小编vik*_*sit的帖子
Python!=操作vs"不是"
在对这个问题的评论中,我看到了一个建议使用的声明
result is not None
VS
result != None
我想知道区别是什么,以及为什么可能推荐另一个?
推荐指数
解决办法
查看次数
从MySQL切换到Cassandra - 优点/缺点?
对于一些背景知识 - 这个问题涉及在单个小型EC2实例上运行的项目,并且即将迁移到中型项目.主要组件是Django,MySQL和大量用python和java编写的自定义分析工具,这些工具都是繁重的工作.同一台机器也在运行Apache.
数据模型如下所示 - 大量实时数据来自各种网络传感器,理想情况下,我想建立一个长轮询方法,而不是每15分钟进行一次当前轮询(限制为计算统计数据并写入数据库本身).一旦数据进入,我将原始版本存储在MySQL中,让分析工具在这些数据上松散,并将统计信息存储在另外几个表中.所有这些都是使用Django呈现的.
我需要的关系功能 -
- 为了通过[SliceRange在Cassandra的API似乎satisy这种]
- 通过...分组
- 多个表之间的多种关系[Cassandra SuperColumns似乎在一对多之间表现良好]
- 狮身人面像给我一个很好的全文引擎,所以这也是必要的.[在Cassandra上,Lucandra项目似乎满足了这种需求]
我的主要问题是数据读取非常慢(并且写入也不是很热).我现在不想在它上面投入大量资金和硬件,而且我更喜欢随着时间的推移可以轻松扩展的东西.在这种意义上(或便宜),纵向扩展MySQL并非易事.
所以基本上,在阅读了很多关于NOSQL并尝试了像MongoDB,Cassandra和Voldemort这样的东西之后,我的问题是,
在中等EC2实例上,通过转换到像Cassandra这样的东西,我可以获得读/写的任何好处吗?这篇文章(pdf)肯定似乎暗示了这一点.目前,我会说每分钟几百次写入是常态.对于读取 - 由于数据每5分钟左右更改一次,因此缓存失效必须非常快.在某些时候,它应该能够处理大量并发用户.即使创建了索引,MySQL在大型表上进行某些连接时,应用程序性能也会被杀死 - 大约32k行的内容需要超过一分钟才能呈现.(这可能是EC2虚拟化I/O的工件).表的大小约为4-5百万行,并且大约有5个这样的表.
考虑到CAP定理和最终的一致性,每个人都在谈论在多个节点上使用Cassandra.但是,对于刚刚开始增长的项目,部署单节点cassandra服务器是否有意义?有什么警告吗?例如,它可以取代MySQL作为Django的后端吗?[这是推荐的吗?]
如果我确实转移,我猜我将不得不重写部分应用程序以执行更多"administrivia",因为我必须执行多次查找以获取行.
将MySQL用作关键值存储而不是关系引擎是否有意义,并继续使用它?这样我可以利用大量可用的稳定API,以及稳定的引擎(并根据需要使用关系).(Brett Taylor在Friendfeed上的帖子 - http://bret.appspot.com/entry/how-friendfeed-uses-mysql)
任何转变的人的见解将不胜感激!
谢谢.
推荐指数
解决办法
查看次数
Python中的Unicode标识符?
我想构建一个计算的Python函数,
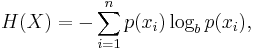
并且想要命名我的求和函数Σ.以类似的方式,想用Π作产品,依此类推.我想知道是否有办法以这种方式命名python函数?
def ? (..):
..
..
也就是说,Python是否支持unicode标识符,如果是这样,有人可以为它提供一个示例吗?
谢谢!
最初的动机是我今天看到的Clojure代码,看起来像,
(defn entropy [X]
(* -1 (? [i X] (* (p i) (log (p i))))))
其中Σ是定义为的宏,
(defmacro ?
... )
而且我觉得这很酷.
顺便说一句,为了解决一些关于可读性的评论 - 例如,有很多统计数据/ ML代码,能够用符号组合操作将非常有帮助.(特别是对于非常复杂的积分等)
?(z) = ?(N(x|0,1,1), -?, z)
VS
Phi(z) = integral(N(x|0,1,1), -inf, z)
甚至只是lambda()的lambda字符!
推荐指数
解决办法
查看次数
使用_specific formatting_以级别顺序打印BFS(二叉树)
首先,这个问题是不是一个DUP 这一个,而是以它.
以该问题中的树为例,
1
/ \
2 3
/ / \
4 5 6
你会如何修改你的程序来打印它,
1
2 3
4 5 6
而不是一般
1
2
3
4
5
6
我基本上是以最有效的方式寻找直觉 - 我有一个方法,包括将结果附加到列表,然后循环遍历它.一种更有效的方法可能是在弹出每个级别时存储最后一个元素,然后打印出一个新行.
想法?
