LSTM 'recurrent_dropout' 与 'relu' 产生 NaN
Ove*_*gon 3 numerical-stability lstm keras tensorflow
任何非零值recurrent_dropout都会产生 NaN 损失和权重;后者要么是 0,要么是 NaN。发生在堆叠、浅、stateful, return_sequences= 任何、带有 & w/o Bidirectional(), activation='relu', loss='binary_crossentropy'。NaN 发生在几个批次内。
有修复吗?感谢帮助。
尝试排除故障:
recurrent_dropout=0.2,0.1,0.01,1e-6kernel_constraint=maxnorm(0.5,axis=0)recurrent_constraint=maxnorm(0.5,axis=0)clipnorm=50(经验确定),Nadam 优化器activation='tanh'- 无 NaN,权重稳定,测试最多 10 个批次lr=2e-6,2e-5- 无 NaN,权重稳定,测试最多 10 个批次lr=5e-5- 3 个批次没有 NaN,权重稳定 - 第 4 批次有 NaNbatch_shape=(32,48,16)- 2 个批次损失较大,第 3 批次为 NaN
注意:每批次batch_shape=(32,672,16)17 次调用train_on_batch
环境:
- Keras 2.2.4(TensorFlow 后端)、Python 3.7、Spyder 3.3.7(通过 Anaconda)
- GTX 1070 6GB、i7-7700HQ、12GB 内存、Win-10.0.17134 x64
- CuDNN 10+,最新的 Nvidia 驱动器
附加信息:
模型发散是自发的,即使使用固定种子(Numpy、Random 和 TensorFlow 随机种子),也会在不同的训练更新时发生。此外,当第一次发散时,LSTM 层权重都是正常的 - 只是后来变为 NaN。
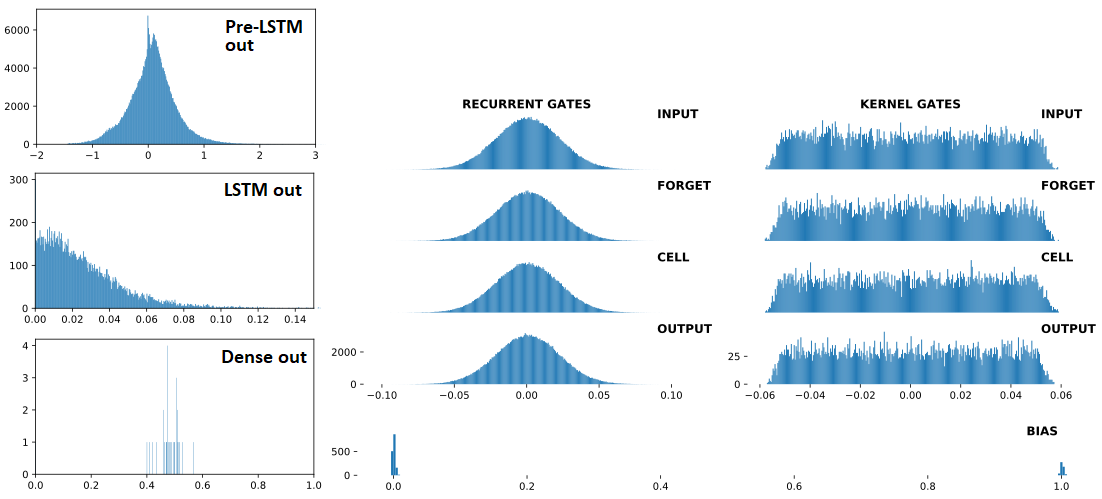
以下按顺序排列: (1) 输入LSTM; (2)LSTM输出;(3)Dense(1,'sigmoid')输出——三个是连续的,Dropout(0.5)每个之间都有。前面的(1)是Conv1D层。右:LSTM 权重。"BEFORE" = 1 次列车更新之前;“之后 = 1 次列车更新之后
分歧之前:
AT 发散:
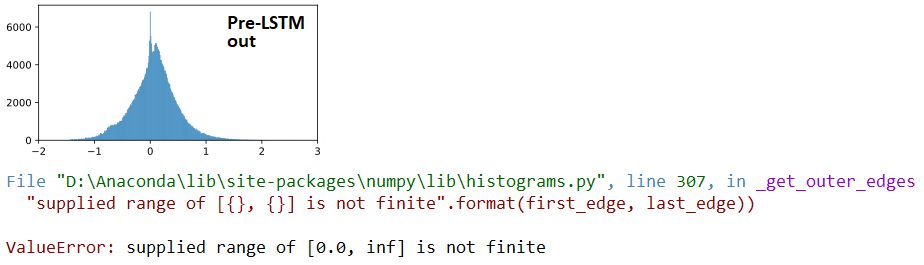
## LSTM outputs, flattened, stats
(mean,std) = (inf,nan)
(min,max) = (0.00e+00,inf)
(abs_min,abs_max) = (0.00e+00,inf)
分歧后:
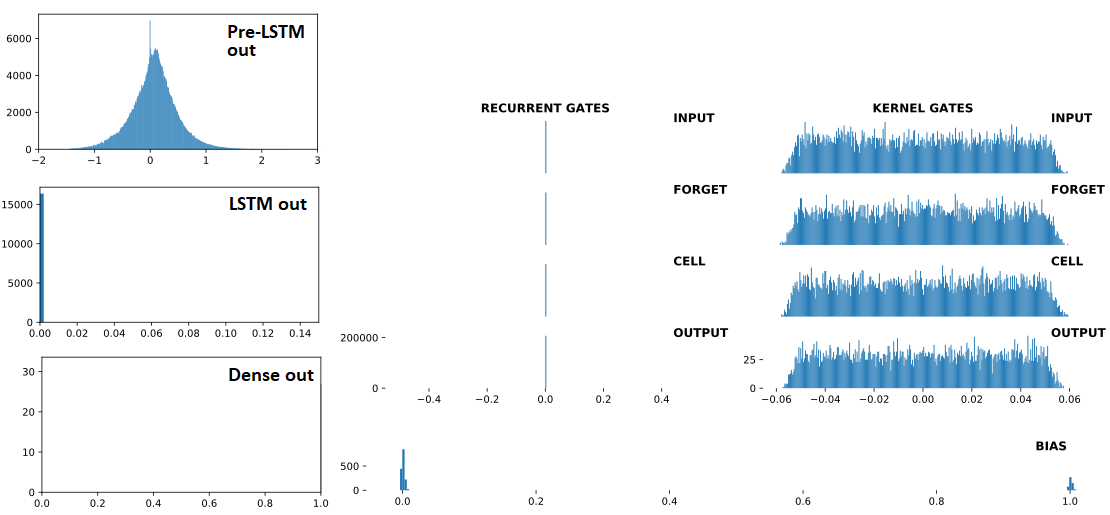
## Recurrent Gates Weights:
array([[nan, nan, nan, ..., nan, nan, nan],
[ 0., 0., -0., ..., -0., 0., 0.],
[ 0., -0., -0., ..., -0., 0., 0.],
...,
[nan, nan, nan, ..., nan, nan, nan],
[ 0., 0., -0., ..., -0., 0., -0.],
[ 0., 0., -0., ..., -0., 0., 0.]], dtype=float32)
## Dense Sigmoid Outputs:
array([[1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1.,
1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1.]], dtype=float32)
最小可重复示例:
from keras.layers import Input,Dense,LSTM,Dropout
from keras.models import Model
from keras.optimizers import Nadam
from keras.constraints import MaxNorm as maxnorm
