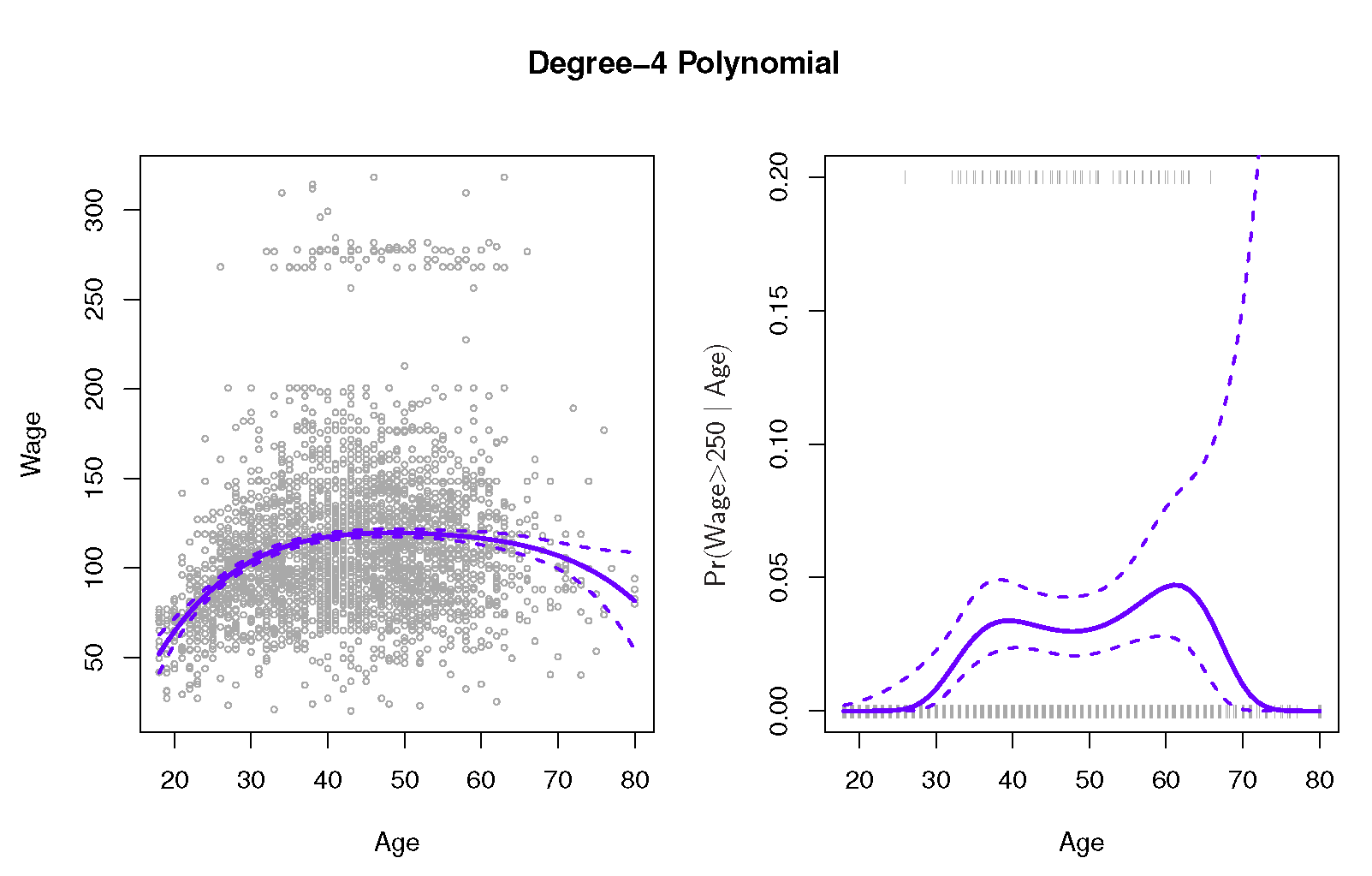
我正在尝试从"统计学习简介"重新创建一个图,我无法弄清楚如何计算概率预测的置信区间.具体来说,我正在尝试重新创建该图的右侧面板(图7.1),该面板预测工资> 250的概率基于4度多项式的年龄和相关的95%置信区间.如果有人关心,工资数据就在这里.
我可以使用以下代码预测并绘制预测概率
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import statsmodels.api as sm
from sklearn.preprocessing import PolynomialFeatures
wage = pd.read_csv('../../data/Wage.csv', index_col=0)
wage['wage250'] = 0
wage.loc[wage['wage'] > 250, 'wage250'] = 1
poly = Polynomialfeatures(degree=4)
age = poly.fit_transform(wage['age'].values.reshape(-1, 1))
logit = sm.Logit(wage['wage250'], age).fit()
age_range_poly = poly.fit_transform(np.arange(18, 81).reshape(-1, 1))
y_proba = logit.predict(age_range_poly)
plt.plot(age_range_poly[:, 1], y_proba)
但我对如何计算预测概率的置信区间感到茫然.我已经考虑过多次引导数据以获得每个时代的概率分布,但我知道有一种更简单的方法,这是我无法掌握的.
我有估计的系数协方差矩阵和与每个估计系数相关的标准误差.如果给出这些信息,我将如何计算上图中右侧面板所示的置信区间?
谢谢!
我有两个不同年份的时间序列存储在熊猫数据框中。例如:
data15 = pd.DataFrame(
[1,2,3,4,5,6,7,8,9,10,11,12],
index=pd.date_range(start='2015-01',end='2016-01',freq='M'),
columns=['2015']
)
data16 = pd.DataFrame(
[5,4,3,2,1],
index=pd.date_range(start='2016-01',end='2016-06',freq='M'),
columns=['2016']
)
我实际上正在使用每日数据,但是如果这个问题得到了足够的解答,我可以弄清楚其余的一切。
我想做的是将这些不同数据集的图叠加到从1月到12月的单个图上,以比较不同年份之间的差异。我可以通过为其中一个数据集创建一个“假”索引来做到这一点,以便它们具有共同的年份:
data16.index = data15.index[:len(data16)]
ax = data15.plot()
data16.plot(ax=ax)
但是我想尽可能避免弄乱索引。这种方法的另一个问题是,年份(2015)将出现在我不希望的x轴刻度标签中。有谁知道更好的方法吗?
{kind=link}