相关疑难解决方法(0)
保存ML模型以备将来使用
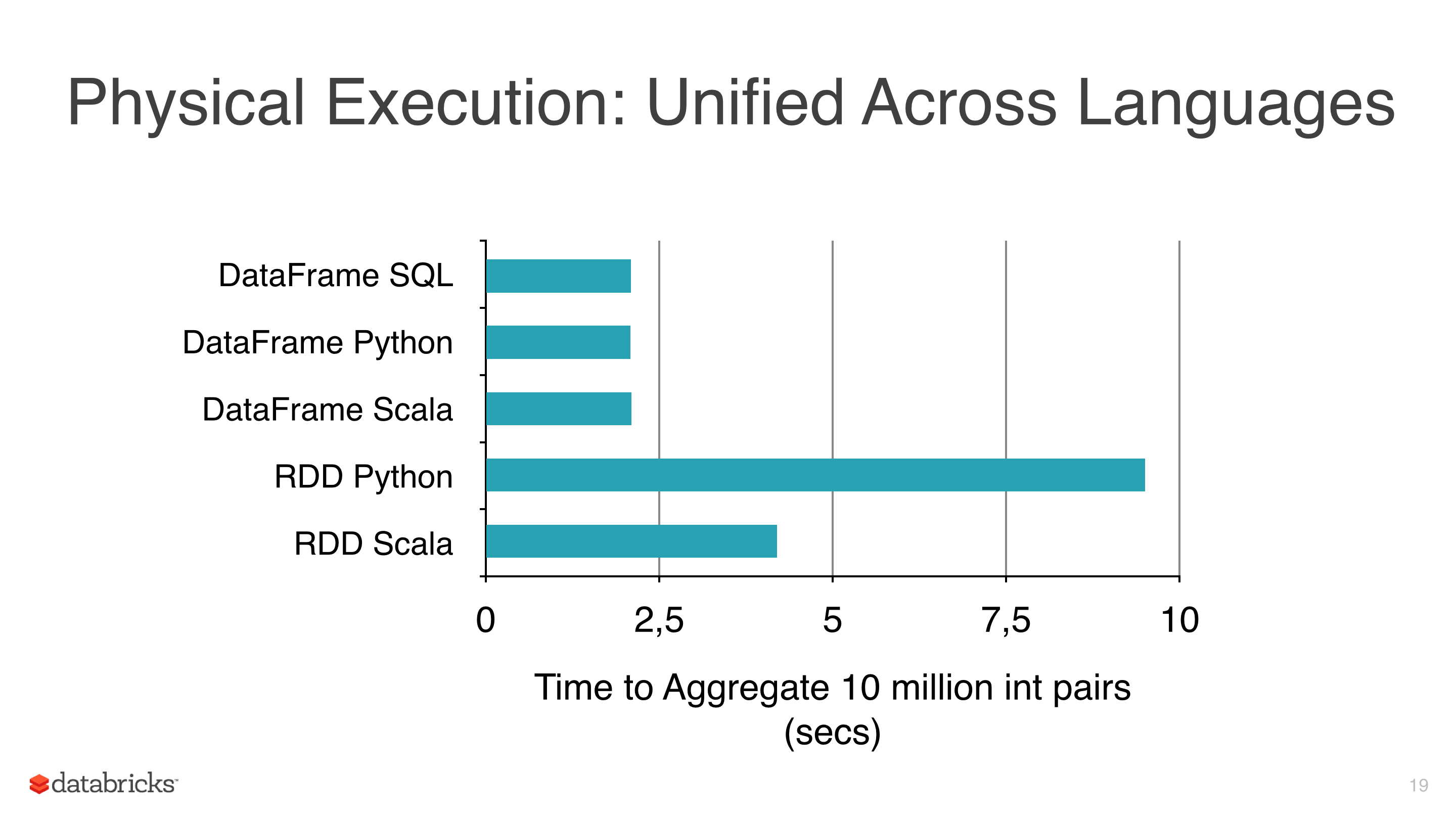
我正在将一些机器学习算法(如线性回归,Logistic回归和朴素贝叶斯)应用于某些数据,但我试图避免使用RDD并开始使用DataFrame,因为RDD比pyspark下的Dataframe 慢(见图1).
我使用DataFrames的另一个原因是因为ml库有一个非常有用的类来调整模型,CrossValidator这个类在拟合之后返回一个模型,显然这个方法必须测试几个场景,然后返回一个拟合的模型(与参数的最佳组合).
我使用的集群不是那么大,数据相当大,有些适合需要几个小时,所以我想保存这些模型以便以后重用它们,但我还没有意识到,有什么我忽略的东西?
笔记:
- mllib的模型类有一个保存方法(即NaiveBayes),但mllib没有CrossValidator并使用RDD,所以我有预谋地避免它.
- 目前的版本是spark 1.5.1.
23
推荐指数
推荐指数
2
解决办法
解决办法
2万
查看次数
查看次数
在非Spark环境中加载pyspark ML模型
我有兴趣在python中部署机器学习模型,因此可以通过对服务器的请求进行预测.
我将创建一个Cloudera集群,并利用Spark开发模型,使用库pyspark.我想知道如何保存模型以便在服务器上使用它.
我已经看到不同的算法具有.save函数(就像在本文中如何在Apache Spark中保存和加载MLLib模型一样),但是因为服务器将在没有Spark的不同机器中而不在Cloudera集群中,我不知道是否可以使用他们的.load和.predict函数.
可以通过使用pyspark库函数进行预测而不使用Spark吗?或者我是否必须进行任何转换才能保存模型并在其他地方使用它?
14
推荐指数
推荐指数
1
解决办法
解决办法
2900
查看次数
查看次数
在python中保存Apache Spark mllib模型
我正在尝试将拟合的模型保存到Spark中的文件中.我有一个Spark集群,它训练一个RandomForest模型.我想在另一台机器上保存并重复使用合适的模型.我在网上看了一些建议做java序列化的帖子.我在python中做了相同的操作,但它不起作用.诀窍是什么?
model = RandomForest.trainRegressor(trainingData, categoricalFeaturesInfo={},
numTrees=nb_tree,featureSubsetStrategy="auto",
impurity='variance', maxDepth=depth)
output = open('model.ml', 'wb')
pickle.dump(model,output)
我收到此错误:
TypeError: can't pickle lock objects
我正在使用Apache Spark 1.2.0.
6
推荐指数
推荐指数
1
解决办法
解决办法
4003
查看次数
查看次数