标签: pyspark
Pyspark:以表格格式显示火花数据框
我正在使用pyspark来阅读下面的镶木地板文件:
my_df = sqlContext.read.parquet('hdfs://myPath/myDB.db/myTable/**')
然后,当我这样做时my_df.take(5),它将显示[Row(...)],而不是像我们使用pandas数据帧时的表格格式.
是否可以以pandas数据帧等表格格式显示数据帧?谢谢!
推荐指数
解决办法
查看次数
Spark加载数据并将文件名添加为dataframe列
我正在使用包装函数将一些数据加载到Spark中:
def load_data( filename ):
df = sqlContext.read.format("com.databricks.spark.csv")\
.option("delimiter", "\t")\
.option("header", "false")\
.option("mode", "DROPMALFORMED")\
.load(filename)
# add the filename base as hostname
( hostname, _ ) = os.path.splitext( os.path.basename(filename) )
( hostname, _ ) = os.path.splitext( hostname )
df = df.withColumn('hostname', lit(hostname))
return df
具体来说,我使用glob来一次加载一堆文件:
df = load_data( '/scratch/*.txt.gz' )
文件是:
/scratch/host1.txt.gz
/scratch/host2.txt.gz
...
我想列"主机名"实际上包含文件的真实名称被加载,而不是水珠(即host1,host2等等,而不是*).
我怎样才能做到这一点?
推荐指数
解决办法
查看次数
spark谓词下推是否适用于JDBC?
根据这个
Catalyst应用逻辑优化,例如谓词下推.优化器可以将过滤器谓词下推到数据源中,使物理执行能够跳过不相关的数据.
Spark支持将谓词下推到数据源.此功能是否也适用于JDBC?
(通过检查数据库日志,我可以看到它现在不是默认行为 - 完整查询将传递给数据库,即使它后来受到限制因素限制)
更多细节
使用PostgreSQL 9.4运行Spark 1.5
代码段:
from pyspark import SQLContext, SparkContext, Row, SparkConf
from data_access.data_access_db import REMOTE_CONNECTION
sc = SparkContext()
sqlContext = SQLContext(sc)
url = 'jdbc:postgresql://{host}/{database}?user={user}&password={password}'.format(**REMOTE_CONNECTION)
sql = "dummy"
df = sqlContext.read.jdbc(url=url, table=sql)
df = df.limit(1)
df.show()
SQL跟踪:
< 2015-09-15 07:11:37.718 EDT >LOG: execute <unnamed>: SET extra_float_digits = 3
< 2015-09-15 07:11:37.771 EDT >LOG: execute <unnamed>: SELECT * FROM dummy WHERE 1=0
< 2015-09-15 07:11:37.830 EDT >LOG: execute <unnamed>: SELECT c.oid, a.attnum, a.attname, c.relname, …推荐指数
解决办法
查看次数
保存ML模型以备将来使用
我正在将一些机器学习算法(如线性回归,Logistic回归和朴素贝叶斯)应用于某些数据,但我试图避免使用RDD并开始使用DataFrame,因为RDD比pyspark下的Dataframe 慢(见图1).
