标签: bulk
如何批量上传数据到Google App Engine数据存储区?
我有大约4000条记录需要上传到Datastore.
它们目前是CSV格式.如果有人指出或解释如何将数据批量上传到GAE,我将不胜感激.
推荐指数
解决办法
查看次数
SQL Server 2005中的死锁!两个实时批量upsert正在战斗.为什么?

这是场景:
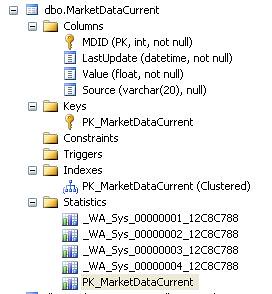
我有一个名为MarketDataCurrent(MDC)的表,它有实时更新的股票价格.
我有一个名为'LiveFeed'的进程,它读取从线路流出的价格,排队插入,并使用'批量上传到临时表然后插入/更新到MDC表'.(BulkUpsert)
我有另一个进程,然后读取此数据,计算其他数据,然后使用类似的BulkUpsert存储过程将结果保存回同一个表中.
第三,有许多用户运行C#Gui轮询MDC表并从中读取更新.
现在,在数据快速变化的那一天,事情运行得非常顺利,但是在市场营业时间之后,我们最近开始看到数据库中出现越来越多的死锁异常,现在我们每天看到10-20个.这里要注意的重要一点是,当值不变时会发生这些.
以下是所有相关信息:
表格定义:
CREATE TABLE [dbo].[MarketDataCurrent](
[MDID] [int] NOT NULL,
[LastUpdate] [datetime] NOT NULL,
[Value] [float] NOT NULL,
[Source] [varchar](20) NULL,
CONSTRAINT [PK_MarketDataCurrent] PRIMARY KEY CLUSTERED
(
[MDID] ASC
)WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, IGNORE_DUP_KEY = OFF,
ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) ON [PRIMARY]
) ON [PRIMARY]
-
我有一个Sql Profiler跟踪运行,捕获死锁,这就是所有图形的样子.
过程258被重复地称为以下'BulkUpsert'存储过程,而73正在调用下一个:
ALTER proc [dbo].[MarketDataCurrent_BulkUpload]
@updateTime datetime,
@source varchar(10)
as
begin transaction
update c with (rowlock) set LastUpdate = getdate(), Value = t.Value, …deadlock sql-server-2005 bulk primary-key database-deadlocks
推荐指数
解决办法
查看次数
Google App Engine批量下载
我使用批量下载从数据存储区下载数据(超过1 GB).突然,我的互联网停止工作,下载过程停在中间.我想从它停止的地方恢复.当我尝试时,我收到以下错误
File "/Users/FYP/GoogleAppEngineLauncher.app/Contents/Resources/GoogleAppEngine-default.bundle/Contents/Resources/google_appengine/google/appengine/api/datastore_types.py", line 156, in ValidateString
(name, value, typename(value)))
BadArgumentError: kind should be a string; received 3 (a int):
[INFO ] [WorkerThread-2] Backing off due to errors: 1.0 seconds
[INFO ] An error occurred. Shutting down...
[ERROR ] Error in WorkerThread-0: kind should be a string; received 3 (a int):
这是我下载数据的代码
appcfg.py download_data --config_file=bulkloader.yaml --batch_size=200 --filename=final80_2.csv
--kind=TasksTime1 --url=http://abc.appspot.com/_ah/remote_api --rps_limit=40
--db_filename=bulkloader-progress-20110429.141103 --result_db_filename=bulkloader-results-20110429.141103
如何解决问题?
推荐指数
解决办法
查看次数
复杂UI上的批量更新
我有一个非常复杂的UI,具有不断变化的状态栏,具有多种类型的状态消息和具有复杂图表控件和加载的指示性地理地图的UI.
现在,这些小但复杂区域的数据上下文具有同样复杂的ViewModel,如StatusBarVM,ChartingVM,GeoMapVM等......它们实现了INotifyPropertyChanged和ObservableCollections.
计算我的更新我发现我有大约5000个UI项目(标签,进度条,图表数据点,bgcolorsbrushes等),它们以每秒1000个数据项更新的速度变化.
在WPF UI上实现批量数据更新的最佳方法是什么?
WPF的绑定模型是否能够进行如此大规模的更新?如果是这样的话?因为我认为在我的情况下它不是最佳的.我正在使用bgworker(for progressbars)并使用DIspatcher BeginInvoke ...但重点是,即使这样,更新也会挂起UI线程,因为调度程序消息排队等待完成.
我不能实现虚拟化,因为状态是实时的,我必须在我面前的UI上看到它们.我甚至不能错过它们几秒钟(例如常数变化的卫星的地理数据).