推荐指数
解决办法
查看次数
夹紧线没有'-webkit-line-clamp'
在过去的好时光中,webkit中存在一个使用纯css夹紧线的技巧:
display: -webkit-box;
-webkit-line-clamp: 3;
-webkit-box-orient: vertical;
虽然这种语法很乐意与语法共存,但display: -webkit-flex在所有基于webkit的现代浏览器中,它都被认为是过时的.
我的问题是:
如何在纯CSS中实现行绑定并且没有过时的'-webkit-line-clamp'技巧?
推荐指数
解决办法
查看次数
Java的TreeSet等效于Python?
我最近遇到了一些Java代码,它们简单地将一些字符串放入Java TreeSet中,为它实现了一个基于距离的比较器,然后以快乐的方式进入日落以计算给定的分数来解决给定的问题.
我的问题,
是否有可用于Python的等效数据结构?
- Java树集看起来基本上是一个有序字典,可以使用某种比较器来实现这种排序.
我看到有一个针对 OrderedDict的Py3K的PEP,但我使用的是2.6.x. 那里有一堆有序的dict实现 - 特别是可以推荐的任何人?
PS,我想补充-我可以大概导入DictMixin或UserDict中,并实现自己的排序/有序字典,并使其发生通过比较器功能-但是,这似乎是矫枉过正.
谢谢.
更新.谢谢你的回答.为了详细说明,我可以说我有一个定义的比较函数,(给定一个特定的值ln),
def mycmp(x1, y1, ln):
a = abs(x1-ln)
b = abs(y1-ln)
if a<b:
return -1
elif a>b:
return 1
else:
return 0
我有点不确定如何将这个集成到这里给出的有序字典链接中给出的顺序中.
就像是,
OrderedDict(sorted(d.items(), cmp=mycmp(len)))
我们欢迎您的想法.
推荐指数
解决办法
查看次数
遍历Trie以检查拼写建议的好算法是什么?
假设构建了一个字典单词的一般Trie,那么在遍历期间检查4种拼写错误 - 替换,删除,转置和插入的最佳方法是什么?
一种方法是找出给定单词的n个编辑距离内的所有单词,然后在Trie中检查它们.这不是一个糟糕的选择,但这里更好的直觉似乎是使用动态编程(或递归等效)方法来确定在遍历期间修改单词后的最佳子尝试.
任何想法都会受到欢迎!
PS,会欣赏实际输入,而不仅仅是答案中的链接.
推荐指数
解决办法
查看次数
与Java和Python相比,为什么Clojure Hello World程序如此之慢?
更新
正如许多人所建议的那样,看起来这是因为clojure代码首先被编译然后执行.AOT编译应该有助于抵消这一点.鉴于我发现实际Clojure的AOT编译过程有点棘手,解决(类路径问题,目录问题等),我写了一个小循序渐进的过程在这里,如果有人有兴趣.
大家好,
我正在阅读"Programming Clojure",我正在比较一些用于简单代码的语言.我注意到clojure实现在每种情况下都是最慢的.例如,
Python - hello.py
def hello_world(name):
print "Hello, %s" % name
hello_world("world")
结果,
$ time python hello.py
Hello, world
real 0m0.027s
user 0m0.013s
sys 0m0.014s
Java - hello.java
import java.io.*;
public class hello {
public static void hello_world(String name) {
System.out.println("Hello, " + name);
}
public static void main(String[] args) {
hello_world("world");
}
}
结果,
$ time java hello
Hello, world
real 0m0.324s
user 0m0.296s
sys 0m0.065s
最后,
Clojure - hellofun.clj
(defn hello-world [username] …推荐指数
解决办法
查看次数
训练tf.estimator时记录准确度指标
在培训预先预测的估算器时,打印精度指标以及丢失的最简单方法是什么?
大多数教程和文档似乎都解决了当您创建自定义估算器时的问题 - 如果打算使用其中一个可用的估算器,这似乎有点过头了.
tf.contrib.learn有一些(现已弃用)Monitor钩子.TF现在建议使用钩子API,但看起来它实际上没有任何可以利用标签和预测来生成准确度数字的东西.
推荐指数
解决办法
查看次数
在Clojure中传递一个文件?
在Clojure中拖尾文件的最佳方法是什么?我没有遇到任何有助于这样做的实用程序,但是如何构建一个实用程序的想法将不胜感激!
谢谢.
推荐指数
解决办法
查看次数
标签 统计
python ×5
algorithm ×2
clojure ×2
binary-tree ×1
cassandra ×1
comparison ×1
css ×1
django ×1
file-io ×1
flexbox ×1
identifier ×1
java ×1
jvm ×1
migration ×1
mysql ×1
nosql ×1
operators ×1
performance ×1
tensorboard ×1
tensorflow ×1
treeset ×1
trie ×1
unicode ×1
webkit ×1