是否有可能为无形'创建一个HList看起来如下的提取器.
val a ~ _ ~ b = 4 :: "so" :: 4.5 :: HNil
=> a == 4 && b == 4.5
::为~,这应该不是问题.HNil.有没有可能出现的问题?经过多少汗水和泪水,我设法到达了以下代码的工作点:
for(
x1 :: _ :: x2 :: HNil <- (expInt ~ "+" ~ expInt).llE
) yield (x1 + x2)
expInt解析Int一些monad E.类型(expInt ~ "+" ~ expInt).llE是E[Int :: String :: Int :: HNil].
我希望左边的模式在<-某种程度上类似于右边的组合子解析器的构造.
在我的函数内部,我通过用数据填充新的可变HashMap来构造结果集(如果有更好的方法 - 我很感激评论).然后我想将结果集作为不可变的HashMap返回.如何从变量中导出一个不可变的?
我目前正在广泛使用类型类模式作为我的代码中与性能相关的部分.我发现了至少两个潜在的低效率来源.
隐式参数将通过消息调用传递.我不知道这是否真的发生了.也许scalac可以简单地在使用它们的地方插入隐式参数,并从方法签名中删除它们.在手动插入隐式参数的情况下,这可能是不可能的,因为它们可能仅在运行时解析.传递隐式参数有哪些优化适用?
如果类型类实例由a提供def(与a 相反val),则必须在每次调用"类型分类方法"时重新创建对象.JVM可能会解决此问题,这可能会优化对象创建.scalac也可以通过重用这些对象来解决这个问题.有关创建隐式参数对象的优化是什么?
当然,在应用类型类模式时可能还有其他低效率来源.请告诉我他们.
摘要选项卡上的Jvisualvm堆转储具有按保留大小检查bigest对象的功能.
保留的真正含义是什么?如何计算和显示对象树的大小?
如果我可以在这里看到对象(10M)和它的成员对象(5M)我应该如何计算堆影响.他们俩都花了10M或15M的堆?
为什么我看不到任何外观巨大的应用程序对象?
谢谢.
一般的问题是除了计算的实际结果之外,如何从方法返回附加信息.但我想,这些信息可以默默地被忽略.
就拿方法dropWhile上Iterator.返回的结果是变异的迭代器.但也许有时我可能会对丢弃的元素数量感兴趣.
在这种情况下dropWhile,可以通过向迭代器添加索引并计算之后丢弃的步骤数来在外部生成此信息.但总的来说这是不可能的.
我简单的解决方案是返回一个包含实际结果和可选信息的元组.但是每当我调用方法时我都需要处理元组 - 即使我对可选信息不感兴趣.
所以问题是,是否有一些聪明的方式来收集这些可选信息?
也许通过Option[X => Unit]带有回调函数的参数默认为None?有更聪明的东西吗?
使用 C++17,我有一个方法,该function方法采用带有必须是引用的参数的 a 。现在,当我传递采用非引用参数的 lambda 时,我不会收到编译错误。我希望这种情况不能编译。
我怎样才能实现这个目标?另外,哪个隐式转换会启动并导致非预期的代码编译?
#include <iostream>
#include <functional>
using namespace std;
void
takesRefLambda (function < void (string & t) > f)
{
string test = "nope";
f (test);
cout << test << endl;
}
int
main ()
{
//this shall fail at compile time, as parameter `q` is not a reference
takesRefLambda ([&](string q)
{
q = "yep1";
});
//this shall compile
takesRefLambda ([&](string & q)
{
q = "yep2";
});
return 0;
}
我正在尝试将两个BitSet对象添加到一起(改变其中一个).这应该是位集的有效操作.但似乎唯一的做法就是这样做++=.查看源代码,这似乎不会以不同方式添加bitset.
是的,在Scala 2.9.1中,对可变位集定义了没有有效的逻辑更新操作吗?这是毫无意义的,不是吗?
功能反应编程是一种以纯函数方式指定副作用程序的方法.
最近我一直在使用rxscala,它是ReactiveX的Java/Scala端口.它基于Observables 的概念,可以被视为某种类型的值流.
对于这个问题,我想排除处理时间连续变化(信号)的FRP方法.
可以使用大量不同的函数组合这些Observable来创建新的可观察对象.这些类似于可应用于集合的函数.而这些都已经相当很好理解,因为我们知道Foldable,Traversable,Applicative,Monads等.
事实上,可观察物是可折叠的,可穿越的单子,就像普通的收藏品一样.但是这些特征可以通过多种方式实现为可观察对象,因为可观察对象比普通集合拥有更多的信息(每个元素的定时信息).结果还必须配备定时信息.