请帮助我确定一个正确的工具或某种方法来实现复杂但高响应的WPF UI.它是Dispatcher.PushFrame()吗?
推荐指数
解决办法
查看次数
在asp.net中发送批量电子邮件的最佳方式
我有一个网站,我需要向注册会员发送个性化电子邮件.这不是广告程序(垃圾邮件),而是不时告知他们的状态.必须批量发送的电子邮件数量最多为3000个.该网站托管在Windows 2008 Server(VPS)上,我在IIS7上安装了SMTP.
在花了一些时间阅读如何实现通过asp.net发送大量电子邮件的机制后,我感到有点困惑.
从我读到的我可以:
- 在循环中同步或异步(新线程)发送它们
- 准备并将它们放在皮卡目录中
- 创建一个检查现有队列的Windows服务
- 从sql server 2008发送它们(我已快递).
你能建议最好的方式吗?
关于黑名单我的服务器有问题吗?
有没有更好的方法,这里没有提到实现这个?
提前致谢.
推荐指数
解决办法
查看次数
libusb批量转移
我正在尝试使用libusb1.0.9实现用户空间usb驱动程序.我有lpc2148蓝板(ARM7)和我一起使用.这个主板是由Bertrik Sikken先生装载的开源USB堆栈/固件.现在我的用户空间驱动程序尝试用板写读.我正在获取垃圾数据.我想了解批量转运的流程.对于任何传输/事务是否涉及内核设备驱动程序?我们还需要usb小工具设备驱动吗?我无法理解数据被复制的位置.重要的是,当我读/写中断生成时,我可以在LCD上看到正确的数据.我需要读/写USBRxData/USBTxData吗?请做必要的.
我尝试了以下代码进行批量传输读写.
int usb_read(struct libusb_device *dev,struct libusb_device_handle *hDevice)
{
char *data,*data1;
struct libusb_endpoint_descriptor *ep;
struct libusb_interface_descriptor *id;
int len=64,r,ret_alt,ret_clm,ret_rst,i;
struct libusb_device **list;
data = (char *)malloc(512); //allocation of buffers
data1 = (char *)malloc(512);
memset(data,'\0',512);
memset(data1,'\0',512);
if(hDevice==NULL)
{
printf("\nNO device found\n");
return 0;
}
int ret_open = libusb_open(dev,&hDevice);
if(ret_open!=0)
{
printf("Error in libusb_open\n");
libusb_free_device_list(list,1);
return -1;
}
char str_tx[512]="G"; //data to send to device
char str_rx[512]; //receive string
data = str_tx;
printf("data::%s\t,str::%s\n",data,str_tx);
//printf("%c\n",data);
ep = active_config(dev,hDevice);
printf("after ep\n");
//printf("alt_interface = …推荐指数
解决办法
查看次数
Bash脚本/命令从文件名中批量删除"@ 2x"(视网膜图像 - >正常)
如何在bash命令或脚本中重命名大量文件,以删除iOS的视网膜指示器(@ 2x)?
我已经调整了它们的大小,但重命名软件在重命名输出文件时并不聪明.
推荐指数
解决办法
查看次数
如何在Rails API中集成批处理请求?
我正在使用Rails 4构建API,我真的想创建一个批处理请求方法,以便在执行一堆ajax请求时不会使我的应用程序过载.
Railscasts以简单的方式展示了如何做到这一点,但缺少很多东西.
我也试过了batch_api gem,但是我没有成功地将它与我的应用程序集成.
有任何想法吗?
推荐指数
解决办法
查看次数
ElasticSearch批量操作 - 省略响应
我只是想知道是否有任何参数/方法通过ElasticSearch REST api发出批量请求而没有返回响应.
试图尽可能地挤出网络性能,我不关心我的用例中的批量操作的结果.由于我现在正在快速插入20,000个批次,我想我会通过省略它来节省大量的数据传输开销.
推荐指数
解决办法
查看次数
Spring Batch一次处理多个项目
我们正在使用 Spring Batch 进行一些处理,通过 Reader 读取一些 id,我们希望通过处理器将它们作为“块”处理,然后写入多个文件。但是处理器接口一次只允许处理一个项目,我们需要进行批量处理,因为处理器依赖于第三方,并且不能为每个项目调用服务。
我看到我们可以为“chunk”中涉及的所有 Reader-Processor-Writers 创建 Wrappers 来处理 List<> 并委托给一些具体的读取器/处理器/写入器。但这对我来说似乎并不好。像这样:
<batch:chunk reader="wrappedReader" processor="wrappedProcessor" writer="wrappedWriter"
commit-interval="2"/>
是否有“分块”选项可以在处理器之前分块?而不是在 Writer 之前。
干杯,
推荐指数
解决办法
查看次数