小编Jam*_*rus的帖子
使用plot_model()更改线型和线颜色
plot_model()我正在尝试使用中的函数创建预测值图sjPlot。我希望我的预测线具有不同的线型和不同的颜色。
该函数包含一个colors参数,设置colors为bw将更改linetype,但设置colors为灰度。这个问题类似,但没有收到有用的答案:Coloredribsand differentlinetypesinsjPlotplot_model()
例子:
不同linetypes,但不是colors
data(iris)
toy_model <- lm( Sepal.Length ~ Sepal.Width + Species, data=iris)
my_plot <- plot_model(toy_model, type=("pred"),
terms=c("Sepal.Width","Species"),
colors="bw")
不同colors,但不是linetypes
data(iris)
toy_model <- lm( Sepal.Length ~ Sepal.Width + Species, data=iris)
my_plot <- plot_model(toy_model, type=("pred"),
terms=c("Sepal.Width","Species"))
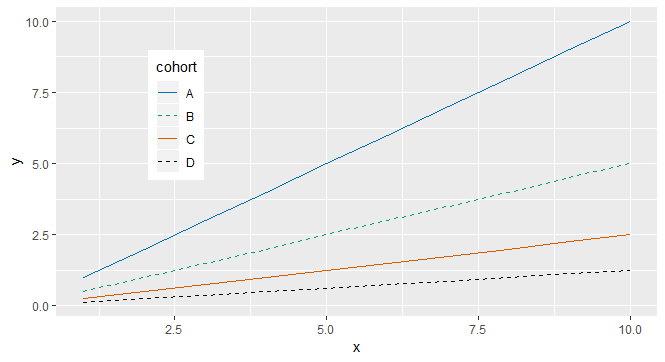
怎样才能既不同colors又不同linetypes呢?换句话说,我想要这样的东西
推荐指数
解决办法
查看次数
如何使用 html_nodes 在 R 中选择具有“attribute = x”的节点?
我有一组 html 页面。我想提取属性“border”= 1的所有表节点。这是一个例子:
<table border="1" cellspacing="0" cellpadding="5">
<tbody><tr><td>
<table border="0" cellpadding="2" cellspacing="0">
<tbody><tr>
<td bgcolor="#ff9999"><strong><font size="+1">CASEID</font></strong></td>
</tr></tbody>
</table>
<tr><td>[tbody]
</table>
在示例中,我想选择 border=1 的表节点,而不是 border = 0 的表。我正在使用html_nodes()fromrvest但不知道如何添加属性:
html_nodes(x, "table")
推荐指数
解决办法
查看次数
在我创建的 R 数据包中找不到数据集
我正在构建一个包含多个数据集的 R 包。我将数据集保存为“数据”文件夹中的 .RData 对象,并且每个数据集都有使用 .RData 生成的文档roxygen2。当我安装包时,加载它并尝试调用数据集,
devtools::install_github("jamesmartherus/nhldata")
library(nhldata)
data(teams)
我收到此错误:
In data("teams") : data set ‘teams’ not found
这是我的说明文件的内容:
Package: nhldata
Title: Easy Access to Basic NHL Data
Version: 0.1.0
Authors@R: person("James", "Martherus", email = "james@martherus.com",
role = c("aut", "cre"))
Description: Includes several datasets of NHL statistics including skater, goalie, and team statistics by season.
Depends: R (>= 3.5.0)
License: MIT
LazyData: true
RoxygenNote: 6.1.1
Encoding: UTF-8
这是我的文档文件的最小版本:
\docType{data}
\name{teams}
\alias{teams}
\title{NHL Team Statistics 2007-2019}
\format{A data …推荐指数
解决办法
查看次数
对于每一行,确定 R 中具有相同值的列的比例
我有一个与此类似的调查回复数据集:
toy <- data.frame(v1 = c(1,2,3), v2 = c(1,6,3), v3 = c(1,2,4), v4 = c(1,7,3))
toy
v1 v2 v3 v4
1 1 1 1 1
2 2 6 2 7
3 3 3 4 3
我想通过查找每行最常见的值并计算具有该值的列的比例来检测“直线”。
两个例子:
- 如果一行中每一列的值为 5,则新变量应返回 1
- 如果一行中 60% 的列的值为 3,40% 的列的值为 4,则该变量应返回 0.6
期望的输出:
v1 v2 v3 v4 straightline_pct
1 1 1 1 1 1
2 2 6 2 7 .50
3 3 3 4 3 .75
推荐指数
解决办法
查看次数
R中是否有一个函数可以删除特定给定内容的数千行?
我有TLSWL大约20,000行的数据框(称为)。我Time在df中有一列,我需要删除所有在特定分钟内结束的行。我只需要增加30分钟的时间即可匹配其他数据进行比较。
这是我目前正在使用的:
TLSWL<- TLSWL[TLSWL$Time != "0:06"&TLSWL$Time !="0:12"&TLSWL$Time
!="0:18"&TLSWL$Time !="0:24"&TLSWL$Time != "0:36"&TLSWL$Time
!="0:42"&TLSWL$Time !="0:48"&TLSWL$Time != "0:54"&TLSWL$Time
!= "1:06"&TLSWL$Time != "1:12"&TLSWL$Time != "1:18"&TLSWL$Time
!= "1:24"&TLSWL$Time != "1:36"&TLSWL$Time != "1:42"&TLSWL$Time
!= "1:48"&TLSWL$Time != "1:54"&TLSWL$Time != "2:06"&TLSWL$Time
!= "2:12"&TLSWL$Time != "2:18"&TLSWL$Time != "2:24"&TLSWL$Time
!= "2:36"&TLSWL$Time != "2:42"&TLSWL$Time != "2:48"&TLSWL$Time
!= "2:54"&TLSWL$Time != "3:06"&TLSWL$Time != "3:12"&TLSWL$Time
and so on all the way to the times in 24:xx
它适用于较小的数据帧,而不是在军事时间,但是您可以看到以这种方式进行操作所需的代码行最终会变得很长。
可以更有效地做到这一点吗?
推荐指数
解决办法
查看次数
帧之间的gganimate变化轴
我正在尝试使用 gganimate 绘制 NHL 前三名得分手随着时间的推移。目前,我有一个柱状图,其中 x 轴显示球员姓名,y 轴显示每个球员的进球数。这是我所拥有的静态版本:
library(ggplot2)
data <- data.frame(name=c("John","Paul","George","Ringo","Pete","John","Paul","George","Ringo","Pete"),
year = c("1997", "1997", "1997", "1997", "1997", "1998", "1998","1998","1998", "1998"),
goals = c(50L, 35L, 29L, 5L, 3L, 3L, 5L, 29L, 36L, 51L))
data <- data %>%
arrange(goals) %>%
group_by(year) %>%
top_n(3, goals)
ggplot(data,
aes(x = reorder(name, goals), y=goals)) +
geom_col() +
facet_wrap(data$year) +
coord_flip()

我想要的是只显示前 3 名球员。换句话说,一年进入前三名但第二年退出前三名的球员不应该出现在第二帧中。最终产品应如下所示:
推荐指数
解决办法
查看次数