小编que*_*ion的帖子
如何制作带有大矩阵的热图?
我有一个1000*1000矩阵(只包含整数0和1),但是当我尝试制作热图时,会发生错误,因为它太大了.
如何创建具有如此大矩阵的热图?
10
推荐指数
推荐指数
5
解决办法
解决办法
2万
查看次数
查看次数
R:如何显示聚类矩阵热图(类似的颜色模式被分组)
我在整个网站和包中搜索了很多关于热图的问题,但我仍然有问题.
我有集群数据(kmeans/EM/DBscan ..),我想通过对同一个集群进行分组来创建热图.我希望将相似的颜色模式分组到热图中,因此通常看起来像块对角线.
我尝试按簇号排序数据并显示它,
k = kmeans(data, 3)
d = data.frame(data)
d = data.frame(d, k$cluster)
d = d[order(d$k.cluster),]
heatmap(as.matrix(d))

但是,我希望它按簇号排序,看起来像这样:

我可以在R中这样做吗?
我搜索了很多包,尝试了很多方法,但我还是有问题.
非常感谢.
8
推荐指数
推荐指数
1
解决办法
解决办法
1万
查看次数
查看次数
5
推荐指数
推荐指数
1
解决办法
解决办法
1282
查看次数
查看次数
在R中,如何在聚类数据后绘制相似性矩阵(如块图)?
我想生成一个图表,显示聚类数据和相似性矩阵之间的相关性.我怎么能在R中这样做?R中是否有任何函数可以像此链接中的图片一样创建图形? http://bp0.blogger.com/_VCI4AaOLs-A/SG5H_jm-f8I/AAAAAAAAAJQ/TeLzUEWbb08/s400/Similarity.gif (只是用Google搜索,并得到了展示,我想制作一个图表链接)
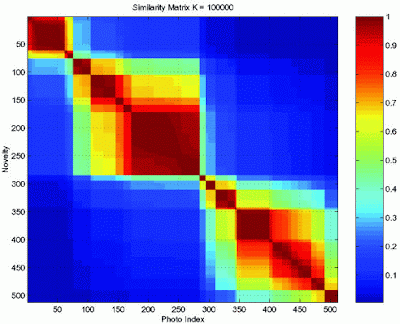{kind=link}
提前致谢.
3
推荐指数
推荐指数
1
解决办法
解决办法
1万
查看次数
查看次数
R:每次运行时,群集结果都不同
library(amap)
set.seed(5)
Kmeans(mydata, 5, iter.max=500, nstart=1, method="euclidean")
在'amap'包中运行几次,但即使参数和种子值始终相同,每次运行Kmeans或其他集群方法时,聚类结果也不同.
我在不同的包中尝试了另一个kmeans功能,但仍然相同...
事实上,我想一起使用Weka和R,所以我也试过SimpleKMeans了RWeka包,这总是给出了相同的值.但是,问题是我不知道如何将集群数据与来自RWeka的SimpleKmeans的集群号一起存储,所以我被卡住了......
无论如何,如何保持聚类结果始终相同?或者如何将聚类结果存储SimpleKmeans到R中?
2
推荐指数
推荐指数
2
解决办法
解决办法
4798
查看次数
查看次数
如何在Prolog中将变量设为空?
我想在Prolog中清空一个用过的变量.
例如,我想这样做,
i = null;
在Prolog.
我该怎么做呢?
谢谢.
1
推荐指数
推荐指数
1
解决办法
解决办法
7050
查看次数
查看次数