使用典型的Apache访问日志,您可以运行:
tail -f access_log | grep "127.0.0.1"
这只会显示指定IP地址的日志(因为它们已创建).
但是,为什么grep在第二次管道时会失败,以进一步限制结果?
例如,".css"的简单排除:
tail -f access_log | grep "127.0.0.1" | grep -v ".css"
不会显示任何输出.
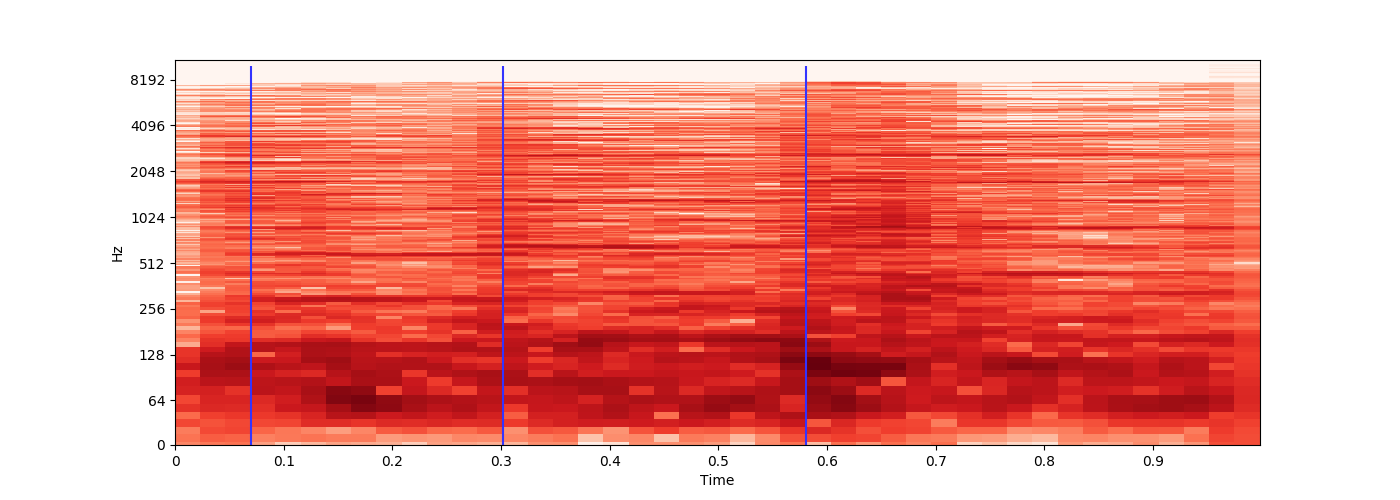
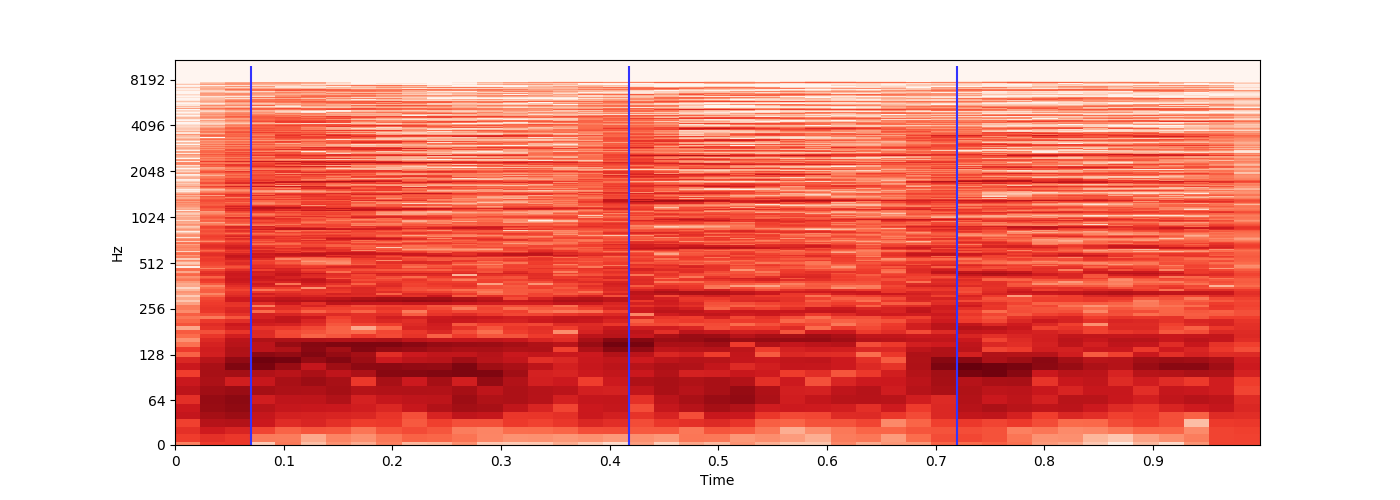
我加载了 3 小时的 MP3 文件,每大约 15 分钟就会播放一次独特的 1 秒音效,这标志着新章节的开始。
是否可以识别每次播放该音效的时间,以便我可以记录时间偏移?
