相关疑难解决方法(0)
保存ML模型以备将来使用
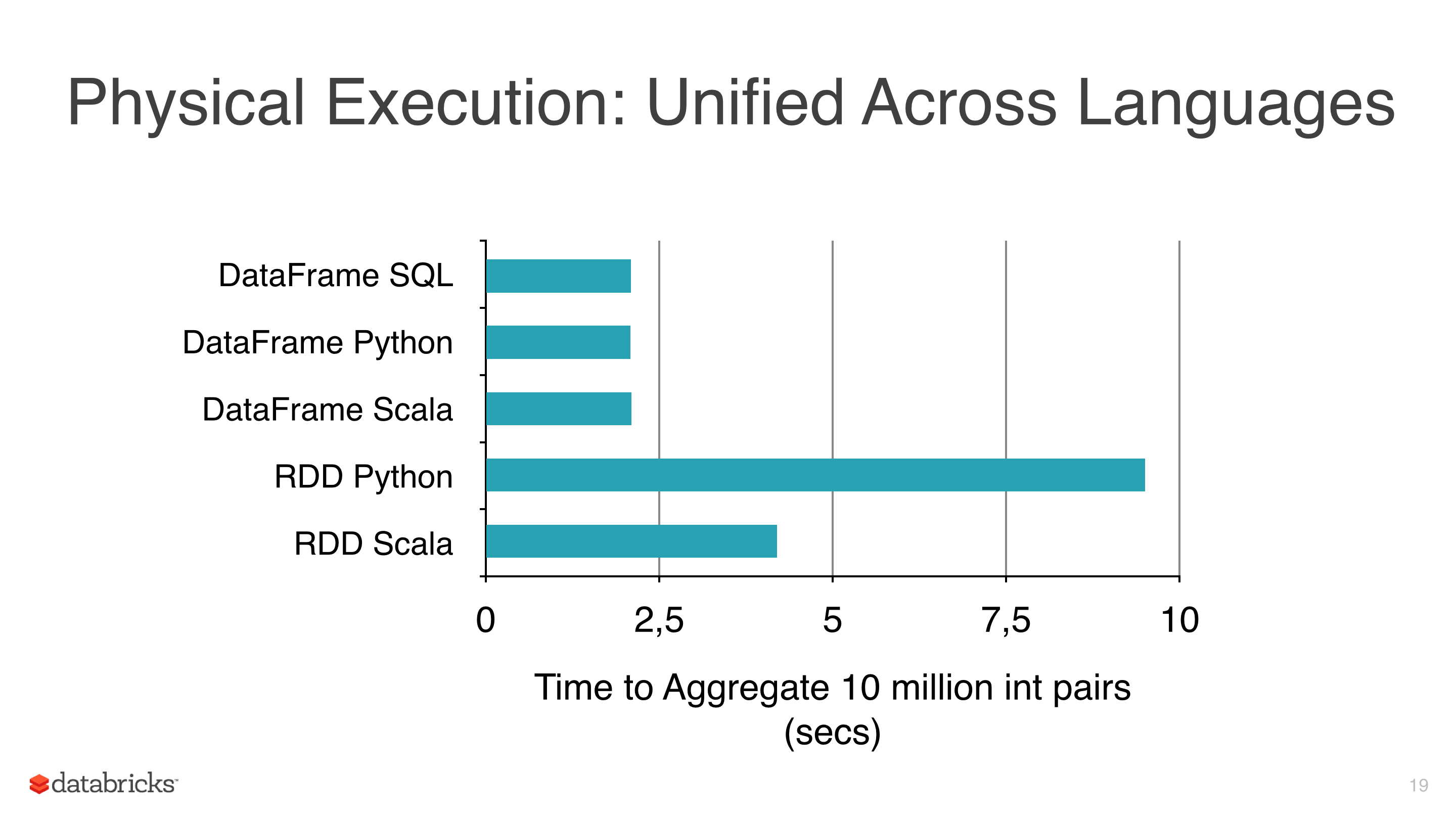
我正在将一些机器学习算法(如线性回归,Logistic回归和朴素贝叶斯)应用于某些数据,但我试图避免使用RDD并开始使用DataFrame,因为RDD比pyspark下的Dataframe 慢(见图1).
