我正在寻找涉及将C++模板函数作为参数传递的规则.
这得到了C++的支持,如下例所示:
#include <iostream>
void add1(int &v)
{
v+=1;
}
void add2(int &v)
{
v+=2;
}
template <void (*T)(int &)>
void doOperation()
{
int temp=0;
T(temp);
std::cout << "Result is " << temp << std::endl;
}
int main()
{
doOperation<add1>();
doOperation<add2>();
}
然而,了解这种技术很困难.谷歌搜索"作为模板参数的功能"不会导致太多.令人惊讶的是,经典的C++模板完整指南也没有讨论它(至少不是我的搜索).
我的问题是这是否是有效的C++(或者只是一些广泛支持的扩展).
另外,在这种模板调用过程中,有没有办法允许具有相同签名的仿函数与显式函数互换使用?
以下就不能在上面的程序中工作,至少在视觉C++,因为语法显然是错误的.能够为仿函数切换函数是很好的,反之亦然,类似于如果要定义自定义比较操作,可以将函数指针或函子传递给std :: sort算法.
struct add3 {
void operator() (int &v) {v+=3;}
};
...
doOperation<add3>();
指向一个或两个Web链接的指针,或C++模板书中的页面将不胜感激!
在许多应用程序中,我们为文件下载,压缩任务,搜索等提供了一些进度条.我们经常使用进度条让用户知道正在发生的事情.如果我们知道一些细节,例如已完成了多少工作以及剩下多少工作,我们甚至可以通过推断从达到当前进度水平所需的时间来估算时间.
压缩ETA截图http://jameslao.com/wp-content/uploads/2008/01/winrar-progress-bar.png
但我们也看到这个时间留下"ETA"显示的程序只是滑稽的坏.它声称文件副本将在20秒内完成,然后一秒后它会说需要4天,然后再次闪烁20分钟.它不仅无益,而且令人困惑!ETA变化如此之大的原因是进度本身可能会有所不同,程序员的数学运算可能过于敏感.
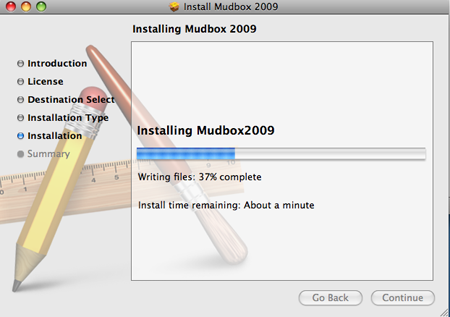
苹果公司通过避免任何准确的预测并仅仅给出模糊估计来回避这一点! Apple的模糊逃避http://download.autodesk.com/esd/mudbox/help2009/images/MED/DaliSP1/English/Install_licensing/install_progress_MAC.png
这也很烦人,我有时间快速休息,还是我的任务将在2秒内完成?如果预测太模糊,那么完全做出任何预测毫无意义.
简单但错误的方法
作为第一次通过ETA计算,可能我们都只是做一个函数,如果p是已经完成的小数百分比,t是到目前为止所用的时间,我们输出t*(1-p)/ p作为估计完成需要多长时间.这个简单的比例可以"正常",但它也很糟糕,特别是在计算结束时.如果你的缓慢下载速度让副本慢慢地在一夜之间发生,最后在早上,一些东西开始运行,副本开始全速前进,速度提高了100倍,你完成90%的ETA可能会说"1小时",10秒之后你会达到95%而且ETA会说"30分钟",这显然是一个令人难以置信的糟糕猜测.在这种情况下,"10秒"是一个非常好的估计.
当发生这种情况时,您可能会考虑更改计算以使用最近的速度而不是平均速度来估算ETA.您可以获取过去10秒内的平均下载速率或完成率,并使用该速率来预测完成时间.这在之前的一夜之间下载过程中表现相当不错,因为它将在最后给出非常好的最终完成估算.但是这仍然存在很大问题..当你的速率在很短的时间内快速变化时,它会导致你的ETA大幅反弹,你会得到"在20秒内完成,在2小时内完成,在2秒内完成,在30秒内完成"分钟"快速显示编程耻辱.
实际问题:
在给定计算的时间历史的情况下,计算任务完成的估计时间的最佳方法是什么?我不是在寻找GUI工具包或Qt库的链接.我问的算法是生成最理智和准确的完成时间估计.
你有数学公式的成功吗?某种平均值,可能是使用超过10秒的速率平均值,速率超过1分钟,速率超过1小时?某种人工过滤,例如"如果我的新估计值与之前的估计值相差太大,请将其调低,不要让它反弹太多"?某种奇特的历史分析,您可以将进度与时间进度相结合,找到速率的标准偏差,以便在完成时给出统计误差指标?
你尝试了什么,什么效果最好?
