我是 python 的初学者,我正在尝试将查询结果打印到管道分隔文件中。我怎样才能修改这个脚本来做到这一点?
import cx_Oracle
import csv
connection = cx_Oracle.connect("blah blah blah connection stuff")
cursor = connection.cursor()
cursor.execute("select column1, column2 from schema.table")
result=cursor.fetchall()
c = csv.writer(open("C:\mystuff\output.csv","wb"))
c.writerow(result)
现在它打印出来像这样“(10001965,'0828442C00548')”,“(10001985,'0696230C35242')”,“(10001986,'C41251')”
我希望它打印管道分隔符并在行末尾打印一个新行。谢谢你的帮助!10001965|0828442C00548\n 10001985|0696230C35242\n 10001986|C41251\n
我想将 JSON 对象导出到 CSV 文件,其中的子字段可能由对象数组填充,但我不知道如何在 CSV 中表示嵌入的数据。
当您调用 DataFrame.to_numpy() 时,pandas 将找到可以容纳 DataFrame 中所有数据类型的 NumPy 数据类型。但是如何进行反向操作呢?
我有一个“numpy.ndarray”对象“pred”。它看起来像这样:
[[0.00599913 0.00506044 0.00508315 ... 0.00540191 0.00542058 0.00542058]]
我正在尝试这样做:
pred = np.uint8(pred)
print("Model predict:\n", pred.T)
但我得到:
[[0 0 0 ... 0 0 0]]
为什么,转换后,我没有得到这样的东西:
0 0 0 0 0 0 ... 0 0 0 0 0 0
以及如何将 pred 写入文件?
pred.to_csv('pred.csv', header=None, index=False)
pred = pd.read_csv('pred.csv', sep=',', header=None)
给出错误信息:
AttributeError Traceback (most recent call last)
<ipython-input-68-b223b39b5db1> in <module>()
----> 1 pred.to_csv('pred.csv', header=None, index=False)
2 pred = pd.read_csv('pred.csv', sep=',', header=None)
AttributeError: 'numpy.ndarray' object …我正在尝试从 Flutter 应用程序的 SQLite 数据导出到 CSV。我想知道一种有效的方法来实现这一目标。
我想使用以下代码将字符串存储到 CSV 文件中,但正在生成空的 CSV。
代码
try {
PrintWriter writer = new PrintWriter(new File("test.csv"));
StringBuilder sb = new StringBuilder();
String str ="1 cup, honey, 2 tablespoons ,canola" ;
sb.append(str);
writer.write(String.valueOf(sb));
} catch (FileNotFoundException e) {
System.out.println(e.getMessage());
}
预期输出:
数据应在 CSV 文件中显示如下。
1杯
蜂蜜
2汤匙
油菜
我怎么能得到预期的结果。?
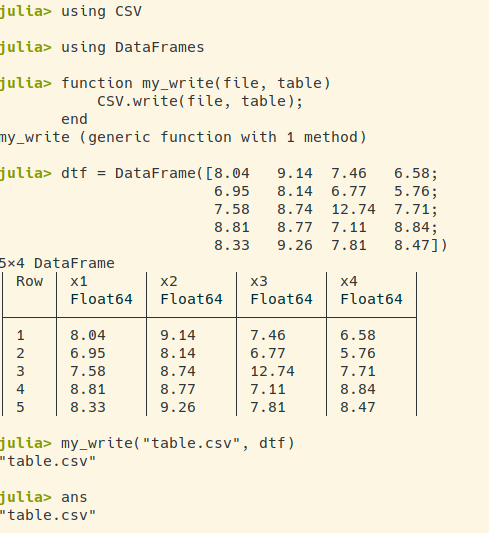
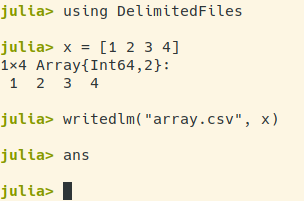
警告:这些都是菜鸟问题,因为我对 Julia真的很陌生。
在 R 中,有一个相当“统一”的函数来导出(几乎)任何类型的对象read.table()。看起来 Julia 的情况稍微复杂一些。如果我理解得很好:
某些标准类型(例如,数组、字典和元组)总是可以用 导出writedlm,但不能总是用导出CSV.write。相反,DataFrames 总是可以用 导出CSV.write,但永远不能用writedlm. 这样对吗?因此,不存在类似于 R 的“通用导出器” write.table()?
随着写入 CSV 文件,CSV.write似乎还返回导出文件的名称。相反,writedlm不会。这对我来说是个问题。实际上,我需要一种方法将 DataFrame 导出到带有不返回值的函数的 CSV 文件中,即只有副作用的函数,例如writedlm. 有什么办法可以在 Julia 中实现这一目标吗?
