标签: breadth-first-search
什么时候使用深度优先搜索(DFS)与广度优先搜索(BFS)是否可行?
我理解DFS和BFS之间的区别,但是我很想知道何时使用一个比另一个更实用?
任何人都可以举例说明DFS如何胜过BFS,反之亦然?
algorithm graph-theory breadth-first-search depth-first-search graph-algorithm
推荐指数
解决办法
查看次数
广度优先与深度优先
遍历树/图时,广度优先和深度之间的区别首先是什么?任何编码或伪代码示例都会很棒.
algorithm breadth-first-search tree-traversal depth-first-search
推荐指数
解决办法
查看次数
递归执行广度优先搜索
假设您希望以递归方式实现广度优先搜索二叉树.你会怎么做?
是否可以仅使用调用堆栈作为辅助存储?
推荐指数
解决办法
查看次数
为什么DFS和BFS O(V + E)的时间复杂度
BFS的基本算法:
set start vertex to visited
load it into queue
while queue not empty
for each edge incident to vertex
if its not visited
load into queue
mark vertex
所以我认为时间的复杂性将是:
v1 + (incident edges) + v2 + (incident edges) + .... + vn + (incident edges)
v顶点1到哪里n
首先,我说的是正确的吗?其次,这是怎样的O(N + E),直觉为什么会非常好.谢谢
推荐指数
解决办法
查看次数
在寻找最短路径时,广度优先搜索如何工作?
我做了一些研究,我似乎错过了这个算法的一小部分.我明白了一个广度优先搜索是如何工作的,但我不明白它究竟是如何让我到一个特定的路径,而不是仅仅告诉我,每个单独的节点可以走了.我想解释我困惑的最简单方法是提供一个例子:
例如,假设我有一个这样的图形:

我的目标是从A到E(所有边缘都没有加权).
我从A开始,因为那是我的起源.我排队A,然后立即将A排队并探索它.这产生B和D,因为A连接到B和D.因此我将B和D排队.
我将B排队并探索它,并发现它导致A(已经探索过)和C,所以我排队C.然后我排队D,并发现它导致E,我的目标.然后我将C排队,并发现它也导致E,我的目标.
我逻辑上知道最快的路径是A-> D-> E,但我不确定广度优先搜索有多精确 - 我应该如何记录路径,这样当我完成时,我可以分析结果并查看最短的路径是A-> D-> E?
另外,请注意我实际上并没有使用树,因此没有"父"节点,只有子节点.
推荐指数
解决办法
查看次数
如果广度优先搜索(BFS)可以更快地做同样的事情,为什么要使用Dijkstra的算法?
两者都可用于从单一来源找到最短路径.BFS运行O(E+V),而Dijkstra运行O((V+E)*log(V)).
另外,我见过Dijkstra在路由协议中使用了很多.
因此,如果BFS可以更快地做同样的事情,为什么要使用Dijkstra的算法呢?
推荐指数
解决办法
查看次数
如何在广度优先搜索中跟踪路径?
如何跟踪广度优先搜索的路径,以便在以下示例中:
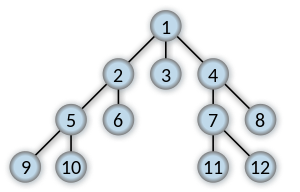
如果要搜索密钥11,请返回连接1到11 的最短列表.
[1, 4, 7, 11]
推荐指数
解决办法
查看次数
为什么DFS而不是BFS在图中查找周期
主要是DFS用于在图中找到循环而不是BFS.有什么原因?两者都可以在遍历树/图时查找是否已访问过节点.
algorithm tree graph breadth-first-search depth-first-search
推荐指数
解决办法
查看次数
BFS和DFS运行时的说明
为什么BFS和DFS O(V + E)的运行时间,特别是当有一个节点具有可以从顶点到达的节点的有向边时,就像在以下站点中的此示例中一样
http://www.personal.kent.edu/~rmuhamma/Algorithms/MyAlgorithms/GraphAlgor/depthSearch.htm
graph breadth-first-search time-complexity depth-first-search data-structures
推荐指数
解决办法
查看次数
广度优先搜索时间复杂度分析
例如,遍历顶点的每个相邻边的时间复杂度O(N),其中N是相邻边的数量.因此,对于V个顶点,时间复杂度变为O(V*N)= O(E),其中E是图中边的总数.由于从队列中删除和添加顶点是O(1),为什么它被添加到BFS的总体时间复杂度中O(V+E).
推荐指数
解决办法
查看次数