Sql:优化BETWEEN子句
use*_*693 7 sql oracle oracle10g
我写了一个声明,花了差不多一个小时才能运行所以我在寻求帮助,所以我可以更快地做到这一点.所以我们走了:
我正在建立两个表的内部联接:
我有很多时间间隔由间隔表示,我想从这些间隔内的测量得到测量数据.
intervals:有两列,一列是开始时间,另一列是间隔的结束时间(行数= 1295)
measures:有两列,一列有度量,另一列有度量时间(行数=一百万)
我想得到的结果是一个表,在第一列中有度量,然后是度量完成的时间,考虑的时间间隔的开始/结束时间(对于时间在考虑范围内的行,它将重复)
这是我的代码:
select measures.measure as measure, measures.time as time, intervals.entry_time as entry_time, intervals.exit_time as exit_time
from
intervals
inner join
measures
on intervals.entry_time<=measures.time and measures.time <=intervals.exit_time
order by time asc
谢谢
Qua*_*noi 19
这是一个非常普遍的问题.
普通B-Tree索引不适合这样的查询:
SELECT measures.measure as measure,
measures.time as time,
intervals.entry_time as entry_time,
intervals.exit_time as exit_time
FROM intervals
JOIN measures
ON measures.time BETWEEN intervals.entry_time AND intervals.exit_time
ORDER BY
time ASC
索引适用于搜索给定边界内的值,如下所示:
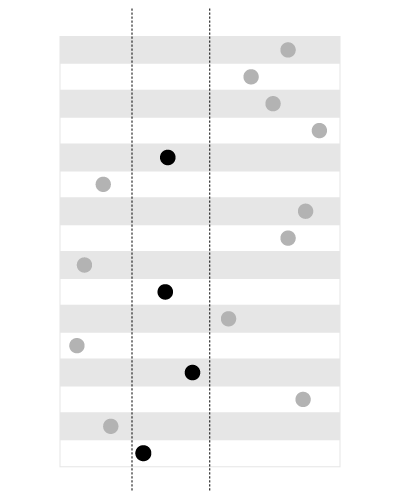
,但不是用于搜索包含给定值的边界,如下所示:
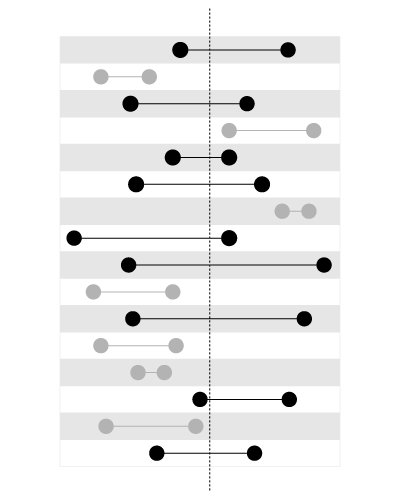
我的博客中的这篇文章更详细地解释了这个问题:
(嵌套集模型处理类似的谓词类型).
您可以启用索引time,这intervals将是连接中的前导,范围时间将在嵌套循环内使用.这将需要排序time.
您可以创建一个空间索引intervals(可用MySQL使用MyISAM的存储)将包括start和end在一个几何列.这样,measures可以引导连接,不需要排序.
但是,空间索引更慢,因此只有少量测量但间隔很多时才会有效.
由于您的间隔很少但有很多度量,因此请确保您有一个索引measures.time:
CREATE INDEX ix_measures_time ON measures (time)
更新:
这是一个要测试的示例脚本:
BEGIN
DBMS_RANDOM.seed(20091223);
END;
/
CREATE TABLE intervals (
entry_time NOT NULL,
exit_time NOT NULL
)
AS
SELECT TO_DATE('23.12.2009', 'dd.mm.yyyy') - level,
TO_DATE('23.12.2009', 'dd.mm.yyyy') - level + DBMS_RANDOM.value
FROM dual
CONNECT BY
level <= 1500
/
CREATE UNIQUE INDEX ux_intervals_entry ON intervals (entry_time)
/
CREATE TABLE measures (
time NOT NULL,
measure NOT NULL
)
AS
SELECT TO_DATE('23.12.2009', 'dd.mm.yyyy') - level / 720,
CAST(DBMS_RANDOM.value * 10000 AS NUMBER(18, 2))
FROM dual
CONNECT BY
level <= 1080000
/
ALTER TABLE measures ADD CONSTRAINT pk_measures_time PRIMARY KEY (time)
/
CREATE INDEX ix_measures_time_measure ON measures (time, measure)
/
这个查询:
SELECT SUM(measure), AVG(time - TO_DATE('23.12.2009', 'dd.mm.yyyy'))
FROM (
SELECT *
FROM (
SELECT /*+ ORDERED USE_NL(intervals measures) */
*
FROM intervals
JOIN measures
ON measures.time BETWEEN intervals.entry_time AND intervals.exit_time
ORDER BY
time
)
WHERE rownum <= 500000
)
使用NESTED LOOPS并在1.7几秒钟内返回.