在C中用单位测试和设置单个位的经典问题可能是最常见的中级编程技能之一.您可以使用简单的位掩码进行设置和测试
unsigned int mask = 1<<11;
if (value & mask) {....} // Test for the bit
value |= mask; // set the bit
value &= ~mask; // clear the bit
一篇有趣的博客文章认为,这容易出错,难以维护,而且做法不佳.C语言本身提供了类型安全和可移植的位级访问:
typedef unsigned int boolean_t;
#define FALSE 0
#define TRUE !FALSE
typedef union {
struct {
boolean_t user:1;
boolean_t zero:1;
boolean_t force:1;
int :28; /* unused */
boolean_t compat:1; /* bit 31 */
};
int raw;
} flags_t;
int
create_object(flags_t flags)
{
boolean_t is_compat = flags.compat;
if (is_compat) …malloc()失败的原因是什么,尤其是64位?
我的具体问题是试图在64位系统上使用巨大的10GB RAM.该机器具有12GB的RAM和32 GB的交换空间.是的,malloc极端,但为什么会出现问题呢?这是在Windows XP64中同时包含Intel和MSFT编译器.malloc有时成功,有时不成功,约50%.8GB malloc总是工作,20GB malloc总是失败.如果malloc失败,重复请求将不起作用,除非我退出该过程并再次开始一个新进程(这将成功获得50%的注射).没有其他大型应用程序正在运行 它会在重新启动后立即发生.
我可以想象如果你已经用完了32位(或31位)可用的地址空间,那么malloc会失败32位,这样就没有足够大的地址范围可以分配给你的请求了.
我还可以想象,如果你已经用完物理内存和你的硬盘交换空间,malloc会失败.对我来说情况并非如此.
但为什么malloc会失败呢?我想不出其他原因.
我对一般malloc问题比我的具体例子更感兴趣,无论如何我都可能用内存映射文件替换它.失败的malloc()只是一个难题而不是其他任何东西......想要了解你的工具而不是对基础知识感到惊讶.
我觉得我是一个全面的程序员,我对C#和java(两个大型项目都很满意)感到很自在,但是当我有选择时,我倾向于在大多数应用程序中使用C++.(有时候R,Python或Perl也适用..)
但是我很震惊地看到C#在这里的受欢迎程度.有18500个C#主题,超过C,C++和java的组合.我从来没有觉得 C#对我曾经合作过的公司产生过这样的影响,但C#的普及程度是不可否认的.
我的问题: 为什么C#在Stack Overflow上如此受欢迎?与C++和java相比, 我的问题并不是理解C#目前的接受度/增长率.
流行的可能解释:
第一种解释可能是原因,但我还没有感受到现实世界的普及!
你在这里讨论C#主题的原因是什么?
多监视器编程的乐趣是无数的,我认为关于这个主题的Coding Horror上有大约5篇博客文章!我经常在我的主机上使用Windows编写代码,并将我的Mac笔记本电脑设置在一边.我使用Mac来编译Mac版本,但也作为我的"参考Web浏览器".没有KVM或任何东西.
然而,在会议上随意的谈话引发了我的疑问,我可以使用两台独立的机器来共享窗户吗?直接将一些窗口从一台机器移动到另一台机器,因此我可以将一台PC的显示器用作另一台机器的"溢出".
一些谷歌搜索突然显示在某些情况下这是可能的肯定:
我的问题是,是否有程序员尝试过这样的设置.我们有独特的需求,特别是有多个文本窗口和编辑器,这种工具可能是一个巨大的胜利或巨大的麻烦.
这个解决方案感觉就像简单的KVM切换和多个监视器的组合......这听起来像编程梦想!因此,在投资相当复杂的设置之前,建议或特别是编程环境中的实际经验报告将非常有用.
跟进:听起来我要求的东西不存在!它是软件KVM 和 VNC 的组合.但是VNC需要打破应用程序窗口并允许单独操作(就像那个maxivista商业工具,只有Vista).
感谢所有的反馈.看起来有需要一个很酷的应用程序,如果有人有驱动器成为这个新的nich!
我有一些数据,最多可达一百万到十亿条记录,每条记录由一个位域表示,每个键大约64位.这些位是独立的,您可以将它们想象成基本上随机的位.
如果我有一个测试密钥,并且我想用相同的密钥查找数据中的所有值,则哈希表将很容易地在O(1)中吐出这些值.
什么算法/数据结构可以有效地找到与查询键最相似的所有记录?这里类似意味着大多数位是相同的,但允许最小数量是错误的.传统上通过汉明距离来测量 .,它只计算不匹配位的数量.
有两种方法可以进行此查询,一种可能是通过指定不匹配率,例如"给我一个列表,其中包含少于6位且与我的查询不同的所有现有键",或者只是通过最佳匹配,例如"给我一个10,000条密钥的列表,其中我的查询中的不同位数最少."