每次的声音效果都相似,但由于它是以有损文件格式编码的,因此会有少量变化。
时间偏移将存储在ID3 章节帧元数据中。
示例 Source,其中声音效果播放两次。
ffmpeg -ss 0.9 -i source.mp3 -t 0.95 sample1.mp3 -acodec copy -y
ffmpeg -ss 4.5 -i source.mp3 -t 0.95 sample2.mp3 -acodec copy -y
我对音频处理非常陌生,但我最初的想法是提取 1 秒音效的样本,然后librosa在 python 中使用来提取两个文件的浮点时间序列,对浮点数进行舍入,并尝试获取一场比赛。
import numpy
import librosa
print("Load files")
source_series, source_rate = librosa.load('source.mp3') # 3 hour file
sample_series, sample_rate = librosa.load('sample.mp3') # 1 second file
print("Round …假设一个静态HTML表,例如:
<table>
<thead>
<tr>
<th scope="col" aria-sort="none"><a href="...">Name <span title="Sort">▲</span></a></th>
<th scope="col" aria-sort="ascending"><a href="...">Score <span title="Ascending">▲</span></a></th>
</tr>
</thead>
<tbody>
<tr>
<td>C</td>
<td>1</td>
</tr>
<tr>
<td>A</td>
<td>5</td>
</tr>
<tr>
<td>B</td>
<td>9</td>
</tr>
</tbody>
</table>
aria-sort是否适当使用(当UA支持它时)?
http://www.w3.org/TR/wai-aria/states_and_properties#aria-sort
我相信这可能很有用,但W3C验证器目前需要一个role="columnheader"on <th scope="col">,这有点多余,因为它已经暗示th[scope="col"]:
http://www.w3.org/TR/wai-aria/roles#columnheader
一旦你开始指定它,你还需要设置一个角色,直到<table role="grid">...如果你没有使用适当的标签,这很好.
一位开发人员刚刚在我维护的网站上引入了一个SQL注入漏洞,我想展示它是如何被轻易利用的; 但有几个问题.
采用SQL,大致是:
SELECT
c.id,
c.name,
c.start
FROM
course AS c
WHERE
MONTH(c.start) = $_GET['month']
ORDER BY
c.start
如果我设置$_GET['month']为:
13 UNION SELECT 1, username, 3 FROM admin
这将运行查询:
SELECT
c.id,
c.name,
c.start
FROM
course AS c
WHERE
MONTH(c.start) = 13 UNION SELECT 1, username, 3 FROM admin
ORDER BY
c.start
如果ORDER BY不包含c.表别名,那么哪个会起作用.相反,它会导致错误:
Table 'c' from one of the SELECTs cannot be used in field list
添加cALIAS admin也没有任何区别:
13 UNION SELECT 1, c.username, …如果我要实现一个新的服务器到服务器API,有哪些身份验证标准可以让其他人轻松使用?
理想情况下,我需要记录的关于身份验证如何工作的越少越好(因此标准),并且使用该服务的开发人员更有可能使用标准库.
但有些限制:
我怀疑SSL类型设置有点太复杂,因为似乎大多数开发人员并不真正知道如何正确实现它.
