什么是 hadoop(单节点和多节点)、spark-master 和 spark-worker?
我想了解以下术语:
hadoop(单节点和多节点) spark master spark worker namenode datanode
到目前为止我所理解的是 spark master 是作业执行者并处理所有 spark 工人。而 hadoop 是 hdfs(我们的数据所在的位置),spark 工作人员根据分配给他们的工作从中读取数据。如果我错了,请纠正我。
我也想了解namenode和datanode的作用。虽然我知道 namenode 的作用(拥有所有数据节点的元数据信息,最好只有一个,但也可以是两个),而数据节点可以是多个并拥有数据。
datanodes 是相同的 hadoop 节点吗?
星火架构:
Spark 使用master/worker 架构。有一个驱动程序与一个名为 master 的协调器进行对话,该协调器管理运行 executors 的 worker。

驱动程序和执行程序在它们自己的 Java 进程中运行。您可以在相同(水平集群)或单独的机器(垂直集群)或混合机器配置中运行它们。
节点只不过是物理机器。
Hadoop NameNode 和 DataNode:
高密度文件系统具有主/从架构。HDFS 集群由单个 NameNode 组成,NameNode 是一个主服务器,用于管理文件系统命名空间并管理客户端对文件的访问。此外,还有许多 DataNode,通常集群中的每个节点一个,用于管理连接到它们运行的节点的存储。HDFS 公开了一个文件系统命名空间,并允许将用户数据存储在文件中。在内部,文件被分成一个或多个块,这些块存储在一组 DataNode 中。NameNode 执行文件系统命名空间操作,如打开、关闭和重命名文件和目录。它还确定块到 DataNode 的映射。DataNode 负责处理来自文件系统客户端的读写请求。DataNode 还执行块的创建、删除、
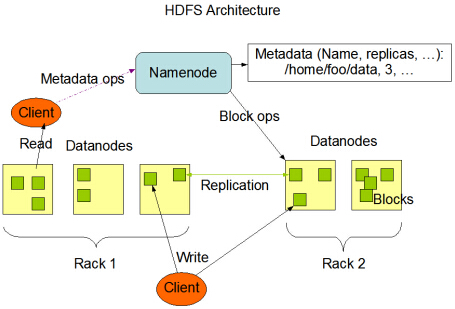
是的,DataNodes 是 Hadoop 集群中的从节点。
有关更多详细信息,请参阅文档。
- 使用 Spark 读写 HDFS 文件时,Spark 工作节点是否与 HDFS 数据节点相同? (3认同)
| 归档时间: |
|
| 查看次数: |
3895 次 |
| 最近记录: |