编辑:要详细了解,我的问题是在 aCSV.write之后ans指向导出文件的名称;而情况并非如此writedlm。这里和这里的插图。即使有@Przemyslaw Szufel 给出的想法,我也无法摆脱这一点。(这是一个相当微妙的问题,但我实际上是在尝试为 Julia 编写一个 emacs lisp 后端。这种不一致,例如在导出对象后不知道是answillnothing还是文件名,在这次冒险中增加了一些痛苦。 .. :-) 理想情况下,我只是希望CSV.write可以保持沉默。)
谢谢!
我现在已经尝试了很多解决方案,但恐怕我对JQ的理解还不够,我从两天前才开始尝试使用它。
我得到了一个非常好的解决方案来将我的文件从 Json 解析为 Csv,但是有一个小陷阱。
Json 内部有 1 个经过 Base64 编码的字段 (.data),它本身就是一个编码的 Json。在这个子 Json 中,有一个包含文本 (.text) 的字段,其中包含“\n”,并且在转换时,该行会被损坏,因为“\n”被转换为最终文件中的实际换行符。
这是我现在的命令:
jq-linux64 -r '["ackId","data","senderPhoneNumber","eventType","eventId","messageId2","postbackData","text","sendTime","project_number","type","event_type","product","messageId","publishTime"], (.receivedMessages[] | [.ackId, .message.data, (.message.data | @base64d | fromjson | .senderPhoneNumber, .eventType, .eventId, .messageId, .postbackData, .text, .sendTime), .message.attributes.project_number, .message.attributes.type, .message.attributes.event_type, .message.attributes.product, .message.messageId,.message.publishTime]) | @csv' <inputfile.txt >outputfile.txt
在此命令中,我进行解码,使用“fromjson”,然后从其中获取我需要的字段。
“.text”字段是我希望删除/替换的换行符字段。
我尝试了 sub 和 gsub,但无法创建有效的命令行或产生所需输出的命令行。
关于如何从“,text”字段中替换“\n”有什么提示吗?
输入文件示例:
{
"receivedMessages": [
{
"ackId": "xxxxxx",
"message": {
"data": "eyJzZW5kZXJQaG9uZU51bWJlciI6ICIrOTk5OTk5OTk5OTk5OSIsIm1lc3NhZ2VJZCI6ICIyM2QyM2QyM2QzMmQiLCJzZW5kVGltZSI6ICIyMDIxLTAyLTAyVDIwOjAwOjAwLjAwMDAxIiwidGV4dCI6ICJYWFhYWCBYWFhYWFhYRSwgWFhYWFhYWC8gWHh4eHh4LlxuXG5YeHh4eHh4eHg6XG5cbjEgeHh4eCB4eCB4eHh4ICgyMDAgeHgpXG4yLDUgeHh4eHhcbjEgeHh4eCBcblxuWHh4eHh4IHh4eHh4eCJ9Cg==",
"attributes": {
"product": "XXXX",
"project_number": "XXXXXX",
"message_type": "TEXT",
"type": "message"
},
"messageId": "234234234234234234",
"publishTime": "2021-02-02T20:15:22.888Z" …我有一个“10000 元素向量{BitVector}”,每个向量的固定长度为 100,我只想将其保存到 0 和 1 的 csv 文件中,仅此而已。当我输入变量时,我几乎在 csv 文件中看到了我想要的输出类型。
在我尝试过的许多事情中,最接近成功的是:
CSV.write("\\Folder\\file.csv", Tables.table(variable), writeheader=false)
但我的 csv 文件有 10000 行和 1 列,其中每行类似于 Bool[0,1,0,0,1,1,0,1,0]。
我有一个相当大的熊猫数据框,我想根据条件选择一些行。
问题在于,另存为 CSV 的操作与程序的整体流程是分开的,并且会消耗相当多的时间。
是否可以分离线程,以便主线程前进到选定的行,同时将未选定的行保存为另一个线程中的 csv?
例如...
# This is pseudo code
import pandas as pd
df = pd.DataFrame({"col1":[x for x in range(10000)], "col2":[x**2 for x in range(0, 10000)]})
df_selected = df[df.apply(lambda x: x.col1%3==0, axis=1)]
df_unselected = df[df.apply(lambda x: x.col1%3!=0, axis=1)]
def Other_thread_save_to_csv(df:pd.DataFrame):
# this function is the last function to use df_unselected .
Other_thread_save_to_csv(df_unselected )
all_other_hadlings(df_selected )
我希望得到一个javascript函数,它将我的数据网格(zero.grid.DataGrid)充满数据导出到csv文件或类似的东西,可以由电子表格应用程序打开.
有没有任何标准的方法来做到这一点..
谢谢
安迪
{kind=link}
{kind=link}