小编hor*_*rux的帖子
删除包含特定单词的行
我想删除包含单词"False"的所有行
例如,如果我有一个包含以下内容的文本文件:
之前
MyEmail@gmx.net|J|1983>2012>3000|Good|[0=%]
MyEmail@hotmail.net|N|1985>2012>3000|False|[~~~'#'***+++~~~]
MyEmail@hotmail.net|N|1985>2012>3000|Good|[$"$!]|Number 2123
后
MyEmail@gmx.net|J|1983>2012>3000|Good|[0=%]
MyEmail@hotmail.net|N|1985>2012>3000|Good|[$"$!]|Number 2123
我应该在Notepad ++中使用哪个正则表达式删除不需要的行?
推荐指数
解决办法
查看次数
从Notepad ++文件中删除行号
我收到了一个很长的文件.它有1000多行SQL代码.每行以行号开头.
14 PROCEDURE sp_processRuleset(pop_id IN NUMBER);
15
16 -- clear procedure for preview mode to clean crom_population_member_temp table and global variables
17 PROCEDURE sp_commit; -- 28-Oct-09 J.Luo
18
19 -- The rule Set string for the Derived Population Member Preview
20 -- The preview mode will set gv_context_ruleSet by setContext_ruleSet,
21 -- sp_processRuleset uses gv_context_ruleSet to build derived population instead of getting rules from crom_rule_set table
22 gv_context_ruleSet VARCHAR2(32767) := NULL; -- 27-Oct-09 J.Luo
23 -- The population Role Id …推荐指数
解决办法
查看次数
Regexp_Extract 分隔字符串中的第 n 个位置
我有一个格式为的字符串:
abc_fjs_dja_sja_dj_sadjasdksa_sdjakd_match_fsja_fsdk
我想要REGEXP_EXTRACT第 8 个分隔位置的字符串(_作为分隔符)。
如何使用 DataStudio 中使用的 Regex 语法来执行此操作?
我已经尝试过这个:(?:[^_]*_){8}(.*?)
但这会匹配字符串的第 8 个分隔段(包括第 8 个分隔段)之前的所有内容,但我只想要第 8 个段。
谢谢
推荐指数
解决办法
查看次数
使用Eclipse中的wsdl文档构建Soap Web服务客户端
我需要使用Eclipse在Java中创建Web服务客户端,使用onvif wsdl.
我花了几个小时没有找到如何做到这一点,这是我第一次使用肥皂,我的经验是在REST.
我尝试了很多像这样的教程来创建Web服务客户端,但是当我尝试从本地磁盘中选择wsdl文件时,eclipse显示了一个错误Could not retrieve the WSDL file ...,我用于文件的链接结构是file:/C:/ONVIF/media.wsdl.
我需要使用任何支持WS-Notification的Java框架来实现我的客户端.
您能否告诉我如何实现使用WSDL文件的客户端Web服务.
我是否需要Web服务器来实现soap Web服务客户端?
如果是,为什么?
推荐指数
解决办法
查看次数
从 Wikidata 获取给定属性的别名值?
对于给定的属性,如'职业 (P106)',我想检索其所有别名,如:专业、工作、工作、职业、就业、工艺。所有这些都存在于属性维基数据页面的“也称为”下。我如何使用 SPARQL 检索此信息?我尝试使用以下查询。
SELECT ?predicate ?object WHERE {
wdt:P106 wdt:P1449 ?predicate . //Nickname
wdt:P106 wdt:P734 ?predicate . //Family Name
wdt:P106 wdt:P735 ?predicate . //Given Name
wdt:P106 skos:altLabel ?predicate .
SERVICE wikibase:label { bd:serviceParam wikibase:language "en". }
}
推荐指数
解决办法
查看次数
更好地理解序言
我试图了解 Prolog 以及它如何使用解析算法。我有这个例子,我发现:
hates(1, 2).
hates(2, 3).
hates(3, 4).
jealous(A, B) :- jealous(A, C), jealous(C,B).
jealous(A,B) :- hates(A,B).
但是当我试图说jealous(1,4)然后它不断溢出并且永远不会产生真时,这很奇怪,好像1讨厌2,2讨厌3,3讨厌4,那么1也应该讨厌4。
但是我尝试改变它,所以它是这样的:
hates(1, 2).
hates(2, 3).
hates(3, 4).
jealous(A,B) :- hates(A,B).
jealous(A, B) :- jealous(A, C), jealous(C,B).