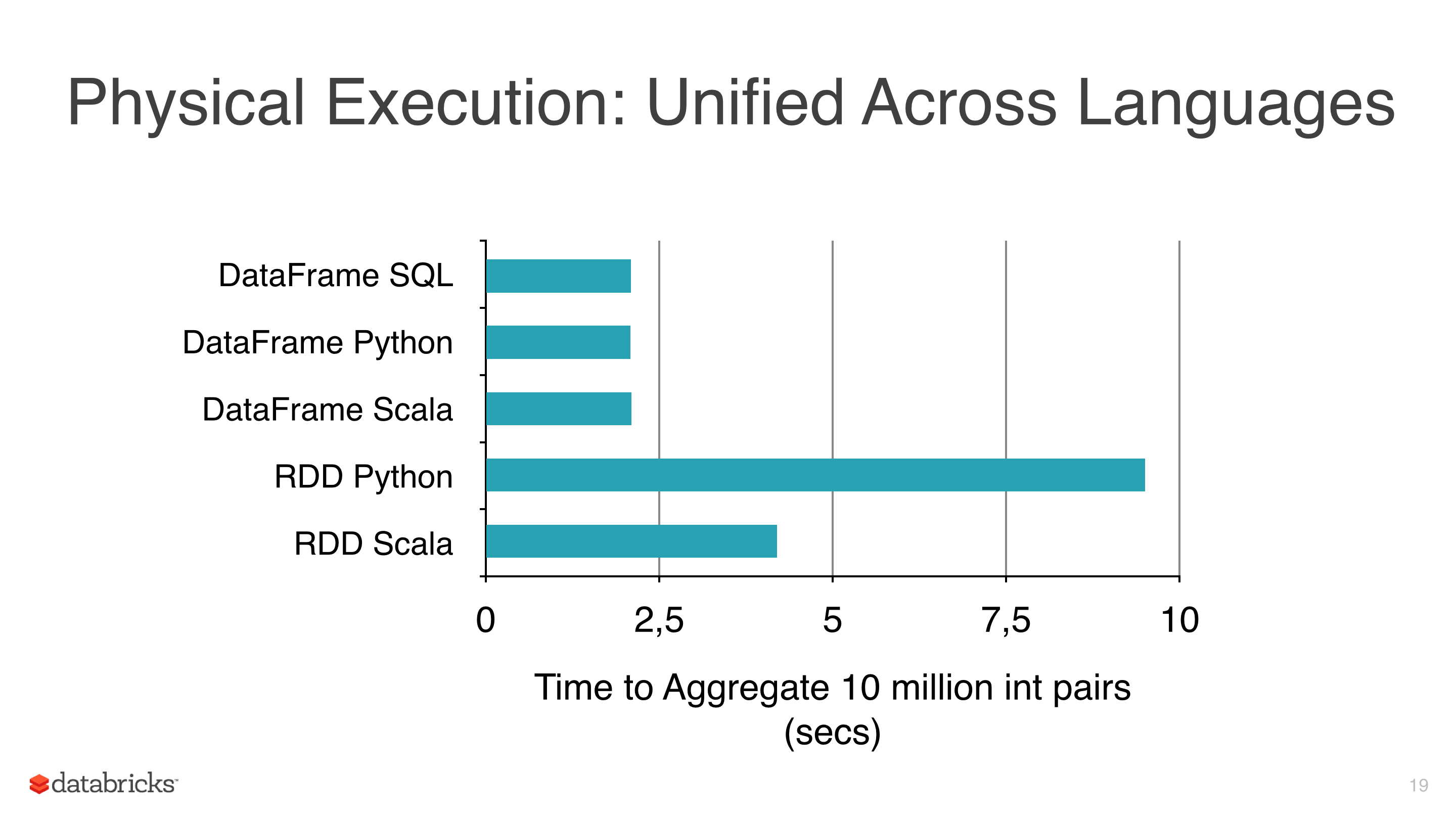
我使用DataFrames的另一个原因是因为ml库有一个非常有用的类来调整模型,CrossValidator这个类在拟合之后返回一个模型,显然这个方法必须测试几个场景,然后返回一个拟合的模型(与参数的最佳组合).
我使用的集群不是那么大,数据相当大,有些适合需要几个小时,所以我想保存这些模型以便以后重用它们,但我还没有意识到,有什么我忽略的东西?
笔记:
- mllib的模型类有一个保存方法(即NaiveBayes),但mllib没有CrossValidator并使用RDD,所以我有预谋地避免它.
- 目前的版本是spark 1.5.1.
推荐指数
解决办法
查看次数
Pyspark:重新分区vs partitionBy
我现在正在研究这两个概念,并希望有一些清晰度.通过命令行,我一直在尝试识别差异,以及开发人员何时使用repartition vs partitionBy.
以下是一些示例代码:
rdd = sc.parallelize([('a', 1), ('a', 2), ('b', 1), ('b', 3), ('c',1), ('ef',5)])
rdd1 = rdd.repartition(4)
rdd2 = rdd.partitionBy(4)
rdd1.glom().collect()
[[('b', 1), ('ef', 5)], [], [], [('a', 1), ('a', 2), ('b', 3), ('c', 1)]]
rdd2.glom().collect()
[[('a', 1), ('a', 2)], [], [('c', 1)], [('b', 1), ('b', 3), ('ef', 5)]]
我看了两者的实现,我注意到的唯一区别是partitionBy可以采用分区功能,或者默认情况下使用portable_hash.所以在partitionBy中,所有相同的键应该在同一个分区中.在重新分区中,我希望值在分区上更均匀地分布,但事实并非如此.
