小编All*_*rge的帖子
java泛型设计问题(状态机)
我创建了一个状态机,并希望它利用java中的泛型.目前我没有看到我可以使这项工作的方式,并获得漂亮的代码.我确定此设计问题已经多次接近,我正在寻找一些输入.这是一个粗略的轮廓.
class State { ... }
每个不同的状态对象只有一个副本(大多数是与静态最终变量绑定的匿名类),它具有每个状态的自定义数据.每个状态对象都有一个状态父(有一个根状态)
class Message { ... }
每条消息都是单独创建的,每条消息都有自定义数据.他们可以互相分类.有一个根消息类.
class Handler { ... }
每个处理程序只创建一次并处理特定的状态/消息组合.
class StateMachine { ... }
当前跟踪当前状态,以及所有(State,Message) - > Handler映射的列表.它还有其他功能.我试图保持这个类通用,并使用类型参数对其进行子类化,因为它在我的程序中使用了很多次,并且每次使用不同的Message's/State's和Handler's.不同StateMachine的将有不同的参数给他们的处理程序.
方法A.
让状态机跟踪所有映射.
class StateMachine<MH extends MessageHandler> {
static class Delivery {
final State state;
final Class<? extends Message> msg;
}
HashMap<Delivery, MH> delegateTable;
...
}
class ServerStateMachine extends StateMachine<ServerMessageHandler> {
...
}
允许我为这个特定的状态机拥有自定义处理程序方法.可以覆盖handler.process方法的参数.但是,处理程序无法通过消息类型进行参数化.
问题:这涉及instanceof对每个消息处理程序使用健全性检查(确保它获得它期望的消息). …
推荐指数
解决办法
查看次数
如何在python中加速numpy数组填充?
我正在尝试使用以下代码填充预分配的bytearray:
# preallocate a block array
dt = numpy.dtype('u8')
in_memory_blocks = numpy.zeros(_AVAIL_IN_MEMORY_BLOCKS, dt)
...
# write all the blocks out, flushing only as desired
blocks_per_flush_xrange = xrange(0, blocks_per_flush)
for _ in xrange(0, num_flushes):
for block_index in blocks_per_flush_xrange:
in_memory_blocks[block_index] = random.randint(0, _BLOCK_MAX)
print('flushing bytes stored in memory...')
# commented out for SO; exists in actual code
# removing this doesn't make an order-of-magnitude difference in time
# m.update(in_memory_blocks[:blocks_per_flush])
in_memory_blocks[:blocks_per_flush].tofile(f)
一些要点:
num_flushes很低,在4-10左右blocks_per_flush是一个很大的数字,大约数百万in_memory_blocks可以是一个相当大的缓冲区(我把它设置为低至1MB,高达100MB),但时间非常合理......_BLOCK_MAX是8字节无符号整数的最大值m是一个hashilib.md5() …
推荐指数
解决办法
查看次数
在这种情况下,Paxos代理的正确行为是什么?
我正在研究Paxos,我对算法在这个人为的例子中应该如何表现感到困惑.我希望下面的图解释了这个场景.
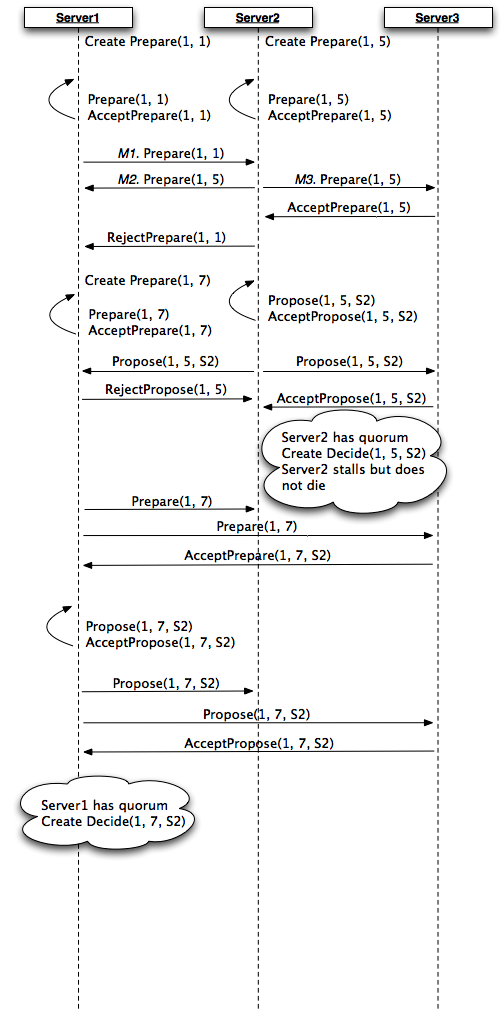
几点:
- 每个代理都充当提议者/接受者/学习者
- 准备消息有形式
(instance, proposal_num) - 建议消息有形式
(instance, proposal_num, proposal_val) - Server1和Server2都决定同时启动提案流程
- 在开始时,消息M1,M2和M3同时发生
在这里似乎虽然协议是"正确的",即只S2选择了一个值,但Server1和Server2认为它是因为提议编号不同而被选中的.
Paxos算法是否仅在将Decide(...)消息发送给学习者时终止?我必须误解Paxos Made Simple,但我认为,当提议者达到他们的Propose(...)消息的法定人数时,就做出了选择.
如果仅在将Decide(...)消息发送给代理之后才进行选择,那么Server2应该Decide(1, 5, S2)在它恢复时终止其发送,因为它稍后会看到它Prepare(1, 7)吗?
推荐指数
解决办法
查看次数
有没有办法获得python array.array()的视图?
我正在生成许多大的"随机"文件(~500MB),其中的内容是重复调用的输出random.randint(...).我想预先分配一个大缓冲区,将long写入该缓冲区,并定期将该缓冲区刷新到磁盘.我目前正在使用,array.array()但我看不到在此缓冲区中创建视图的方法.我需要这样做,以便我可以将有效数据的缓冲区部分输入并将缓冲区hashlib.update(...)的有效部分写入文件.我可以使用切片操作符,但是AFAICT可以创建缓冲区的副本,这不是我想要的.
有没有办法做到这一点,我没有看到?
更新:
我使用numpy作为user42005和hgomersall建议.不幸的是,这并没有给我提供我想要的加速.我的简单的C程序在11s内生成~700MB的数据,而我的python等效使用numpy需要大约700s!很难相信这两者之间的表现差异(我更可能相信我在某处犯了一个天真的错误......)
推荐指数
解决办法
查看次数
标签 统计
python ×2
algorithm ×1
consensus ×1
distributed ×1
generics ×1
java ×1
numpy ×1
optimization ×1
paxos ×1