据我所知,学习提升asio并找出一个叫做"strand"的课程.如果只有一个io_service与特定链相关联并通过strand发布句柄.
例子(从这里)
boost::shared_ptr< boost::asio::io_service > io_service(
new boost::asio::io_service
);
boost::shared_ptr< boost::asio::io_service::work > work(
new boost::asio::io_service::work( *io_service )
);
boost::asio::io_service::strand strand( *io_service );
boost::thread_group worker_threads;
for( int x = 0; x < 2; ++x )
{
worker_threads.create_thread( boost::bind( &WorkerThread, io_service ) );
}
boost::this_thread::sleep( boost::posix_time::milliseconds( 1000 ) );
strand.post( boost::bind( &PrintNum, 1 ) );
strand.post( boost::bind( &PrintNum, 2 ) );
strand.post( boost::bind( &PrintNum, 3 ) );
strand.post( boost::bind( &PrintNum, 4 ) );
strand.post( boost::bind( &PrintNum, 5 ) );
然后,strand会为我们序列化处理程序执行.但是这样做的好处是什么呢?为什么我们不想创建一个单独的线程(例如:for循环中的make …
我一直在研究如何减少因CPU和GPU来回传输数据而导致的延迟.当我第一次开始使用CUDA时,我注意到CPU和GPU之间的数据传输确实需要几秒钟,但我并不在乎,因为这对我正在编写的小程序来说并不是一个真正的问题.实际上,对于绝大多数使用GPU,包括视频游戏的程序来说,延迟可能不是一个大问题,因为它们仍然比在CPU上运行的速度快得多.
然而,我是HPC爱好者的一员,当我看到天河一号理论峰值FLOPS与实际LINPACK测量性能之间的巨大差异时,我开始关注我的研究方向.这引起了我对我是否采取正确的职业道路的担忧.
通过使用cudaHostAlloc()函数来使用固定内存(页面锁定)内存是一种减少延迟的方法(非常有效),但还有其他任何我不知道的技术吗?要说清楚,我说的是优化代码,而不是硬件本身(那是NVIDIA和AMD的工作).
作为一个侧面问题,我知道戴尔和惠普销售的是特斯拉服务器.我很好奇GPU如何利用数据库应用程序,您需要从硬盘驱动器(HDD或SSD)中不断读取,这只是CPU可以执行的操作,
有人可以简单地指出计算机体系结构中内存总线和地址总线之间的差异吗?另外当你说内存总线的时候暗示你指的是数据总线?
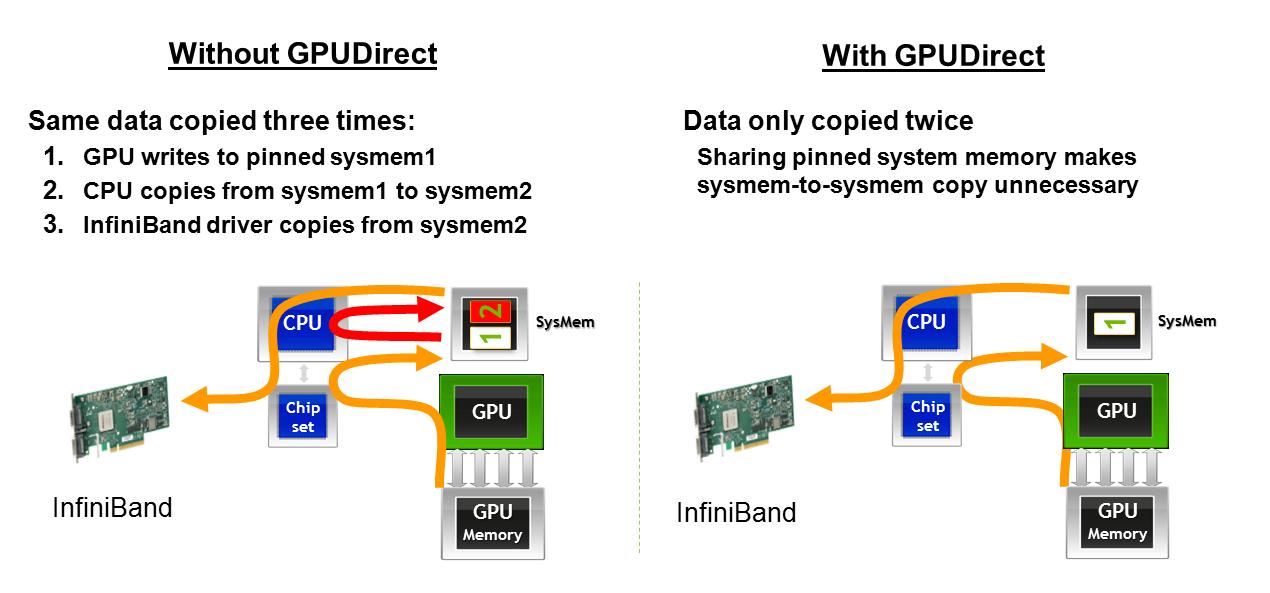
NVIDIA提供GPUDirect以减少内存传输开销.我想知道AMD/ATI是否有类似的概念?特别:
1)AMD GPU在与网卡连接时是否避免第二次内存传输,如此处所述.如果图形在某些时候丢失,这里描述了GPUDirect对从一台机器上的GPU获取数据以通过网络接口传输的影响:使用GPUDirect,GPU内存进入主机内存,然后直接进入网络接口卡.如果没有GPUDirect,GPU内存将转移到一个地址空间中的主机内存,然后CPU必须进行复制以将内存转移到另一个主机内存地址空间,然后它就可以转到网卡.