我使用DataFrames的另一个原因是因为ml库有一个非常有用的类来调整模型,CrossValidator这个类在拟合之后返回一个模型,显然这个方法必须测试几个场景,然后返回一个拟合的模型(与参数的最佳组合).
我使用的集群不是那么大,数据相当大,有些适合需要几个小时,所以我想保存这些模型以便以后重用它们,但我还没有意识到,有什么我忽略的东西?
笔记:
- mllib的模型类有一个保存方法(即NaiveBayes),但mllib没有CrossValidator并使用RDD,所以我有预谋地避免它.
- 目前的版本是spark 1.5.1.
推荐指数
解决办法
查看次数
在Spark\PySpark中保存\ load模型的正确方法是什么
我正在使用PySpark和MLlib使用Spark 1.3.0,我需要保存并加载我的模型.我使用这样的代码(取自官方文档)
from pyspark.mllib.recommendation import ALS, MatrixFactorizationModel, Rating
data = sc.textFile("data/mllib/als/test.data")
ratings = data.map(lambda l: l.split(',')).map(lambda l: Rating(int(l[0]), int(l[1]), float(l[2])))
rank = 10
numIterations = 20
model = ALS.train(ratings, rank, numIterations)
testdata = ratings.map(lambda p: (p[0], p[1]))
predictions = model.predictAll(testdata).map(lambda r: ((r[0], r[1]), r[2]))
predictions.collect() # shows me some predictions
model.save(sc, "model0")
# Trying to load saved model and work with it
model0 = MatrixFactorizationModel.load(sc, "model0")
predictions0 = model0.predictAll(testdata).map(lambda r: ((r[0], r[1]), r[2]))
在我尝试使用model0之后,我得到一个很长的回溯,结束于此:
Py4JError: An error occurred …推荐指数
解决办法
查看次数
使用Spark MLlib Scala API按组运行3000+随机森林模型
我正在尝试使用Spark Scala API在大型模型输入csv文件上按组(School_ID,超过3,000)构建随机森林模型.每组包含约3000-4000条记录.我拥有的资源是20-30 aws m3.2xlarge实例.
在R中,我可以按组构建模型并将它们保存到这样的列表中 -
library(dplyr);library(randomForest);
Rf_model <- train %>% group_by(School_ID) %>%
do(school= randomForest(formula=Rf_formula, data=., importance = TRUE))
列表可以存储在某个地方,我可以在需要使用它们时调用它们,如下所示 -
save(Rf_model.school,file=paste0(Modelpath,"Rf_model.dat"))
load(file=paste0(Modelpath,"Rf_model.dat"))
pred <- predict(Rf_model.school$school[school_index][[1]], newdata=test)
我想知道如何在Spark中做到这一点,无论我是否需要首先按组分割数据以及如何在必要时有效地进行分割.
我能够根据以下代码通过School_ID拆分文件,但似乎它为每次迭代创建了一个单独的作业子集,并且需要很长时间才能完成作业.有没有办法一次性完成?
model_input.cache()
val schools = model_input.select("School_ID").distinct.collect.flatMap(_.toSeq)
val bySchoolArray = schools.map(School_ID => model_input.where($"School_ID" <=> School_ID))
for( i <- 0 to programs.length - 1 ){
bySchoolArray(i).
write.format("com.databricks.spark.csv").
option("header", "true").
save("model_input_bySchool/model_input_"+ schools(i))
}
来源: 如何在SCALA和SPARK中将数据框拆分为具有相同列值的数据框
编辑8/24/2015 我正在尝试将我的数据帧转换为随机林模型接受的格式.我正在遵循此线程上的说明 如何在Spark ML中创建用于分类的正确数据帧
基本上,我创建了一个新变量"label"并将我的类存储在Double中.然后我使用VectorAssembler函数组合我的所有功能,并将我的输入数据转换如下 -
val assembler = new VectorAssembler().
setInputCols(Array("COL1", "COL2", "COL3")).
setOutputCol("features")
val model_input = assembler.transform(model_input_raw). …推荐指数
解决办法
查看次数