正则表达式中的星号
我正在尝试获取冒号之后的文本行部分。例如从这段文字
previous usc contact name:*assistant director of field education*
agency name:*development corporation
我想得到以下内容:
assistant director of field education
1010 development corporation
我尝试了以下正则表达式
.*:\*?(.*)\**$
它不起作用。现在正在工作的是:
.*:\*?(.*)\*
我不明白为什么它在没有星号的第二行工作,而正则表达式需要星号。我不明白为什么第一个正则表达式不能正常工作。
谢谢。
简而言之:
第二个正则表达式.*:\*?(.*)\*有效,因为:
.*正在匹配:
previous usc contact name和agency name
接下来是:\*(转义的*意思是: match *)。
(.*)\*最终匹配 EVERYHTING 直到 LAST *。
(假设您错过了最后一行中的星星,则此匹配:)
assistant director of field education和development corporation
从给出的示例中很难看出第一个正则表达式失败的原因。.*:\*?(.*)\**$意味着行尾必须为零或多个*( \**)
假设您的换行符如所提供,它只会匹配development corporation,因为锚点$(行结束)通常在单行模式下表示“字符串结束”。因此正则表达式只能匹配一次。如果将修饰符更改为多行模式(意味着$匹配每个\r\n而不是仅匹配字符串结尾)将为您提供所需的结果。
单线模式,匹配:
development corporation.*:\*?(.*)\**$
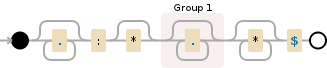
多行模式匹配:
assistant director of field education和development corporation.*:\*?(.*)\**$
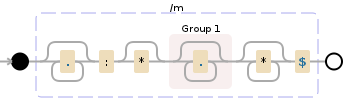
^和的行为$取决于修饰符:
给定字符串
Hello
World
并且^(.*)$在单行模式下使用将匹配Hello World. 在多行模式下使用相同的模式将在两个不同的匹配组中进行Hello匹配World。
在 SingleLine 中,字符串将由正则表达式引擎处理,例如
^Hello
World$
在多行模式下,引擎线程就像
^Hello$
^World$