2)如果在同一PCIe总线上共享两个GPU,AMD GPU是否允许P2P内存传输,如此处所述.如果图形在某些时候丢失,这里描述了GPUDirect对同一PCIe总线上GPU之间传输数据的影响:使用GPUDirect,数据可以直接在同一PCIe总线上的GPU之间移动,而不会触及主机内存.如果没有GPUDirect,数据总是必须返回到主机才能到达另一个GPU,无论GPU位于何处.
编辑:BTW,我不完全确定GPUDirect有多少是蒸发器,有多少是实际有用的.我从来没有真正听说过GPU程序员将它用于真实的东西.对此的想法也是受欢迎的.
我有一个用python编写的模块.这个模块是我在Python中实现的许多不同功能的接口:
EmbeddingInterface.py只是导入该模块并创建一个实例:
import CPPController
cppControllerInstance = CPPController()
我想在c ++中使用cppControllerInstance.这是我到目前为止所做的:
#include <Python.h>
#include <boost\python.hpp>
using namespace boost;
python::object createController()
{
try
{
Py_Initialize();
python::object mainModule = python::import("__main__");
python::object mainNamespace = mainModule.attr("__dict__");
python::dict locals;
python::exec(
"print \"loading python implementetion:\"\n"
"import sys\n"
"sys.path.insert(0, \"C:\\Projects\\Python\\ProjectName\\Panda\")\n"
"import EmbeddingInterface\n"
"controller = EmbeddingInterface.cppControllerInstance\n",
mainNamespace, locals);
python::object controller = locals["controller"];
return controller;
}
catch(...) {}
}
问题:
这个'控制器'有一些必须异步调用的函数.它的工作是连续的,此外它可以抛出异常.这就是为什么std :: async听起来很棒.
但它不起作用:
int main()
{
python::object controller = createController();
python::object loadScene = controller.attr("loadScene");
//loadScene(); // works OK but blocking! …我目前正在学习OpenGL和GLSL编写一个简单的软件来加载模型,在屏幕上显示它们,转换它们等等.
作为第一阶段,我在不使用OpenGL的情况下编写了一个纯C++程序.它工作得很好,它使用Row-major矩阵表示:
因此,例如mat [i] [j]表示第i行和第j列.
class mat4
{
vec4 _m[4]; // vec4 is a struct with 4 fields
...
