小编AJa*_*Jax的帖子
针对每个N的最新记录的最佳执行查询
这是我发现自己的情景.
我有一个相当大的表,我需要查询来自的最新记录.以下是查询基本列的创建:
CREATE TABLE [dbo].[ChannelValue](
[ID] [bigint] IDENTITY(1,1) NOT NULL,
[UpdateRecord] [bit] NOT NULL,
[VehicleID] [int] NOT NULL,
[UnitID] [int] NOT NULL,
[RecordInsert] [datetime] NOT NULL,
[TimeStamp] [datetime] NOT NULL
) ON [PRIMARY]
GO
ID列是主键,VehicleID和TimeStamp上有非Clustered索引
CREATE NONCLUSTERED INDEX [IX_ChannelValue_TimeStamp_VehicleID] ON [dbo].[ChannelValue]
(
[TimeStamp] ASC,
[VehicleID] ASC
)ON [PRIMARY]
GO
我正在努力优化我的查询的表是超过2300万行,并且只是查询需要操作的大小的十分之一.
我需要为每个VehicleID返回最新的行.
我一直在查看StackOverflow上对这个问题的回答,我已经做了很多谷歌搜索,似乎有3或4种常见的方法在SQL Server 2005及更高版本上执行此操作.
到目前为止,我发现的最快的方法是以下查询:
SELECT cv.*
FROM ChannelValue cv
WHERE cv.TimeStamp = (
SELECT
MAX(TimeStamp)
FROM ChannelValue
WHERE ChannelValue.VehicleID = cv.VehicleID
)
使用表中的当前数据量,执行大约需要6秒,这在合理的限制范围内,但是在实时环境中,表将包含的数据量开始执行得太慢.
查看执行计划,我关心的是SQL Server正在做什么来返回行.
我无法发布执行计划图像,因为我的声誉不够高,但索引扫描正在解析表中的每一行,这使得查询速度下降太多.
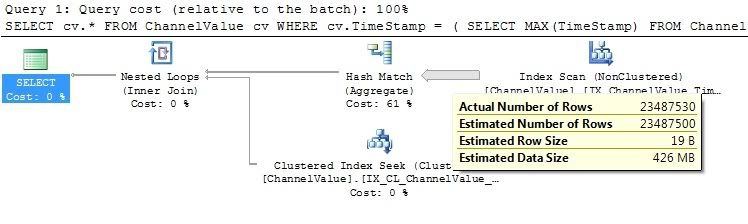
我尝试用几种不同的方法重写查询,包括使用SQL 2005 Partition方法,如下所示: …
t-sql sql-server performance database-performance greatest-n-per-group
16
推荐指数
推荐指数
1
解决办法
解决办法
4960
查看次数
查看次数