标签: apache-spark-ml
如何将数组(即列表)列转换为Vector
问题的简短版本!
请考虑以下代码段(假设spark已设置为某些代码段SparkSession):
from pyspark.sql import Row
source_data = [
Row(city="Chicago", temperatures=[-1.0, -2.0, -3.0]),
Row(city="New York", temperatures=[-7.0, -7.0, -5.0]),
]
df = spark.createDataFrame(source_data)
请注意,temperature字段是浮动列表.我想将这些浮点数列表转换为MLlib类型Vector,我希望使用基本DataFrameAPI 表示这种转换,而不是通过RDD表达(这是低效的,因为它将所有数据从JVM发送到Python,处理在Python中完成,我们没有得到Spark的Catalyst优化器,yada yada的好处.我该怎么做呢?特别:
- 有没有办法让直接演员工作?请参阅下面的详细信息(以及尝试解决方法失败)?或者,是否有其他操作具有我之后的效果?
- 从我在下面建议的两种替代解决方案(UDF vs爆炸/重新组合列表中的项目)中哪种更有效?或者是否有其他几乎但不是非常正确的替代品比其中任何一种更好?
直接投射不起作用
这就是我期望的"正确"解决方案.我想将列的类型从一种类型转换为另一种类型,所以我应该使用强制转换.作为一个上下文,让我提醒您将其转换为另一种类型的正常方法:
from pyspark.sql import types
df_with_strings = df.select(
df["city"],
df["temperatures"].cast(types.ArrayType(types.StringType()))),
)
现在例如df_with_strings.collect()[0]["temperatures"][1]是'-7.0'.但是如果我施放到ml Vector那么事情就不那么顺利了:
from pyspark.ml.linalg import VectorUDT
df_with_vectors = df.select(df["city"], df["temperatures"].cast(VectorUDT()))
这给出了一个错误:
pyspark.sql.utils.AnalysisException: "cannot resolve 'CAST(`temperatures` AS STRUCT<`type`: TINYINT, `size`: INT, `indices`: ARRAY<INT>, `values`: ARRAY<DOUBLE>>)' due to data type …python apache-spark apache-spark-sql pyspark apache-spark-ml
推荐指数
解决办法
查看次数
如何使用spark-ml处理分类功能?
如何处理与分类数据 spark-ml ,而不是 spark-mllib?
认为文档不是很清楚,似乎分类器例如RandomForestClassifier,LogisticRegression有一个featuresCol参数,它指定了特征列的名称DataFrame,以及一个labelCol参数,它指定了标记类的列的名称DataFrame.
显然我想在我的预测中使用多个功能,所以我尝试使用VectorAssembler将所有功能放在一个向量下featuresCol.
但是,VectorAssembler只接受数字类型,布尔类型和矢量类型(根据Spark网站),所以我不能在我的特征向量中添加字符串.
我该怎么办?
categorical-data apache-spark apache-spark-ml apache-spark-mllib
推荐指数
解决办法
查看次数
Spark ML和MLLIB包之间有什么区别
我注意到LinearRegressionModelSparkML中有两个类,一个在ML中,另一个在MLLib包中.
这两个实现方式完全不同 - 例如,一个来自MLLib工具Serializable,而另一个则没有.
顺便说一句,Ame是真实的RandomForestModel.
为什么有两节课?哪个是"正确的"?有没有办法将一个转换成另一个?
推荐指数
解决办法
查看次数
如何将Vector拆分为列 - 使用PySpark
上下文:我有DataFrame2列:单词和向量.其中"vector"的列类型是VectorUDT.
一个例子:
word | vector
assert | [435,323,324,212...]
我希望得到这个:
word | v1 | v2 | v3 | v4 | v5 | v6 ......
assert | 435 | 5435| 698| 356|....
题:
如何使用PySpark为每个维度拆分包含多列向量的列?
提前致谢
python apache-spark apache-spark-sql pyspark apache-spark-ml
推荐指数
解决办法
查看次数
在PySpark中编码和组合多个功能
我有一个Python类,我用它来加载和处理Spark中的一些数据.在我需要做的各种事情中,我正在生成一个从Spark数据帧中的各个列派生的虚拟变量列表.我的问题是我不确定如何正确定义用户定义函数来完成我需要的东西.
我做目前有,当映射了潜在的数据帧RDD,解决了问题的一半(记住,这是在一个更大的方法等data_processor类):
def build_feature_arr(self,table):
# this dict has keys for all the columns for which I need dummy coding
categories = {'gender':['1','2'], ..}
# there are actually two differnt dataframes that I need to do this for, this just specifies which I'm looking at, and grabs the relevant features from a config file
if table == 'users':
iter_over = self.config.dyadic_features_to_include
elif table == 'activty':
iter_over = self.config.user_features_to_include
def _build_feature_arr(row):
result = []
row = row.asDict()
for …python apache-spark apache-spark-sql apache-spark-ml apache-spark-mllib
推荐指数
解决办法
查看次数
保存ML模型以备将来使用
我正在将一些机器学习算法(如线性回归,Logistic回归和朴素贝叶斯)应用于某些数据,但我试图避免使用RDD并开始使用DataFrame,因为RDD比pyspark下的Dataframe 慢(见图1).
