将ISIN解析为String
Ann*_*lee 2 regex statistics r
我想从一个非常奇怪的字符串解析ISIN,我的代码看起来像这样:
> df <- fread("C:/Users/WZHPCH/Desktop/Error Messages/df.csv", sep=";", stringsAsFactors=FALSE)
> dput(df)
structure(list(ID = c(1L, 2L, 4L, 2L, 3L, 24L), VAL = c("TES+XS0255015603+ae2s",
"TEST*XS0255015603+d2aasd", "safd*adf*XS0255015603++", "gasdfs*dsa*US0917971006",
"asdfsUS0917971006adf", "sd-asd-afds-US0917971006")), .Names = c("ID",
"VAL"), row.names = c(NA, -6L), class = c("data.table", "data.frame"
), .internal.selfref = <pointer: 0x0000000000110788>)
> df$parsedISIN <- gsub("^[a-zA-Z]{2}[0-9]{10}$", '\\1', df$VAL)
我对gsub做错了什么?
有什么建议?
感谢您的回复!
这里有一些问题:
1)即使使用的问题dput,对象中也有一个指针,因此它不能在其他系统上使用.我已经编辑出指针给出:
df <-
structure(list(ID = c(1L, 2L, 4L, 2L, 3L, 24L), VAL = c("TES+XS0255015603+ae2s",
"TEST*XS0255015603+d2aasd", "safd*adf*XS0255015603++", "gasdfs*dsa*US0917971006",
"asdfsUS0917971006adf", "sd-asd-afds-US0917971006")), .Names = c("ID",
"VAL"), row.names = c(NA, -6L), class = c("data.table", "data.frame"))
2)代码指的是df.gem$Attributes.它应该是df$VAL.
3)gsub应该是sub因为每个组件中只出现一次.
4)匹配仅匹配,如果它从字符串的开头开始并在字符串的结尾处结束,但如果它在字符串中就不匹配,这就是这里的情况.
5)要使用sub我们需要匹配所有内容,只需捕获我们需要的东西,以便我们可以排除我们不需要的东西.
试试这个:
pat <- ".*([a-zA-Z]{2}[0-9]{10}).*"
sub(pat, "\\1", df$VAL)
这使:
[1] "XS0255015603" "XS0255015603" "XS0255015603" "US0917971006" "US0917971006"
[6] "US0917971006"
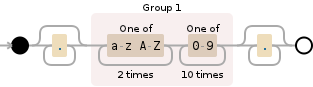
这是正则表达式的可视化,pat:
.*([a-zA-Z]{2}[0-9]{10}).*
注意:稍微简单的方法是使用strapplycin gsubfn直接提取模式.在这种情况下,正则表达式略有简化:
library(gsubfn)
strapplyc(df$VAL, "[a-zA-Z]{2}[0-9]{10}", simplify = TRUE)
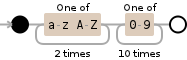
这是一个可视化:
[a-zA-Z]{2}[0-9]{10}
| 归档时间: |
|
| 查看次数: |
2795 次 |
| 最近记录: |