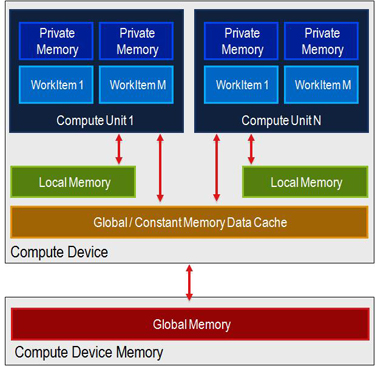
每个GPU设备(AMD,NVidea或任何其他设备)被分成几个计算单元(MultiProcessors),每个计算单元具有固定数量的核心(VertexShaders/StreamProcessors).因此,有一个(Compute Units) x (VertexShaders/compute unit)同时具有计算机的处理器,但__local每个多处理器只有少量固定数量的内存(通常为16KB或32KB).因此,这些多处理器的确切数量很重要.
现在我的问题:
CL_DEVICE_MAX_COMPUTE_UNITS吗?我可以从规格表中推断出它,例如http://en.wikipedia.org/wiki/Comparison_of_AMD_graphics_processing_units吗?__local在购买之前,我怎么知道GPU上每个MP有多少内存?当然我可以CL_DEVICE_LOCAL_MEM_SIZE在运行它的计算机上请求,但我不知道如何从单独的详细规格表中推断出它,例如http://www.amd.com/us/products/desktop/graphics/ 7000/7970/Pages/radeon-7970.aspx#3?CL_DEVICE_LOCAL_MEM_SIZE?价格并不重要,但64KB(或更大)会为我正在编写的应用程序带来明显的好处,因为我的算法是完全可并行化的,但也是高度内存密集型的,每个MP内部都有随机访问模式(迭代边缘)图表).我想创建一个接口,强制实现它的每个类具有某个功能,用于实现的类的类型.
所以说我有类MyClassA,MyClassB,MyClassC等都需要一个自己类型的函数:
在MyClassA中:
public class MyClassA implements MyClass {
MyClassA function(MyClassA x) {
doSomethingImplementedInMyClassA(x);
}
}
在MyClassB中:
public class MyClassB implements MyClass {
MyClassB function(MyClassB x) {
doSomethingImplementedInMyClassB(x);
}
}
问题是,如何编写接口MyClass以要求这样的功能?
public interface MyClass {
MyClass function(MyClass x);
}
显然不起作用,因为返回类型是MyClass而不是它的实现.如何在Java中正确地做到这一点?
我正在寻找将给定集合划分为不相交子集的代码.例如,一组足球运动员,我们根据他们所属的球队对他们进行分区.我最终想要一份代表名单,即每队的一名球员.
所有足球运动员都了解球队中的所有其他球员 - 这与复杂性非常相关.所以,我目前关于如何做到这一点的想法如下(set目前在哪里LinkedHashSet<T>):
while (!set.isEmpty()) {
E e = set.iterator().next();
makeRepresentative(e);
set.remove(AllPlayersOnSameTeamAs(e));
}
但是,在while循环的每个步骤中构建一个新的迭代器感觉很奇怪.LinkedHashSet应该在firstElement()内部具有某种功能(对于其LinkedList行为),但由于某种原因我无法找到如何执行此操作.我也试过了一个foreach循环,但结果是一个java.util.ConcurrentModificationException.
我该如何正确地做到这一点?
我正在写一个网页(PHP/HTML/CSS),我想,让我的用户输入大量的数据,总是由同一个信息:day,hour,title,details,class.为此,我需要一个<table>带<input>字段,但附加功能看起来像电子表格,并且用户可以复制粘贴(块)行并移动行,因为它们通常需要输入大量的类似的数据.
如果我不得不从头开始写这篇文章,我想重新发明轮子.我最好怎么做?是否有任何标准包(例如在javascript中)允许这样的功能?
注意:我不需要任何电子表格功能(公式等),只需复制/粘贴/移动输入.因此,完整的电子表格包可能会过度使用,也会使界面变得混乱.
我正在尝试理解诸如GPU之类的OpenCL设备的体系结构,但我不明白为什么本地工作组中的工作项数量存在明确限制,即常量CL_DEVICE_MAX_WORK_GROUP_SIZE.