使用oAuth 1.0,它看起来很简单:
http://provider.example.net/profile
Authorization: OAuth realm="http://provider.example.net/",
oauth_consumer_key="dpf43f3p2l4k3l03",
oauth_signature_method="HMAC-SHA1",
oauth_signature="IxyYZfG2BaKh8JyEGuHCOin%2F4bA%3D",
oauth_timestamp="1191242096",
oauth_token="",
oauth_nonce="kllo9940pd9333jh",
oauth_version="1.0"
但开发人员现在似乎正专注于oAuth 2,其中一个可能的解决方案是:
首先要求你调用"/ oauth/token"来获取一个令牌,但似乎没有太多关于这实际如何工作的规范形式(参见回复):
http://www.ietf.org/mail-archive/web/oauth/current/msg07957.html
然而,有一些提及在oAuth 2中使用MAC,这可能是有用的...例如,授权一次获取MAC(没有登录详细信息),保持半无限期,并重新使用所有后续要求:
http://blog.facilelogin.com/2013/01/oauth-20-bearer-token-profile-vs-mac.html
还有一个关于HMAC的有趣讨论,这意味着它没有关于如何工作的标准:
http://flascelles.wordpress.com/2010/01/04/standardize-hmac-oauth-restful-authentication-schemes/
其他说明:
oAuth 1.0的实施,文档和讨论:
http://www.ietf.org/mail-archive/web/oauth/current/msg06218.html https://developers.google.com/accounts/docs/OAuth#GoogleAppsOAuth http://oauth.googlecode.com/ SVN /规格/ EXT/consumer_request/1.0 /草稿/ 2/spec.html
不幸的是,我读到的oAuth 2.0越多,我就越认同Eran Hammer:
现在提供的是授权协议的蓝图,"这是企业的方式",提供"销售咨询服务和集成解决方案的全新前沿". http://en.wikipedia.org/wiki/OAuth
希望我错过了一些明显的东西。
我有一个包含以下几行的文件:
| A | B | C |
|-----------|
Ignore this line
| And | Ignore | This |
| D | E | F | G |
|---------------|
我想找到这些|----|行,删除那些……并用前一行中的|a替换所有字符^。例如
^ A ^ B ^ C ^
Ignore this line
| And | Ignore | This |
^ D ^ E ^ F ^ G ^
到目前为止,我有:
perl -0pe 's/^(\|.*\|)\n\|-+\|/$1/mg'
这需要来自 stdin 的输入(一些其他修改已经发生sed)...并且它正在使用-0和/m支持多行替换。
匹配似乎是正确的,它删除了|----|行,但我看不出如何使用(或)反向引用| …
我正在使用R分析我的Web服务器日志:
data = read.table("/path/to/log", sep=" ")
这些日志包括最终用户IP地址和USER_ID(登录后).
我正在寻找比平时更活跃的用户,或者使用比平常更多的IP地址.
我现在可以通过USER_ID将R分组并计算记录:
counts <- ddply(data, .(data$user_id), nrow);
names(counts) <- c("user_id", "freq");
print(counts[order(counts$freq),c(2,1)], row.names = FALSE);
freq user_id
1 10171
40 7433
94 210
102 2043
但我还想添加一个GROUP_CONCAT(DISTINCT IP)的等价物,如SQL中所示,我也可以看到该用户的不同IP地址列表.
freq user_id ips
1 10171 192.168.0.1
40 7433 192.168.0.5,192.168.0.2
94 210 192.168.0.9
102 2043 192.168.0.1,192.168.0.3,192.168.0.8
在SQL中,它看起来像:
SELECT
user_id,
COUNT(id) AS freq,
GROUP_CONCAT(DISTINCT ip SEPARATOR ",") AS ips
FROM
log_table
GROUP BY
user_id
ORDER BY
freq ASC;
这可能与aggregate()函数有关,但我现在还没想出来.
有关缩放大图像和平移的任何建议吗?理想情况下在页面上内联.
我一直在使用PanoJS(又名GSV2),但现在越来越多人使用iPhone/iPad/Android类型设备,这个库要么太慢,要么旧版本不支持拖动(我现在使用的那个) ).
http://code.google.com/p/panojs/
http://www.dimin.net/software/panojs/
我目前的想法是,对于这些小型处理器,使用平铺图像方法太多了(在最大变焦时尝试拖动144个单独的图像,从3000 x 3000px原始图像,每个图块为250x250px).
所以可能更多的是在设置宽度/高度的情况下加载原始图像...并且编写我自己的JS来缩放/拖动,或者使用另一个库(我现在似乎无法找到)...然后就是使用jQuery(使用jQuery UI进行可拖动支持)的问题,或者只是自己编写原始JS以保持代码量不足.
{kind=link}
{kind=link}