例如,monadic join(flatMap在Scala中)可以以至少两种不同的,合理的方式实现:
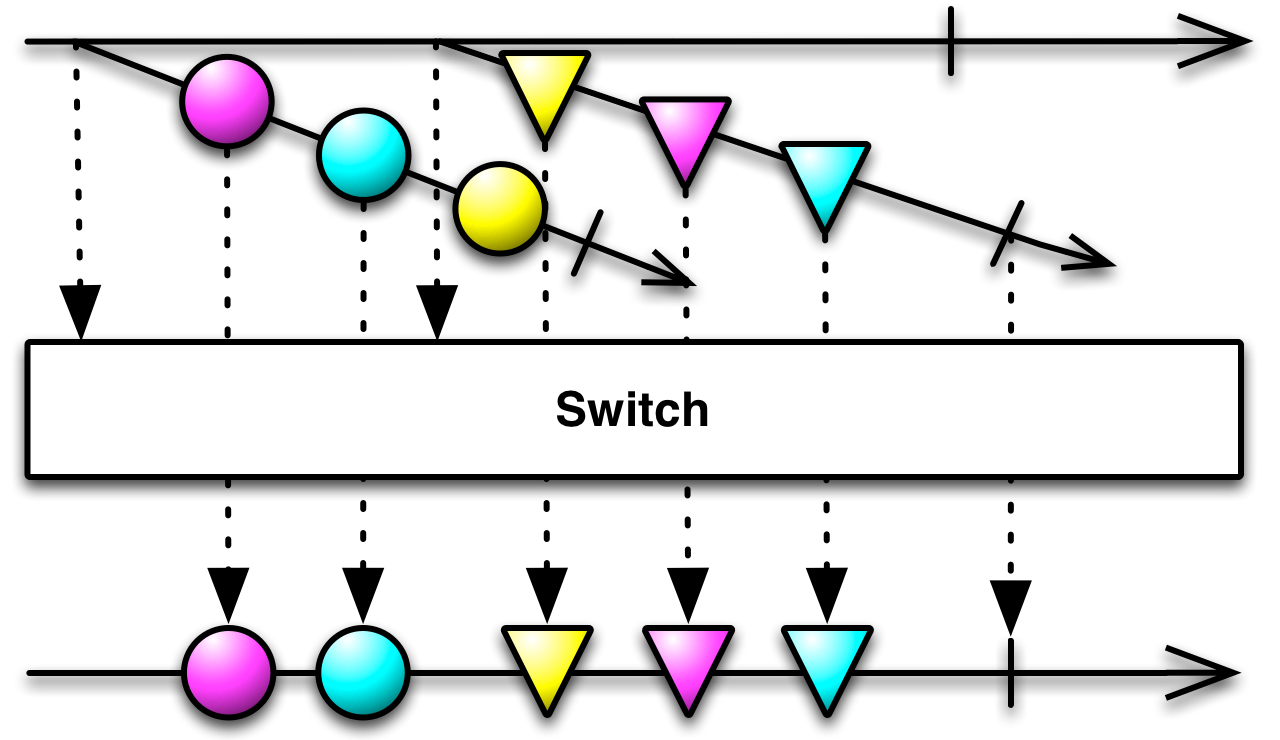
由switch嵌套可观测量,这导致截断当前活动的可观察到的,一旦下一个开始发射,或荷兰国际集团之间
RxJava Switch Visualization http://reactivex.io/documentation/operators/images/switch.c.png
通过merge嵌套的observable而不丢弃或延迟任何事件.
RxJava合并可视化http://reactivex.io/documentation/operators/images/mergeDelayError.C.png
......还有更多(见评论)
我对所提供的组合函数库非常满意,但我一直遇到无法实现我想要的情况,我不得不回到某种并发编程.
现在我想知道使用现有的组合器构建所需的行为是否太愚蠢了.或者是rxscala中可用的组合函数不足以创建所有可以想象的行为?
我要求证明一些基本的组合函数B足以从一些输入可观察量创建"每个可想象的可观察的".
可能最困难的部分可能是"每个可想象的可观察"的定义.也许Haskell社区已经产生了这样的东西?
haskell functional-programming reactive-programming system.reactive rx-java
我目前正在使用IDEA的构建机制和fsc一起使用Scala进行开发.它仍然有点慢,不得不(重新)启动编译服务器是一件痛苦的事.这里有很多人建议将SBT与IDEA一起作为构建工具.
您如何看待每种方法的优缺点?
{kind=link}
{kind=link}