在我看来,这应该由编译器来处理,即如果一个(简单的一维)内核用本地工作组大小500执行,而它的物理最大值是100,并且内核看起来像这样:
__kernel void test(float* input) {
i = get_global_id(0);
someCode(i);
barrier();
moreCode(i);
barrier();
finalCode(i);
}
然后它可以自动转换为此内核上工作组大小为100的执行:
__kernel void test(float* input) {
i = get_global_id(0);
someCode(5*i);
someCode(5*i+1);
someCode(5*i+2);
someCode(5*i+3);
someCode(5*i+4);
barrier();
moreCode(5*i);
moreCode(5*i+1);
moreCode(5*i+2);
moreCode(5*i+3);
moreCode(5*i+4);
barrier();
finalCode(5*i);
finalCode(5*i+1);
finalCode(5*i+2);
finalCode(5*i+3);
finalCode(5*i+4);
}
但是,似乎默认情况下不会这样做.为什么不?有没有办法让这个过程自动化(除了自己编写预编译器)?或者是否有一个固有的问题可以使我的方法在某些例子上失败(你能给我一个)吗?
我想为GPU编写一个程序(最好是OpenCL),大部分计算包括计算位数组中的1的数量(打包为long或int).
因此,在现代CPU上,我显然只使用本机__popcnt指令.我在互联网上的几个地方读到了现代GPU,这个指令也存在于硬件中,对我来说这将是一个巨大的加速.(至少32位,不确定64位)
但是,我发现如何使用这条指令.所以:
1)我应该如何找出哪个GPU有这个指令?(我仍然需要购买我的GPU,因此它将是一款现代高端产品......可能是Radeon HD7000系列或nVidia Kepler)
2)如何从OpenCL(或类似的GPU语言)调用此指令?
我正在尝试TensorFlow而且我遇到了一个奇怪的错误.我编辑了深度MNIST示例以使用另一组图像,并且算法再次很好地收敛,直到迭代8000(当时的精度为91%),当它崩溃时出现以下错误.
tensorflow.python.framework.errors.InvalidArgumentError: ReluGrad input is not finite
起初我认为可能有些系数达到浮点数的极限,但在所有权重和偏差上加上l2正则化并没有解决问题.它总是第一个来自堆栈跟踪的relu应用程序:
h_conv1 = tf.nn.relu(conv2d(x_image, W_conv1) + b_conv1)
我现在只在CPU上工作.知道是什么原因造成的,以及如何解决这个问题?
编辑:我追溯到这个问题Tensorflow NaN bug?,解决方案有效.
我打算购买一个严肃的GPU来运行并行算法(预算2k-4k).现在我看到所有超级计算机都采用了nVidia Tesla GPU卡"专为GPGPU制造".
虽然这看起来非常好看,但更好的阅读让我对此有了认真的思考:与Radeon HD 7970相比,它的性能(以触发器而言)显着降低,其成本价格显着提高,而且似乎无法找到特斯拉和普通游戏GPU之间的任何基准比较.
我发现特斯拉具有ECC内存功能.这是唯一的区别吗?或者我错过了两者之间更深层次的架构差异?也许相关信息:我将使用OpenCL,而不是Cuda.
在http://www.w3schools.com/cssref/playit.asp?filename=playcss_ol_list-style-type&preval=none上,为不同的list-style-type值提供了一个很好的概述.
但是,对于该值none,它仍为空列表符号保留一些水平空间.有没有办法删除这个水平间距,以便文本实际上向左移动,就好像它没有列表?我想text-align:center在列表项上使用,这个水平间距使它们不是真正居中.我需要使用,<ul>因为CMS以这种方式带来了它.
基本上,默认情况下list-style-type:none做一个visibility:hidden子弹,而我想display:none在子弹上实现.这样做的正确方法是什么?
opencl ×5
gpgpu ×2
html ×2
java ×2
architecture ×1
copy-paste ×1
css ×1
generics ×1
gpu ×1
input ×1
interface ×1
iterator ×1
spreadsheet ×1
tensorflow ×1
tesla ×1
{kind=link}