我正在研究一个Ruby gem,它使用可配置的"模板"来生成HTML.我想在gem中包含一组基本模板,并允许用户使用更好/更自定义的模板覆盖它们.这些模板不是Ruby代码,它们只是需要在代码中的某个时刻从磁盘读取的"文件".
我查看了RubyGems文档,但是他们做出了(并非完全不合理)的假设,即gem只包含代码(好的,有一些文档和特定的元数据文件可以用来衡量).没有提到如何创建"/ usr/share/..."文件的等价物.
在gem中包含此类文件的最佳做法是什么?我应该简单地将它们作为"来源"的一部分吗?如果是这样,我如何发现它们的路径,以便我可以将它们从磁盘读入模板处理器?
请考虑以下代码示例:
{-# LANGUAGE FlexibleInstances #-}
{-# LANGUAGE UndecidableInstances #-} -- Is there a way to avoid this?
-- A generic class with a generic function.
class Foo a where
foo :: a -> a
-- A specific class with specific functions.
class Bar a where
bar :: a -> a
baz :: a -> a
-- Given the specific class functions, we can implement the generic class function.
instance Bar a => Foo a where
foo = bar . baz …在以下场景中:
然后,公关审查线评论在公关对话中显示为“过时”,正如它们应该的那样。
然而,作为审阅者,我希望看到的是最新提交上下文中的评论。
例如,查看“与上次审查的提交的差异”,可以看到与最新提交代码相比,审查时的“旧”代码。如果能看到最后一次审阅的注释附加在“旧”代码上,这将非常有帮助,从而允许审阅者决定该行注释是否已修复,或不再相关,或仍然适用于最新代码,或需要修改修改过,或者其他什么。
我目前发现的最好方法是:
这非常乏味且容易出错。有没有更好的办法?希望我只是错过了一些明显(或不那么明显:-) GitHub 功能...
谷歌搜索显示,很多人抱怨 GitHub 代码审查,以及一些可以做很棒事情的附加工具(例如将每个审查评论视为一项任务,这是一个好主意)。
不过,我找不到任何可以帮助跟踪提交之间的行注释的工具。可能有这样的工具存在,但我只是错过了?
编辑:措辞。
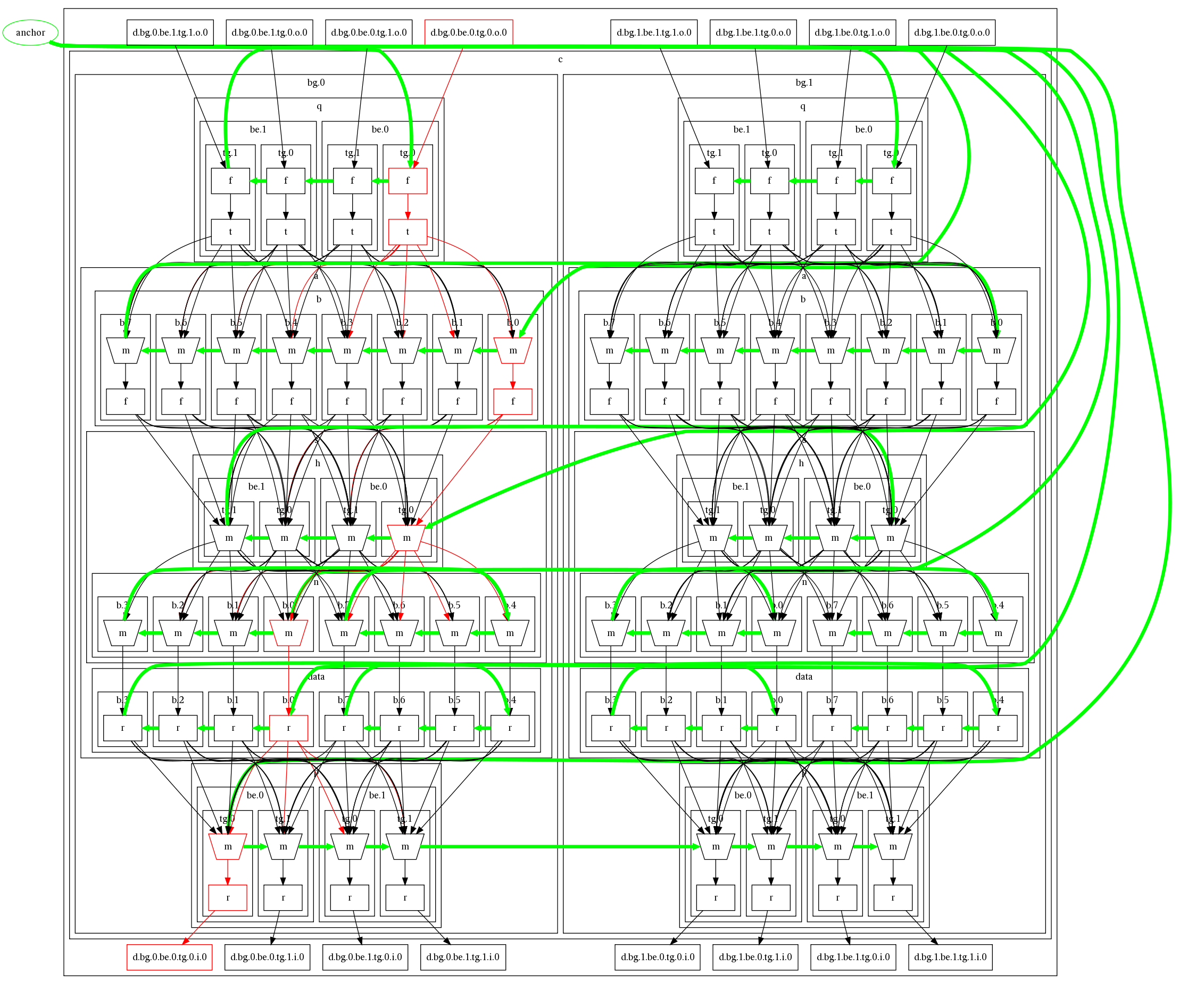
好吧,我知道在GraphViz中对节点进行排序的问题已被扼杀到近乎死亡,但我还没有看到有人解决订购集群的问题.我尝试了书中的所有技巧:
