我正在寻找一个5元素排序的排序网络实现,但由于我在SO上找不到一个好的参考,我想要求为所有小的n值排序网络,至少n = 3通过n = 6但更高的值也会很好.一个好的答案至少应该将它们列为"交换"(对2个元素进行排序)操作的序列,但是在低阶排序网络方面看到递归分解也可能会很好.
对于我的应用程序,我实际上只关心5个元素的中位数,而不是实际按顺序排列.也就是说,只要中位数在正确的位置结束,结果中可能未指定其他4个元素的顺序.可以使用与排序网络相关的方法来计算交换数量少于执行完整排序的中位数吗?如果是这样,我的问题(对于n = 5)和其他情况的这种解决方案也会得到一个很好的答案.
(注意:我已经标记了这个问题C,因为C是我使用的语言,我怀疑跟随C标签的人有很好的答案,但我真的不在乎答案实际上是用C编写而不是伪代码只要符合上述标准,它就可以很容易地转换成C语言.)
推荐指数
解决办法
查看次数
最佳Batcher奇偶合并网络的大小不同于2 ^ n
这些天,我一直在尝试使用最少数量的比较交换单元(最大尺寸,而不是深度)实现最大尺寸为32的分拣网络.截至目前,我已经能够使用以下资源来生成我的网络:
排序网络0到16:Perl的
Algorithm::Networksort模块采用"最佳"算法.不幸的是,它只提供最知名的网络直到16号.排序网络17至23:使用对称和进化搜索来最小化 Valsalam和Miikkulainen的排序网络.
纸张找到更好的排序网络通过Baddar给出已知有需要用于分拣网络0〜32比较-交换单元的最小数目(未最多到时间Valsalam和Miikkulainen为尺寸17,18,19提供更好的算法, 20,21和22)以及用于查找它们的方法:基本上,必须将数组拆分为两个排序,然后使用最知名的排序网络对这些大小进行排序,然后使用奇偶合并网络合并它们(这对应于Batcher的奇偶合并的合并步骤).
维基百科页面为Batcher的奇偶合并提供了以下Python实现:
def oddeven_merge(lo, hi, r):
step = r * 2
if step < hi - lo:
yield from oddeven_merge(lo, hi, step)
yield from oddeven_merge(lo + r, hi, step)
yield from [(i, i + r) for i in range(lo + r, hi - r, step)]
else:
yield (lo, lo + r)
def oddeven_merge_sort_range(lo, hi):
""" sort the part of x with …推荐指数
解决办法
查看次数
如何修复这种非递归奇偶合并排序算法?
我正在寻找非递归奇偶合并排序算法,并找到了两个来源:
- 一本来自Sedgewick R.的书.
- 这个问题
两种算法都相同但是错误.生成的排序网络不是奇偶合并排序网络.
以下是具有32个输入的结果网络的图像.2条水平线之间的垂直线表示将值a [x]与[y]进行比较,如果大于,则交换数组中的值.
32个输入的奇偶合并排序http://flylib.com/books/3/55/1/html/2/images/11fig07.gif(可点击)
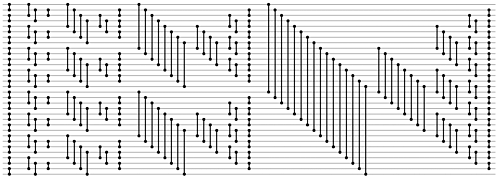{kind=link}
我将代码从Java复制到C并用excha 替换了函数printf来打印交换候选者.
当绘制对的图时,可以看出生成了太多对.
有谁知道如何修复此算法?
为什么我需要非递归版本?
我想将这个排序网络转换为硬件.将流水线阶段插入非递归算法很容易.
我还调查了递归版本,但是将算法转换为流水线硬件太复杂了.
我的C代码:
#include <stdlib.h>
#include <stdio.h>
void sort(int l, int r)
{ int n = r-l+1;
for (int p=1; p<n; p+=p)
for (int k=p; k>0; k/=2)
for (int j=k%p; j+k<n; j+=(k+k))
for (int i=0; i<n-j-k; i++)
if ((j+i)/(p+p) == (j+i+k)/(p+p))
printf("%2i cmp %2i\n", l+j+i, l+j+i+k);
}
int main(char* argv, int args)
{ const int COUNT = 8; …推荐指数
解决办法
查看次数
在修改了少量元素后重新排序向量
如果我们有一个先前已经排序的大小为N的向量,并且用任意值替换M个元素(其中M远小于N),是否有一种简单的方法可以以较低的成本对它们进行重新排序(即生成排序网络的深度减少)比完全排序?