鉴于此,为什么有人会使用重新分配?我想我唯一能看到它被使用的是我是不是在使用PairRDD,或者我有大数据偏差?
有什么东西我不知道,还是有人可以从不同的角度为我揭开光芒?
推荐指数
解决办法
查看次数
查询pyspark中的HIVE表
我正在使用CDH5.5
我有一个在HIVE默认数据库中创建的表,并能够从HIVE命令查询它.
产量
hive> use default;
OK
Time taken: 0.582 seconds
hive> show tables;
OK
bank
Time taken: 0.341 seconds, Fetched: 1 row(s)
hive> select count(*) from bank;
OK
542
Time taken: 64.961 seconds, Fetched: 1 row(s)
但是,我无法从pyspark查询表,因为它无法识别表.
from pyspark.context import SparkContext
from pyspark.sql import HiveContext
sqlContext = HiveContext(sc)
sqlContext.sql("use default")
DataFrame[result: string]
sqlContext.sql("show tables").show()
+---------+-----------+
|tableName|isTemporary|
+---------+-----------+
+---------+-----------+
sqlContext.sql("FROM bank SELECT count(*)")
16/03/16 20:12:13 INFO parse.ParseDriver: Parsing command: FROM bank SELECT count(*)
16/03/16 20:12:13 INFO parse.ParseDriver: Parse Completed
Traceback …推荐指数
解决办法
查看次数
Pyspark Dataframe上的Pivot String列
我有一个像这样的简单数据框:
rdd = sc.parallelize(
[
(0, "A", 223,"201603", "PORT"),
(0, "A", 22,"201602", "PORT"),
(0, "A", 422,"201601", "DOCK"),
(1,"B", 3213,"201602", "DOCK"),
(1,"B", 3213,"201601", "PORT"),
(2,"C", 2321,"201601", "DOCK")
]
)
df_data = sqlContext.createDataFrame(rdd, ["id","type", "cost", "date", "ship"])
df_data.show()
+---+----+----+------+----+
| id|type|cost| date|ship|
+---+----+----+------+----+
| 0| A| 223|201603|PORT|
| 0| A| 22|201602|PORT|
| 0| A| 422|201601|DOCK|
| 1| B|3213|201602|DOCK|
| 1| B|3213|201601|PORT|
| 2| C|2321|201601|DOCK|
+---+----+----+------+----+
我需要按日期调整它:
df_data.groupby(df_data.id, df_data.type).pivot("date").avg("cost").show()
+---+----+------+------+------+
| id|type|201601|201602|201603|
+---+----+------+------+------+
| 2| C|2321.0| null| null|
| 0| A| 422.0| 22.0| …推荐指数
解决办法
查看次数
PySpark数据帧将异常字符串格式转换为Timestamp
我通过Spark 1.5.0使用PySpark.对于datetime值,我在列的行中有一个不常见的String格式.它看起来像这样:
Row[(daytetime='2016_08_21 11_31_08')]
有没有办法将这种非正统yyyy_mm_dd hh_mm_dd格式转换为时间戳?最终可能出现的问题
df = df.withColumn("date_time",df.daytetime.astype('Timestamp'))
我原以为像星火SQL函数regexp_replace可以工作,但我当然需要更换
_与-在日期一半_用:在部分时间.
我想我可以在2中拆分列,substring并从时间结束后向后计数.然后单独执行'regexp_replace',然后连接.但这似乎很多操作?有没有更简单的方法?
推荐指数
解决办法
查看次数
Python/pyspark数据框重新排列列
我在python/pyspark中有一个带有列的数据框id time city zip等等......
现在我name在这个数据框中添加了一个新列.
现在,我必须以这样的方式排列列,以便name列出来id
我在下面做了
change_cols = ['id', 'name']
cols = ([col for col in change_cols if col in df]
+ [col for col in df if col not in change_cols])
df = df[cols]
我收到了这个错误
pyspark.sql.utils.AnalysisException: u"Reference 'id' is ambiguous, could be: id#609, id#1224.;"
为什么会出现此错误.我怎样才能纠正这个问题.