文件中节点的顺序是从左到右.如果我不添加群集,dot只会做正确的事情并以正确的顺序显示它们而不会有任何提示.但是,当添加集群时,点洗牌(随机化?)订单.
我添加了不可见的边缘来尝试强制子集群之间的顺序; 但似乎只要子群集放置在群集内,dot就会决定某个特定的顺序,并且会毫不犹豫地让边缘遍布地图以保留它.
由于节点顺序和不可见边缘使我失望,我转向试图强制节点的位置.这再次失败,因为只有点集群,它忽略输入位置.通过fdp运行未经修改的dot输出(生成的位置)会导致崩溃,所以我也放弃了这个方向.
这是一个示例点文件,它生成下面的图像.绿线是"看不见的"边缘我添加失败尝试强制点从左到右排序一切.如果这是成功的,那么绿线就会从锚点到左边通过节点向右移动,而不会自己交叉.例如,每个be.0将位于其兄弟be.1的左侧,并且类似于tg-s).正如你所看到的那样,dot改变了子簇的顺序(将.1兄弟放在.0的左边).由于某些约束,无论是否有任何边缘,它就好像它是故意这样做的.我无法找到任何方式来说服它做其他事.这非常令人沮丧,因为生成的图表完全符合我的需求.
错误排序的点集群http://www.ben-kiki.org/oren/stackoverflow/diagram.png
所以.是否有任何方法可以强制dot尊重集群内的某些集群顺序?
编辑:进一步研究,看起来群集的默认排序与节点的默认排序相反.也就是说,通常(在TB图中),文本中首先出现的节点将倾向于出现在文本后面出现的节点的左侧 ; 但似乎在文本中首先出现的子群集往往会出现在文本后面出现的子群集的右侧.现在,如果这是一个强硬的规则,生活将是伟大的; 然而,有时(但不常见)点仍然坚持重新排列子簇,不管任何产生的交叉边缘,看起来"只是因为".所以问题仍然存在.
这可能吗?鉴于C#使用不可变字符串,人们可以预期会有一种方法:
var expensive = ReadHugeStringFromAFile();
var cheap = expensive.SharedSubstring(1);
如果没有这样的功能,为什么还要使字符串不变?或者,如果字符串由于其他原因已经不可变,为什么不提供此方法呢?
我正在调查的具体原因是进行一些文件解析.简单的递归下降解析器(例如由TinyPG生成的解析器,或者易于手工编写的解析器)在整个地方使用Substring.这意味着如果你给他们一个大文件来解析,内存流失是令人难以置信的.当然有解决方法 - 基本上是滚动你自己的SubString类,然后当然忘记了能够使用诸如StartsWith之类的String方法或者像Regex这样的字符串库,所以你也需要推出自己的这些版本.我假设像ANTLR这样的解析器生成器基本上就是这样做的,但我的格式很简单,不能证明使用这样的怪物工具.即使是TinyPG也可能是一种矫枉过正.
有人请告诉我,我错过了一些明显或不那么明显的标准C#方法调用...
{kind=link}