我读了一些关于卷积神经网络的书籍和文章,似乎我理解了这个概念,但我不知道如何把它放在下面的图片中: alt text http://what-when-how.com/wp-内容/上传/ 2012/07/tmp725d63_thumb.png
从28x28标准化像素INPUT,我们得到4个大小为24x24的特征图.但如何得到它们?调整INPUT图像的大小?或执行图像转换?但是什么样的转变?或者将输入图像分成4个大小为24x24的4个角?我不明白这个过程,对我来说,似乎他们在每一步都将图像剪切或调整为较小的图像.请帮助谢谢.
我使用OpenCV中的letter_regcog示例,它使用了UCI的数据集,其结构如下:
Attribute Information:
1. lettr capital letter (26 values from A to Z)
2. x-box horizontal position of box (integer)
3. y-box vertical position of box (integer)
4. width width of box (integer)
5. high height of box (integer)
6. onpix total # on pixels (integer)
7. x-bar mean x of on pixels in box (integer)
8. y-bar mean y of on pixels in box (integer)
9. x2bar mean x variance (integer)
10. y2bar mean y variance (integer)
11. xybar … 模板代码是这样的:
template <class type1>
struct DefaultInstanceCreator {
type1 * operator ()() {
return new type1;
}
};
template < class type1
, class InstanceCreator = DefaultInstanceCreator<type1> >
class objectCache
{
public:
objectCache (InstanceCreator & instCreator)
:instCreator_ (instCreator) {}
type1* Get() {
type1 * temp = instCreator_ ();
}
private:
InstanceCreator instCreator_;
};
这段代码适用于像这样的对象类:
class A{
public:
A(int num){
number = num;
}
int number;
struct CreateInstance {
CreateInstance (int value) : value_ (value) {}
A * operator ()() const{
return …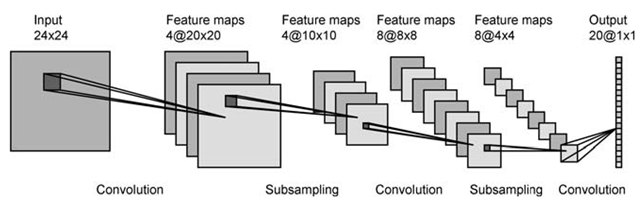{kind=link}