import numpy as np
ipt = Input(batch_shape=(32,672,16))
x = LSTM(512, activation='relu', return_sequences=False,
recurrent_dropout=0.3,
kernel_constraint =maxnorm(0.5, axis=0),
recurrent_constraint=maxnorm(0.5, axis=0))(ipt)
out = Dense(1, activation='sigmoid')(x)
model = Model(ipt,out)
optimizer = Nadam(lr=4e-4, clipnorm=1)
model.compile(optimizer=optimizer,loss='binary_crossentropy')
for train_update,_ in enumerate(range(100)):
x = np.random.randn(32,672,16)
y = np.array([1]*5 + [0]*27)
np.random.shuffle(y)
loss = model.train_on_batch(x,y)
print(train_update+1,loss,np.sum(y))
观察:以下加速发散:
- 更高
units(LSTM) - 更高层数 (LSTM)
- 较高
lr<<时无分歧<=1e-4,测试了多达 400 个列车 - 更少的
'1'标签<<与下面没有分歧y,即使与lr=1e-3; 测试了多达 400 列火车
y = np.random.randint(0,2,32) # makes more '1' labels
更新:TF2 中未修复;也可以使用from tensorflow.keras进口来重现。
深入研究 LSTM 公式并深入研究源代码,一切都变得一目了然。
结论:recurrent_dropout与此无关;某件事在无人预料的地方循环。
真正的罪魁祸首:activation现在'relu',该论证应用于循环转换- 与几乎每个教程都将其视为无害的相反'tanh'。
即,不仅activation用于隐藏到输出的变换 - 源代码;它直接计算循环状态、单元格和隐藏状态:
c = f * c_tm1 + i * self.activation(x_c + K.dot(h_tm1_c, self.recurrent_kernel_c))
h = o * self.activation(c)

解决方案:
- 适用
BatchNormalization于 LSTM 的输入,特别是如果前一层的输出无界(ReLU、ELU 等)- 如果前一层的激活是紧密有界的(例如 tanh、sigmoid),则在激活之前应用 BN (使用
activation=None,然后是 BN,然后是Activation层)
- 如果前一层的激活是紧密有界的(例如 tanh、sigmoid),则在激活之前应用 BN (使用
- 使用
activation='selu'; 更稳定,但仍可能出现分歧 - 使用较低
lr - 应用渐变裁剪
- 使用更少的时间步长
对于一些剩余问题的更多答案:
- 为何被
recurrent_dropout怀疑?测试设置不细致;直到现在我才专注于在没有它的情况下强行发散。然而,它有时确实会加速发散——这可能是因为它将非 ReLU 贡献归零,否则会抵消乘性强化。 - 为什么非零均值输入会加速发散?加性对称性;非零均值分布是不对称的,有一个符号占主导地位 - 促进大量的预激活,从而产生大量的 ReLU。
- 为什么训练可以在低 lr 的情况下稳定数百次迭代?极端激活会通过大误差引起大梯度;如果 lr 较低,这意味着权重会进行调整以防止此类激活 - 而较高的 lr 会跳得太远太快。
- 为什么堆叠 LSTM 发散得更快?除了将 ReLU 馈送到自身之外,LSTM 还会馈送下一个 LSTM,然后下一个 LSTM 将 ReLU 的 ReLU 馈送到自己 --> fireworks。
2020 年 1 月 22 日更新:recurrent_dropout实际上可能是一个促成因素,因为它利用反向 dropout,在训练期间放大隐藏变换,缓解多个时间步长的不同行为。Git 问题在这里
| 归档时间: |
|
| 查看次数: |
1361 次 |
| 最近记录: |