Python将numpy数组插入sqlite3数据库
Joe*_*lip 27 python sqlite numpy
我正在尝试在sqlite3数据库中存储大约1000个浮点数的numpy数组,但我不断收到错误"InterfaceError:Error binding parameter 1 - 可能不支持的类型".
我的印象是BLOB数据类型可能是任何东西,但它肯定不适用于numpy数组.这是我试过的:
import sqlite3 as sql
import numpy as np
con = sql.connect('test.bd',isolation_level=None)
cur = con.cursor()
cur.execute("CREATE TABLE foobar (id INTEGER PRIMARY KEY, array BLOB)")
cur.execute("INSERT INTO foobar VALUES (?,?)", (None,np.arange(0,500,0.5)))
con.commit()
我可以使用另一个模块将numpy数组放入表中吗?或者我可以将numpy数组转换为Python中的另一种形式(如我可以拆分的列表或字符串),sqlite会接受吗?绩效不是优先事项.我只是想让它起作用!
谢谢!
unu*_*tbu 39
您可以使用以下命令注册新array数据类型sqlite3:
import sqlite3
import numpy as np
import io
def adapt_array(arr):
"""
http://stackoverflow.com/a/31312102/190597 (SoulNibbler)
"""
out = io.BytesIO()
np.save(out, arr)
out.seek(0)
return sqlite3.Binary(out.read())
def convert_array(text):
out = io.BytesIO(text)
out.seek(0)
return np.load(out)
# Converts np.array to TEXT when inserting
sqlite3.register_adapter(np.ndarray, adapt_array)
# Converts TEXT to np.array when selecting
sqlite3.register_converter("array", convert_array)
x = np.arange(12).reshape(2,6)
con = sqlite3.connect(":memory:", detect_types=sqlite3.PARSE_DECLTYPES)
cur = con.cursor()
cur.execute("create table test (arr array)")
使用此设置,您只需插入NumPy数组,而无需更改语法:
cur.execute("insert into test (arr) values (?)", (x, ))
并直接从sqlite检索数组作为NumPy数组:
cur.execute("select arr from test")
data = cur.fetchone()[0]
print(data)
# [[ 0 1 2 3 4 5]
# [ 6 7 8 9 10 11]]
print(type(data))
# <type 'numpy.ndarray'>
- 这对我很有用.只是为了清楚其他人,必须使用选项detect_types = sqlite3.PARSE_DECLTYPES打开连接我遇到了麻烦,因为我忘了保留它. (8认同)
小智 7
我认为这种matlab格式是存储和检索numpy数组的一种非常方便的方法.真的很快,磁盘和内存占用量也差不多.
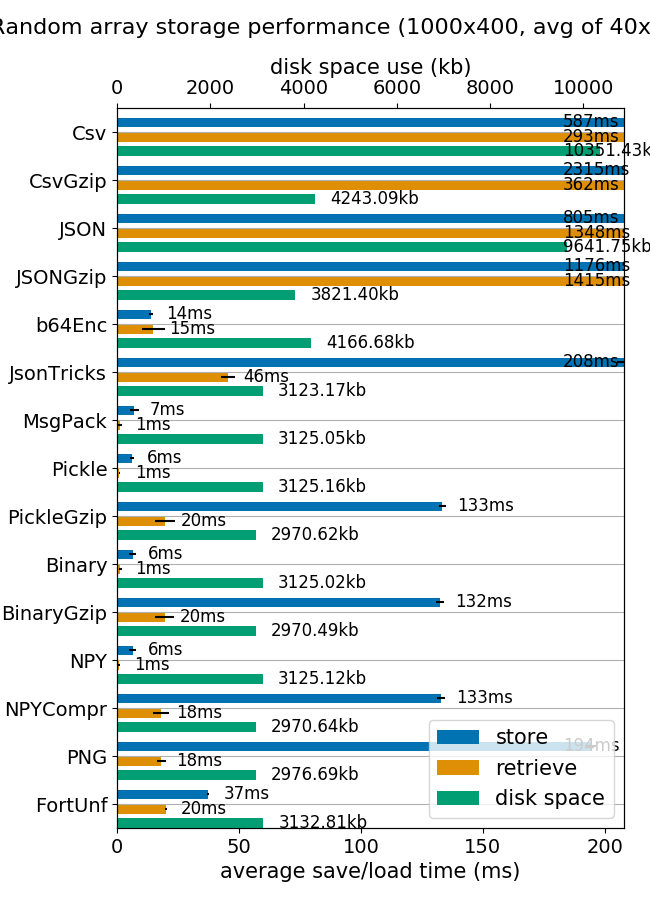
(来自mverleg基准的图片)
但是如果出于任何原因需要将numpy数组存储到SQLite中,我建议添加一些压缩功能.