}
这是相关的矩阵乘法:
mat4 operator*(const mat4& m) const
{
mat4 a(0.0);
for (int i = 0; i < 4; ++i)
{
for (int j = 0; j < 4; ++j)
{
for (int k = 0; k < 4; ++k)
{
a[i][j] += _m[i][k] * m[k][j];
}
}
}
return a;
}
为了从模型空间到剪辑空间,我在C++中做如下:
vec4 vertexInClipSpace = projectionMat4 * viewMat4 * modelMat4 * …我有一个类型的变量long long,表示以纳秒为单位的时间点。
我正在尝试使用 std::chrono::time_point 包装它,但编译器(VS 2017)给我带来了麻烦。
这是一个编译代码:
std::chrono::time_point<std::chrono::steady_clock> tpStart(std::chrono::nanoseconds(10ll));
std::chrono::time_point<std::chrono::steady_clock> tpEnd = std::chrono::steady_clock::now();
double d = std::chrono::duration<double>(tpEnd - tpStart).count();
现在,如果我10ll用变量切换值,计算持续时间的行将无法编译:
constexpr long long t = 10ll;
std::chrono::time_point<std::chrono::steady_clock> tpStart(std::chrono::nanoseconds(t));
std::chrono::time_point<std::chrono::steady_clock> tpEnd = std::chrono::steady_clock::now();
double d = std::chrono::duration<double>(tpEnd - tpStart).count();
这是错误代码:
错误 C2679:二进制“-”:未找到采用“重载函数”类型的右侧操作数的运算符(或没有可接受的转换)
知道为什么会这样吗?如何将 long long 类型的变量转换为 std::chrono::time_point?
我有很多本机类都接受某种形式的回调,通常是boost::signals2::slot-object。
但是为了简单起见,让我们假设该类:
class Test
{
// set a callback that will be invoked at an unspecified time
// will be removed when Test class dies
void SetCallback(std::function<void(bool)> callback);
}
现在,我有一个包装了该本机类的托管类,并且我想将回调方法传递给本机类。
public ref class TestWrapper
{
public:
TestWrapper()
: _native(new Test())
{
}
~TestWrapper()
{
delete _native;
}
private:
void CallbackMethod(bool value);
Test* _native;
};
现在通常我会执行以下操作:
看起来像这样:
_managedDelegateMember = gcnew ManagedEventHandler(this, &TestWrapper::Callback);
System::IntPtr stubPointer = Marshal::GetFunctionPointerForDelegate(_managedDelegateMember);
UnmanagedEventHandlerFunctionPointer functionPointer = static_cast<UnmanagedEventHandlerFunctionPointer >(stubPointer.ToPointer());
_native->SetCallback(functionPointer);
我想减少代码量,而不必执行任何强制类型转换或声明任何委托类型。我想使用没有委托的lambda表达式。 …
我有一个非常简单的程序,将虚拟红色纹理映射到四边形.
这是C++中的纹理定义:
struct DummyRGB8Texture2d
{
uint8_t data[3*4];
int width;
int height;
};
DummyRGB8Texture2d myTexture
{
{
255,0,0,
255,0,0,
255,0,0,
255,0,0
},
2u,
2u
};
这就是我设置纹理的方法:
void SetupTexture()
{
// allocate a texture on the default texture unit (GL_TEXTURE0):
GL_CHECK(glCreateTextures(GL_TEXTURE_2D, 1, &m_texture));
// allocate texture:
GL_CHECK(glTextureStorage2D(m_texture, 1, GL_RGB8, myTexture.width, myTexture.height));
GL_CHECK(glTextureParameteri(m_texture, GL_TEXTURE_WRAP_S, GL_REPEAT));
GL_CHECK(glTextureParameteri(m_texture, GL_TEXTURE_WRAP_T, GL_REPEAT));
GL_CHECK(glTextureParameteri(m_texture, GL_TEXTURE_MAG_FILTER, GL_NEAREST));
GL_CHECK(glTextureParameteri(m_texture, GL_TEXTURE_MIN_FILTER, GL_NEAREST));
// tell the shader that the sampler2d uniform uses the default texture unit (GL_TEXTURE0)
GL_CHECK(glProgramUniform1i(m_program->Id(), /* location in shader …我在 SEH(结构化异常处理)上阅读的一些文章/答案认为它是“异步的”。
我的理解是这些异常的整个处理部分发生在引发它们的线程上(在 CPU 级别)。基本上,一旦发生异常,执行就会“跳转”到对当前线程异常处理程序列表进行迭代的操作系统代码。
那么我的理解正确吗?SEH 的异步究竟是什么?
c++ ×3
c++11 ×3
cuda ×2
glsl ×2
opengl ×2
amd ×1
boost ×1
boost-asio ×1
boost-python ×1
bus ×1
c++-chrono ×1
c++-cli ×1
exception ×1
gpudirect ×1
latency ×1
matrix ×1
memory ×1
nvidia ×1
opencl ×1
opengl-4 ×1
optimization ×1
pci-bus ×1
pci-e ×1
python ×1
seh ×1
shader ×1
textures ×1
winapi ×1
windows ×1
{kind=link}
{kind=link}