例如,如果N = 10且M = 2,则输入可能是
10 20 30 40 999 60 70 80 90 -1
注意:修改元素的索引是未知的(直到我们将它们与周围元素进行比较.)
这是一个我知道解决方案的例子,因为输入大小很小,我可以通过强力搜索找到它:
如果N = 5且M为1,则这些将是有效输入:
0 0 0 0 0 0 0 1 0 0 0 1 0 0 0 0 1 1 1 0 1 0 0 1 1 1 1 1 1 0
0 0 0 0 1 0 0 1 0 1 0 1 0 0 1 0 1 1 1 …推荐指数
解决办法
查看次数
绘制排序网络
绘制类似于本文底部的排序网络的好方法是什么?非常感谢 python 包或 LaTeX typsetting 包。


推荐指数
解决办法
查看次数
比较两对4变量并返回匹配数?
给定以下结构:
struct four_points {
uint32_t a, b, c, d;
}
比较两个这样的结构并返回匹配的变量数(在任何位置)的绝对最快方法是什么?
例如:
four_points s1 = {0, 1, 2, 3};
four_points s2 = {1, 2, 3, 4};
我正在寻找3的结果,因为两个结构之间有三个数字匹配.但是,考虑到以下因素:
four_points s1 = {1, 0, 2, 0};
four_points s2 = {0, 1, 9, 7};
然后我期望结果只有2,因为在两个结构之间只有两个变量匹配(尽管第一个中有两个零).
我已经找到了一些用于执行比较的基本系统,但这在短时间内将被称为几百万次并且需要相对较快.我目前最好的尝试是使用排序网络对任一输入的所有四个值进行排序,然后循环排序值并保持相等值的计数,相应地提前任一输入的当前索引.
是否有任何类型的技术可以比排序和迭代更好地执行?
推荐指数
解决办法
查看次数
Numba 编译时间呈指数级爆炸 - 可以像 ac 编译器一样配置优化级别吗?
这段代码实现了排序网络,我正在尝试使用 Numba 来编译它们以提高性能。然而,每个函数的编译时间呈指数增长。总共有大约 60 个函数(下面仅显示 19 个示例),Numba 在太阳经历红巨星膨胀之前无法完成编译它们。
我怀疑问题在于 Numba 尝试在编译期间应用 -O2 等激进的优化标志,从而导致过度的复杂性和处理时间。
编辑:我发现 numba从环境变量 NUMBA_OPT 中获取他的优化级别,所以我将其设置0为
import os
os.environ["NUMBA_OPT"] = "0"
但它什么也没做。
有没有办法指示 Numba 简单地生成这些函数的汇编代码,而不尝试进一步优化?或者有其他方法可以编译它吗?
import numba as nb
import numpy as np
# This function calculates the min and the max of his parameters.
@nb.njit(nb.types.UniTuple(nb.uint64, 2)(nb.uint64, nb.uint64),fastmath=True,inline='always')
def m(a: np.uint64, b: np.uint64) -> (np.uint64, np.uint64):
return min(a, b), max(a, b)
@nb.njit(nb.uint64[:](nb.uint64[:]),fastmath=True)
def sort_small_array_1(a: 'np.ndarray[np.uint64]') -> 'np.ndarray[np.uint64]':
return a
print('Defining function 2')
@nb.njit(nb.uint64[:](nb.uint64[:]),fastmath=True) …推荐指数
解决办法
查看次数
标签 统计
sorting-network ×13
sorting ×10
algorithm ×6
c ×4
median ×2
optimization ×2
performance ×2
arrays ×1
c++ ×1
compare ×1
comparison ×1
compilation ×1
drawing ×1
gpgpu ×1
hdl ×1
latex ×1
merge ×1
mergesort ×1
numba ×1
python ×1
python-3.x ×1