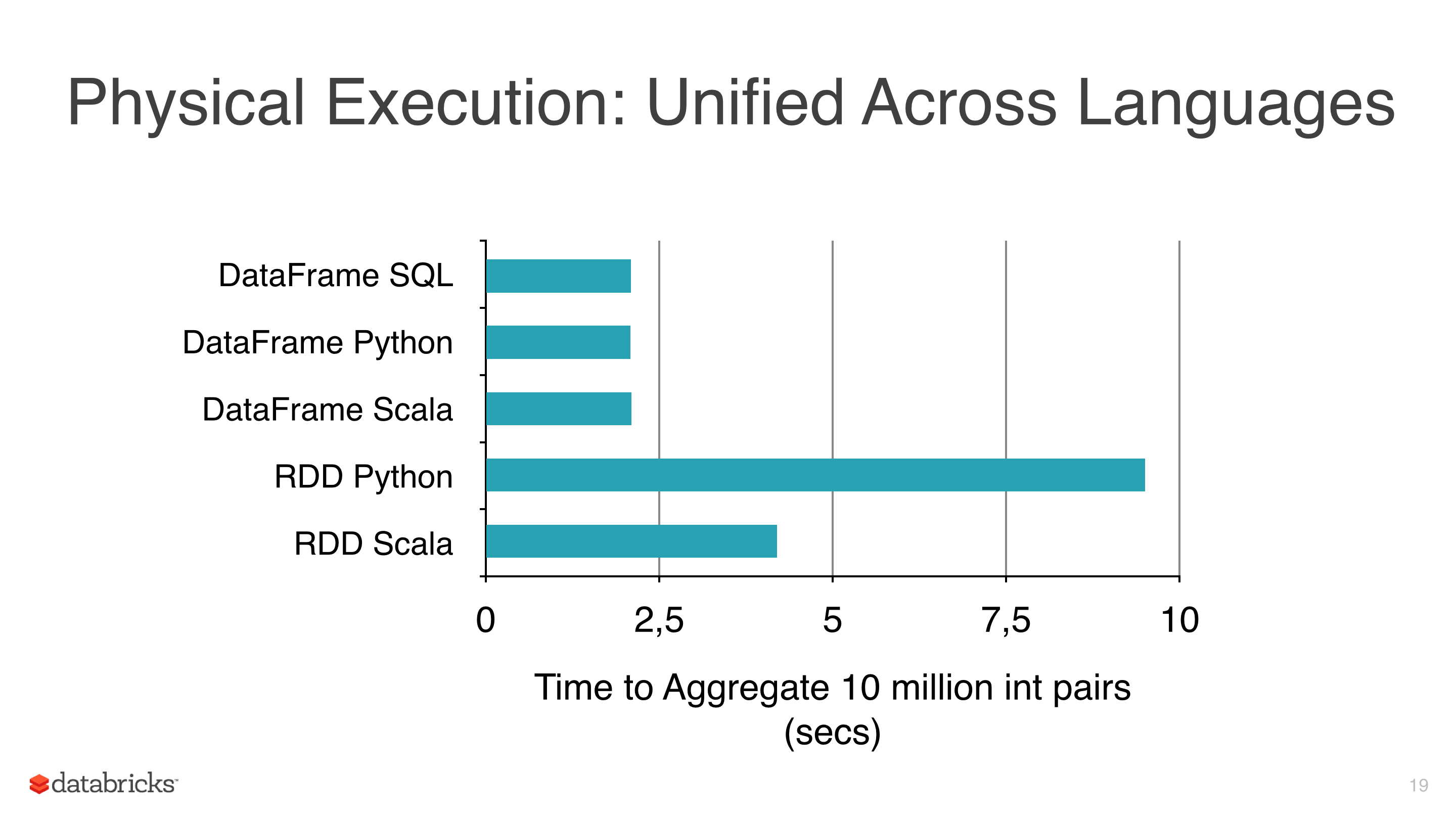
我使用DataFrames的另一个原因是因为ml库有一个非常有用的类来调整模型,CrossValidator这个类在拟合之后返回一个模型,显然这个方法必须测试几个场景,然后返回一个拟合的模型(与参数的最佳组合).
我使用的集群不是那么大,数据相当大,有些适合需要几个小时,所以我想保存这些模型以便以后重用它们,但我还没有意识到,有什么我忽略的东西?