推荐指数
解决办法
查看次数
AWS EMR上的奇怪火花错误
我有一个非常简单的PySpark脚本,它从S3上的一些拼花数据创建一个数据帧,然后调用count()方法并打印出记录数.
我在AWS EMR集群上运行脚本,我看到以下奇怪的WARN信息:
17/12/04 14:20:26 WARN ServletHandler:
javax.servlet.ServletException: java.util.NoSuchElementException: None.get
at org.glassfish.jersey.servlet.WebComponent.serviceImpl(WebComponent.java:489)
at org.glassfish.jersey.servlet.WebComponent.service(WebComponent.java:427)
at org.glassfish.jersey.servlet.ServletContainer.service(ServletContainer.java:388)
at org.glassfish.jersey.servlet.ServletContainer.service(ServletContainer.java:341)
at org.glassfish.jersey.servlet.ServletContainer.service(ServletContainer.java:228)
at org.spark_project.jetty.servlet.ServletHolder.handle(ServletHolder.java:845)
at org.spark_project.jetty.servlet.ServletHandler$CachedChain.doFilter(ServletHandler.java:1689)
at org.apache.hadoop.yarn.server.webproxy.amfilter.AmIpFilter.doFilter(AmIpFilter.java:164)
at org.spark_project.jetty.servlet.ServletHandler$CachedChain.doFilter(ServletHandler.java:1676)
at org.spark_project.jetty.servlet.ServletHandler.doHandle(ServletHandler.java:581)
at org.spark_project.jetty.server.handler.ContextHandler.doHandle(ContextHandler.java:1180)
at org.spark_project.jetty.servlet.ServletHandler.doScope(ServletHandler.java:511)
at org.spark_project.jetty.server.handler.ContextHandler.doScope(ContextHandler.java:1112)
at org.spark_project.jetty.server.handler.ScopedHandler.handle(ScopedHandler.java:141)
at org.spark_project.jetty.server.handler.gzip.GzipHandler.handle(GzipHandler.java:461)
at org.spark_project.jetty.server.handler.ContextHandlerCollection.handle(ContextHandlerCollection.java:213)
at org.spark_project.jetty.server.handler.HandlerWrapper.handle(HandlerWrapper.java:134)
at org.spark_project.jetty.server.Server.handle(Server.java:524)
at org.spark_project.jetty.server.HttpChannel.handle(HttpChannel.java:319)
at org.spark_project.jetty.server.HttpConnection.onFillable(HttpConnection.java:253)
at org.spark_project.jetty.io.AbstractConnection$ReadCallback.succeeded(AbstractConnection.java:273)
at org.spark_project.jetty.io.FillInterest.fillable(FillInterest.java:95)
at org.spark_project.jetty.io.SelectChannelEndPoint$2.run(SelectChannelEndPoint.java:93)
at org.spark_project.jetty.util.thread.strategy.ExecuteProduceConsume.executeProduceConsume(ExecuteProduceConsume.java:303)
at org.spark_project.jetty.util.thread.strategy.ExecuteProduceConsume.produceConsume(ExecuteProduceConsume.java:148)
at org.spark_project.jetty.util.thread.strategy.ExecuteProduceConsume.run(ExecuteProduceConsume.java:136)
at org.spark_project.jetty.util.thread.QueuedThreadPool.runJob(QueuedThreadPool.java:671)
at org.spark_project.jetty.util.thread.QueuedThreadPool$2.run(QueuedThreadPool.java:589)
at java.lang.Thread.run(Thread.java:748)
Caused by: java.util.NoSuchElementException: None.get
at scala.None$.get(Option.scala:347)
at scala.None$.get(Option.scala:345)
at org.apache.spark.status.api.v1.MetricHelper.submetricQuantiles(AllStagesResource.scala:313) …推荐指数
解决办法
查看次数
标签 统计
pyspark ×10
apache-spark ×7
python ×4
dataframe ×2
amazon-emr ×1
hive ×1
jdbc ×1
pandas ×1
timestamp ×1