来自unutbu代码的额外线条非常简单
compressor = 'zlib' # zlib, bz2
def adapt_array(arr):
"""
http://stackoverflow.com/a/31312102/190597 (SoulNibbler)
"""
# zlib uses similar disk size that Matlab v5 .mat files
# bz2 compress 4 times zlib, but storing process is 20 times slower.
out = io.BytesIO()
np.save(out, arr)
out.seek(0)
return sqlite3.Binary(out.read().encode(compressor)) # zlib, bz2
def convert_array(text):
out = io.BytesIO(text)
out.seek(0)
out = io.BytesIO(out.read().decode(compressor))
return np.load(out)
使用MNIST数据库进行的结果测试得出:
$ ./test_MNIST.py
[69900]: 99% remain: 0 secs
Storing 70000 images in 379.9 secs
Retrieve 6990 images in 9.5 secs
$ ls -lh example.db
-rw-r--r-- 1 agp agp 69M sep 22 07:27 example.db
$ ls -lh mnist-original.mat
-rw-r--r-- 1 agp agp 53M sep 20 17:59 mnist-original.mat
```
使用zlib和
$ ./test_MNIST.py
[69900]: 99% remain: 12 secs
Storing 70000 images in 8536.2 secs
Retrieve 6990 images in 37.4 secs
$ ls -lh example.db
-rw-r--r-- 1 agp agp 19M sep 22 03:33 example.db
$ ls -lh mnist-original.mat
-rw-r--r-- 1 agp agp 53M sep 20 17:59 mnist-original.mat
运用 bz2
将Matlab V5格式与bz2SQLite 进行比较,bz2压缩大约为2.8,但与Matlab格式相比,访问时间相当长(几乎是瞬间,超过30秒).也许仅适用于真正庞大的数据库,其中学习过程比访问时间或数据库占用空间尽可能小的时间要长得多.
最后请注意,bipz/zlib比率约为3.7,zlib/matlab需要的空间增加30%.
如果你想玩自己的完整代码是:
import sqlite3
import numpy as np
import io
compressor = 'zlib' # zlib, bz2
def adapt_array(arr):
"""
http://stackoverflow.com/a/31312102/190597 (SoulNibbler)
"""
# zlib uses similar disk size that Matlab v5 .mat files
# bz2 compress 4 times zlib, but storing process is 20 times slower.
out = io.BytesIO()
np.save(out, arr)
out.seek(0)
return sqlite3.Binary(out.read().encode(compressor)) # zlib, bz2
def convert_array(text):
out = io.BytesIO(text)
out.seek(0)
out = io.BytesIO(out.read().decode(compressor))
return np.load(out)
sqlite3.register_adapter(np.ndarray, adapt_array)
sqlite3.register_converter("array", convert_array)
dbname = 'example.db'
def test_save_sqlite_arrays():
"Load MNIST database (70000 samples) and store in a compressed SQLite db"
os.path.exists(dbname) and os.unlink(dbname)
con = sqlite3.connect(dbname, detect_types=sqlite3.PARSE_DECLTYPES)
cur = con.cursor()
cur.execute("create table test (idx integer primary key, X array, y integer );")
mnist = fetch_mldata('MNIST original')
X, y = mnist.data, mnist.target
m = X.shape[0]
t0 = time.time()
for i, x in enumerate(X):
cur.execute("insert into test (idx, X, y) values (?,?,?)",
(i, y, int(y[i])))
if not i % 100 and i > 0:
elapsed = time.time() - t0
remain = float(m - i) / i * elapsed
print "\r[%5d]: %3d%% remain: %d secs" % (i, 100 * i / m, remain),
sys.stdout.flush()
con.commit()
con.close()
elapsed = time.time() - t0
print
print "Storing %d images in %0.1f secs" % (m, elapsed)
def test_load_sqlite_arrays():
"Query MNIST SQLite database and load some samples"
con = sqlite3.connect(dbname, detect_types=sqlite3.PARSE_DECLTYPES)
cur = con.cursor()
# select all images labeled as '2'
t0 = time.time()
cur.execute('select idx, X, y from test where y = 2')
data = cur.fetchall()
elapsed = time.time() - t0
print "Retrieve %d images in %0.1f secs" % (len(data), elapsed)
if __name__ == '__main__':
test_save_sqlite_arrays()
test_load_sqlite_arrays()
这对我有用:
import sqlite3 as sql
import numpy as np
import json
con = sql.connect('test.db',isolation_level=None)
cur = con.cursor()
cur.execute("DROP TABLE FOOBAR")
cur.execute("CREATE TABLE foobar (id INTEGER PRIMARY KEY, array BLOB)")
cur.execute("INSERT INTO foobar VALUES (?,?)", (None, json.dumps(np.arange(0,500,0.5).tolist())))
con.commit()
cur.execute("SELECT * FROM FOOBAR")
data = cur.fetchall()
print data
data = cur.fetchall()
my_list = json.loads(data[0][1])
指定的其他方法对我不起作用。好吧,现在似乎有一个numpy.tobytes方法和一个numpy.fromstring(适用于字节字符串)但已弃用,推荐的方法是numpy.frombuffer.
import sqlite3
import numpy as np
sqlite3.register_adapter(np.array, adapt_array)
sqlite3.register_converter("array", convert_array)
来到肉和土豆,
def adapt_array(arr):
return arr.tobytes()
def convert_array(text):
return np.frombuffer(text)
我在我的应用程序测试,它很适合我在Python 3.7.3和numpy 1.16.2
numpy.fromstring 给出相同的输出以及 DeprecationWarning: The binary mode of fromstring is deprecated, as it behaves surprisingly on unicode inputs. Use frombuffer instead
Happy Leap Second快结束了,但我一直在自动进行字符串转换。另外,如果您查看另一篇文章:关于使用缓冲区或二进制将非文本数据推入sqlite的有趣辩论,您会发现记录在案的方法是避免全部使用缓冲区,并使用此代码块。
def adapt_array(arr):
out = io.BytesIO()
np.save(out, arr)
out.seek(0)
return sqlite3.Binary(out.read())
我尚未在python 3中对此进行大量测试,但它似乎在python 2.7中有效
| 归档时间: |
|
| 查看次数: |
21266 次 |
| 最近记录: |