这个查询:
SELECT SUM(measure), AVG(time - TO_DATE('23.12.2009', 'dd.mm.yyyy'))
FROM (
SELECT *
FROM (
SELECT /*+ ORDERED USE_MERGE(intervals measures) */
*
FROM intervals
JOIN measures
ON measures.time BETWEEN intervals.entry_time AND intervals.exit_time
ORDER BY
time
)
WHERE rownum <= 500000
)
使用MERGE JOIN,我必须在5几分钟后停止它.
更新2:
您很可能需要使用如下提示强制引擎在连接中使用正确的表顺序:
SELECT /*+ LEADING (intervals) USE_NL(intervals, measures) */
measures.measure as measure,
measures.time as time,
intervals.entry_time as entry_time,
intervals.exit_time as exit_time
FROM intervals
JOIN measures
ON measures.time BETWEEN intervals.entry_time AND intervals.exit_time
ORDER BY
time ASC
该Oracle的优化是不够聪明地看到,间隔不相交.这就是为什么它最有可能measures用作一个领先的表(如果间隔相交,这将是一个明智的决定).
更新3:
WITH splits AS
(
SELECT /*+ MATERIALIZE */
entry_range, exit_range,
exit_range - entry_range + 1 AS range_span,
entry_time, exit_time
FROM (
SELECT TRUNC((entry_time - TO_DATE(1, 'J')) * 2) AS entry_range,
TRUNC((exit_time - TO_DATE(1, 'J')) * 2) AS exit_range,
entry_time,
exit_time
FROM intervals
)
),
upper AS
(
SELECT /*+ MATERIALIZE */
MAX(range_span) AS max_range
FROM splits
),
ranges AS
(
SELECT /*+ MATERIALIZE */
level AS chunk
FROM upper
CONNECT BY
level <= max_range
),
tiles AS
(
SELECT /*+ MATERIALIZE USE_MERGE (r s) */
entry_range + chunk - 1 AS tile,
entry_time,
exit_time
FROM ranges r
JOIN splits s
ON chunk <= range_span
)
SELECT /*+ LEADING(t) USE_HASH(m t) */
SUM(LENGTH(stuffing))
FROM tiles t
JOIN measures m
ON TRUNC((m.time - TO_DATE(1, 'J')) * 2) = tile
AND m.time BETWEEN t.entry_time AND t.exit_time
此查询将时间轴拆分为范围,并使用a HASH JOIN连接范围值上的度量和时间戳,稍后进行精细过滤.
有关其工作原理的更详细说明,请参阅我的博客中的这篇文章:
我做的第一件事是让你的数据库工具生成一个你可以查看的执行计划(这是 MSSQL 中的“Control-L”,但我不知道如何在 Oracle 中做到这一点)——这将尝试指出缓慢的部分,根据您的服务器/编辑器,它甚至可能会推荐一些基本索引。一旦有了执行计划,您就可以查找内部循环连接的任何表扫描,这两者都非常慢 - 索引可以帮助进行表扫描,并且您可以添加额外的连接谓词来帮助减轻循环连接。
我的猜测是 MEASURES 需要 TIME 列上的索引,并且您也可以包含 MEASURE 列以加快查找速度。尝试这个:
CREATE INDEX idxMeasures_Time ON Measures ([Time]) INCLUDES (Measure)
另外,虽然这不会改变您的执行计划或加快查询速度,但它可能会使您的 join 子句更容易阅读:
ON measures.time BETWEEN intervals.entry_time AND intervals.exit_time
这只是将两个 <= 和 >= 组合成一个语句。