然后当我说jealous(1,4).
推荐指数
解决办法
查看次数
HashSet 添加两个对象,它们为 equals() 返回 true 并且在 Java 中具有相同的哈希码
所述frequencySet()被计算的每个字符的频率String在一个Integer[]包裹成Counter具有被覆盖的equals和哈希码类。此方法应该仅返回集合中的唯一频率,但会添加两个Counter对象。
从打印语句可以看出:hashcode()返回相等的值,并且equals()返回true。
怎么了?
class Ideone
{
public static void main (String[] args) throws java.lang.Exception
{
// your code goes here
String[] a = new String[2];
a[0]="tan";
a[1]="nat";
Set<Counter> s = frequencySet(a);
System.out.println(s.size()); // prints
System.out.println(getFreq(a[0]).equals(getFreq(a[1])) + ":" + getFreq(a[0]).hashcode() + ":" + getFreq(a[1]).hashcode() );
}
public static Set<Counter> frequencySet(String[] strs) {
Set<Counter> set = new HashSet<>();
for(String s: strs){
Counter counter = getFreq(s);
set.add(counter); …推荐指数
解决办法
查看次数
一次性打开 Notepad++ 中的 http:// 链接
http我的记事本++中有一个链接列表,我想一次打开它们,我该怎么做?我尝试了所有的解决方案和快捷方式,但没有得到任何好的结果。
例子:
http://example1.com
http://example2.com
http://example3.com
推荐指数
解决办法
查看次数
如何使用 SPARQL 获取 Wikidata 实体的*所有*超类?
我对可视化维基数据类层次结构感兴趣,以创建像 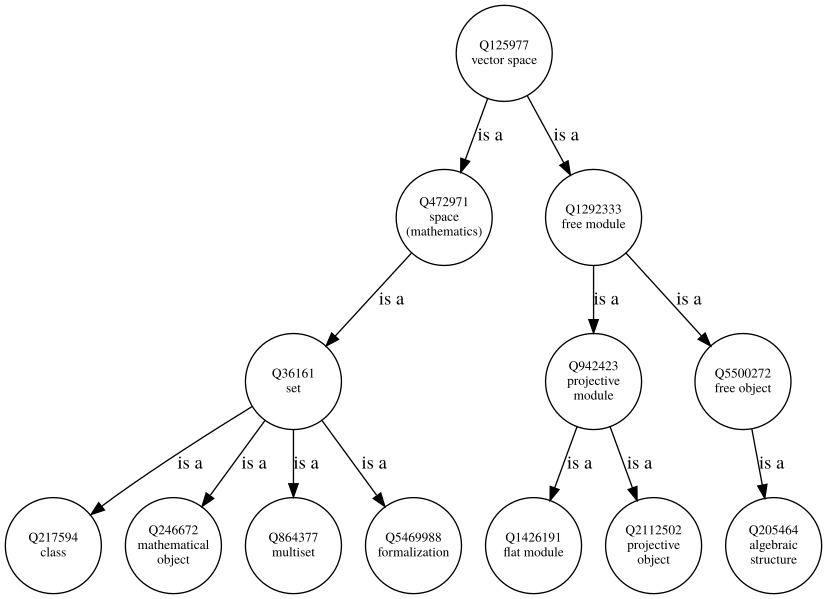
我知道如何获得维基数据实体的直接超类。为此,我使用 SPARQL 代码,例如:
SELECT ?item ?itemLabel
WHERE
{
wd:Q125977 wdt:P279 ?item.
SERVICE wikibase:label { bd:serviceParam wikibase:language "[AUTO_LANGUAGE],en". }
}
其中wdt:P279表示subclass of- 属性。
但是,这种直接方法需要对 Wikidata API 进行多次单一请求。
如何通过单个 SPARQL 查询获得相同的信息?
(请注意,上面的示例图仅显示了一个缩略版本。所有超类的最终所需图为 13 层深,有 69 个节点,这意味着 68 个单个请求,如果有兴趣,请参阅此 jupyter notebook。)
推荐指数
解决办法
查看次数
O(mn) 比 O((m+n)^2) 好吗?
算法的输入是m和n。
我的算法的时间复杂度为O(mn).
我有一个时间复杂度为O((m+n)²).
在时间复杂度方面,我的实现是否比基准测试更好?
推荐指数
解决办法
查看次数