笔记:
- mllib的模型类有一个保存方法(即NaiveBayes),但mllib没有CrossValidator并使用RDD,所以我有预谋地避免它.
- 目前的版本是spark 1.5.1.
推荐指数
解决办法
查看次数
如何定义自定义聚合函数来对一列向量求和?
我有一个两列的DataFrame,ID类型Int和Vec类型Vector(org.apache.spark.mllib.linalg.Vector).
DataFrame如下所示:
ID,Vec
1,[0,0,5]
1,[4,0,1]
1,[1,2,1]
2,[7,5,0]
2,[3,3,4]
3,[0,8,1]
3,[0,0,1]
3,[7,7,7]
....
我想groupBy($"ID")通过对向量求和来对每个组内的行应用聚合.
上述示例的所需输出将是:
ID,SumOfVectors
1,[5,2,7]
2,[10,8,4]
3,[7,15,9]
...
可用的聚合函数将不起作用,例如,df.groupBy($"ID").agg(sum($"Vec")将导致ClassCastException.
如何实现自定义聚合函数,允许我进行向量或数组的总和或任何其他自定义操作?
scala aggregate-functions apache-spark apache-spark-sql apache-spark-ml
推荐指数
解决办法
查看次数
Spark中的HashingTF和CountVectorizer有什么区别?
试图在Spark中进行doc分类.我不确定HashingTF中的散列是做什么的; 它会牺牲任何准确性吗?我对此表示怀疑,但我不知道.spark文档说它使用了"散列技巧"......只是工程师使用的另一个非常糟糕/混乱命名的例子(我也很内疚).CountVectorizer还需要设置词汇量大小,但它有另一个参数,一个阈值参数,可用于排除出现在文本语料库中某个阈值以下的单词或标记.我不明白这两个变形金刚之间的区别.使这一点很重要的是算法中的后续步骤.例如,如果我想在生成的tfidf矩阵上执行SVD,那么词汇量大小将决定SVD矩阵的大小,这会影响代码的运行时间,以及模型性能等.我一般有困难在API文档之外找到关于Spark Mllib的任何来源以及没有深度的非常简单的例子.
推荐指数
解决办法
查看次数
Pyspark和PCA:如何提取此PCA的特征向量?如何计算他们解释的方差?
我正在使用pyspark(使用库)减少Spark DataFrame带有PCA模型的维度,spark ml如下所示:
pca = PCA(k=3, inputCol="features", outputCol="pca_features")
model = pca.fit(data)
在哪里data是一个Spark DataFrame实验室,其中features一个DenseVector是3维:
data.take(1)
Row(features=DenseVector([0.4536,-0.43218, 0.9876]), label=u'class1')
拟合后,我转换数据:
transformed = model.transform(data)
transformed.first()
Row(features=DenseVector([0.4536,-0.43218, 0.9876]), label=u'class1', pca_features=DenseVector([-0.33256, 0.8668, 0.625]))
我的问题是:如何提取此PCA的特征向量?如何计算他们解释的方差?
推荐指数
解决办法
查看次数
如何从PySpark中的spark.ml中提取模型超参数?
我正在修补PySpark文档中的一些交叉验证代码,并尝试让PySpark告诉我选择了哪个模型:
from pyspark.ml.classification import LogisticRegression
from pyspark.ml.evaluation import BinaryClassificationEvaluator
from pyspark.mllib.linalg import Vectors
from pyspark.ml.tuning import ParamGridBuilder, CrossValidator
dataset = sqlContext.createDataFrame(
[(Vectors.dense([0.0]), 0.0),
(Vectors.dense([0.4]), 1.0),
(Vectors.dense([0.5]), 0.0),
(Vectors.dense([0.6]), 1.0),
(Vectors.dense([1.0]), 1.0)] * 10,
["features", "label"])
lr = LogisticRegression()
grid = ParamGridBuilder().addGrid(lr.regParam, [0.1, 0.01, 0.001, 0.0001]).build()
evaluator = BinaryClassificationEvaluator()
cv = CrossValidator(estimator=lr, estimatorParamMaps=grid, evaluator=evaluator)
cvModel = cv.fit(dataset)
在PySpark shell中运行它,我可以得到线性回归模型的系数,但我似乎无法找到lr.regParam交叉验证程序选择的值.有任何想法吗?
In [3]: cvModel.bestModel.coefficients
Out[3]: DenseVector([3.1573])
In [4]: cvModel.bestModel.explainParams()
Out[4]: ''
In [5]: cvModel.bestModel.extractParamMap()
Out[5]: {}
In [15]: cvModel.params
Out[15]: [] …modeling cross-validation pyspark apache-spark-ml apache-spark-mllib
推荐指数
解决办法
查看次数