您可能会想要运行k-最近邻居算法,但在这里我们讨论的是独立位,因此像四叉树这样的结构似乎不太有用.
这个问题可以通过简单的强力测试哈希表来解决少量不同的比特.例如,如果我们想要查找与查询相差一位的所有键,我们可以枚举所有64个可能的键并对它们进行全部测试.但是这很快爆发,如果我们想要允许两位差异,那么我们必须探测64*63 = 4032次.对于更高的位数,它会呈指数级变差.
那么是否有其他数据结构或策略可以使这种查询更有效?可以根据需要对数据库/结构进行预处理,这是应该优化的查询速度.
许多CPU具有用于返回单个组件的操作码的高 32位的整数乘法的序位.通常将两个32位整数相乘会产生64位结果,但如果将其存储为32位整数,则会将其截断为低32位.
例如,在PowerPC上,mulhw操作码在一个时钟内返回32位32位乘法的64位结果的高32位.这正是我正在寻找的,但更便携.在NVidia CUDA中有一个类似的操作码,umulhi().
在C/C++中,是否有一种有效的方法来返回32x32乘法的高阶位?目前我通过转换为64位来计算它,例如:
unsigned int umulhi32(unsigned int x, unsigned int y)
{
unsigned long long xx=x;
xx*=y;
return (unsigned int)(xx>>32);
}
但这比常规的32乘32乘以慢11倍,因为即使是乘法,我也使用了过度的64位数学运算.
有更快的方法来计算高阶位吗?
对于BigInteger库来说,这显然不是最好的解决方案(这是一种过度杀伤并且会产生巨大的开销).
SSE似乎有PMULHUW,16x16 - > 16位版本,但不是32x32 - > 32版本,就像我在寻找.
在32位整数数学中,add和multiply的基本数学运算隐式计算mod 2 ^ 32,这意味着你的结果将是add或multiply的最低位.
如果要使用不同的模数计算结果,您当然可以使用不同语言的任意数量的BigInt类.对于值a,b,c <2 ^ 32,您可以计算64位长整数的中间值,并使用内置的%运算符减少到右侧的答案
但是我被告知,当C的形式为(2 ^ N)-1或(2 ^ N)+1时,有一些特殊的技巧可以有效地计算a*b mod C,它们不使用64位数学或一个BigInt库,非常高效,比任意模数评估更有效,并且还可以正确计算在包含中间乘法时通常会溢出32位int的情况.
不幸的是,尽管听说这种特殊情况有快速的评估方法,但实际上我还没有找到该方法的描述."那不是在Knuth吗?" "这不就是维基百科上的某个地方吗?" 是我听到的咕噜声.
它显然是随机数生成器中的常用技术,其执行a*b mod 2147483647的乘法,因为2147483647是等于2 ^ 31 -1的素数.
所以我会问专家.什么是这个聪明的特殊情况乘法与mod方法,我找不到任何讨论?
因此,您的商业应用程序处于开发的中间阶段......足以使其可用,但仍需要细化,扩展,修复错误.它远非可交付,但它足够稳定和完整,您的开发人员和内部测试人员/用户认为是时候从真实用户那里获得更多反馈.
因此,您可以进行更广泛但仍然封闭的测试,可能是从想要贡献并提供反馈的现有用户/客户中选择的.
一个以前的SO问题表明,使用beta测试的最好办法是,以确保有良好的双向沟通.我们想要实现这种沟通!
那么问题是要找到最好的方法来组织和允许开发人员和beta测试人员之间以及beta测试人员之间的沟通?
在过去,我们总是在这里设置一个简单的电子邮件邮件列表,将秘密测试人员添加到列表中,并通过电子邮件发送集中地址发布,这些地址在列表中的每个人之间共享.这是原始的和老派的,但我们已经这样做了十五年,它可以正常工作,特别是对于我们的大约10名测试人员的外部小组.
但必须有其他方法,也许最好去探索它们.您为自己的项目设置了哪些beta测试基础架构?目标和要求是模糊的,但有些点可能有用
设计这种甚至可以组合的beta支持基础设施有一些明显的选择.
查看SourceForge也很有用,它适用于不需要保密,邀请或类的开源应用程序,但是每个项目都有一个论坛和bugtracker.即使考虑即将推出的Google Wave等平台/范例也可能会很有趣.
我的问题:你用什么系统来组织内部/外部的beta测试人员,哪一个系统在增强开发过程方面给出了最好的回报,而不是为了管理一些过于复杂的系统而烦恼或烦恼?
我将此作为社区维基发布,因为很明显没有一个单一的最佳答案.
{kind=link}
{kind=link}
{kind=link}