我有一个网格化数据集,可在以下位置获得数据:
lon <- seq(-179.75,179.75, by = 0.5)
lat <- seq(-89.75,89.75, by = 0.5)
我想找到位于该位置500公里范围内的所有数据点:
mylat <- 47.9625
mylon <- -87.0431
我的目标是在R中使用geosphere包,但我目前编写的方法效率似乎不高:
require(geosphere)
dd2 <- array(dim = c(length(lon),length(lat)))
for(i in 1:length(lon)){
for(ii in 1:length(lat)){
clon <- lon[i]
clat <- lat[ii]
dd <- as.numeric(distm(c(mylon, mylat), c(clon, clat), fun = distHaversine))
dd2[i,ii] <- dd <= 500000
}
}
在这里,我循环遍历数据中的每个网格,并查找距离是否小于500 km.然后我存储一个TRUE或FALSE变量,然后我可以使用它来平均数据(其他变量).从这个方法,我想要一个TRUE或FALSE的矩阵,用于距离lat和lon 500公里范围内的位置.有没有更有效的方法来做到这一点?
我已经生成了三个相同的波,每个波都有一个相移.例如:
t = 1:10800; % generate time vector
fs = 1; % sampling frequency (seconds)
A = 2; % amplitude
P = 1000; % period (seconds), the time it takes for the signal to repeat itself
f1 = 1/P; % number of cycles per second (i.e. how often the signal repeats itself every second).
y1 = A*sin(2*pi*f1*t); % signal 1
phi = 10; % phase shift
y2 = A*sin(2*pi*f1*t + phi); % signal 2
phi = 15; % phase shift …是否有可能找到一个向量的非纳米值,但也允许n个nans?例如,如果我有以下数据:
X = [18 3 nan nan 8 10 11 nan 9 14 6 1 4 23 24]; %// input array
thres = 1; % this is the number of nans to allow
我想只保留最长的非nans值序列,但允许在数据中保留'n'个nans.所以,说我愿意保持1纳米,我会有一个输出
X_out = [8 10 11 nan 9 14 6 1 4 23 24]; %// output array
那就是,开头的两个nans已被删除,因为它们超过了'thres'中的值,但是第三个nan本身就可以保存在数据中.我想开发一种方法,可以将thres定义为任何值.
我可以找到非纳米值
Y = ~isnan(X); %// convert to zeros and ones
有任何想法吗?
我从一个网站下载了一些气候数据,并试图在 R 中对其进行分析。
数据的时间格式是自 1800-01-01 00:00 以来的小时数。例如:
ss <- seq(447042,455802, length.out = 1461)
它以 6 小时为间隔显示数据。
如何将其转换为 R 中的实际时间。此示例应提供 1851 的数据:
1851-01-01 00:00
1851-01-01 06:00
等等...
如何才能做到这一点?
任何意见,将不胜感激。
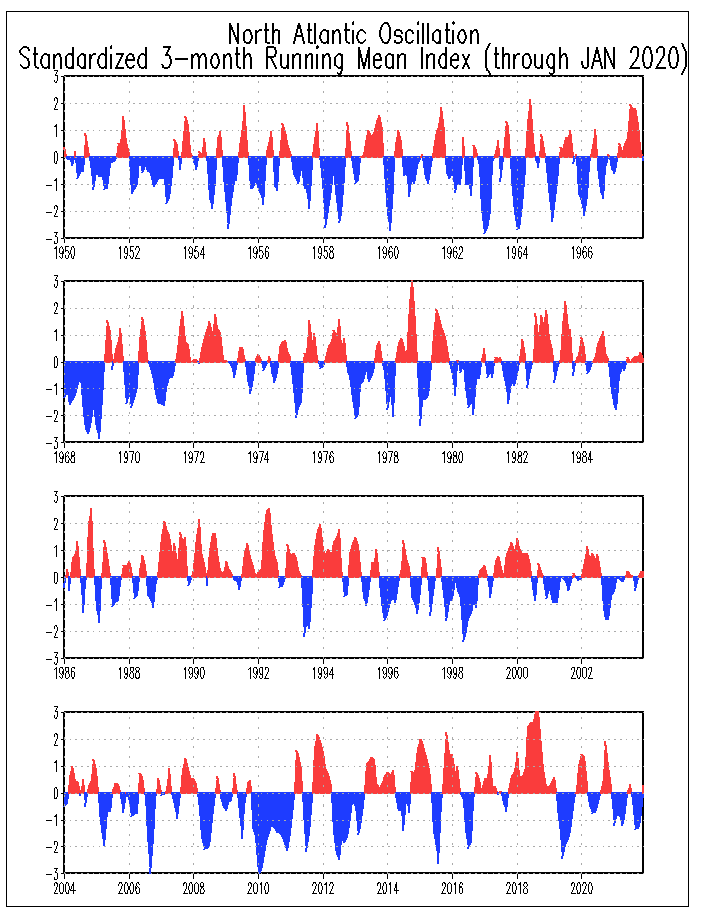
我正在尝试生成如下所示的数字:
图http://www.cpc.ncep.noaa.gov/data/teledoc/nao.timeseries.gif
我在这里可以找到用于尝试生成此图的数据.
这是我提取的数据的子集:
d = [1950 1 0.56
1950 2 0.01
1950 3 -0.78
1950 4 0.65
1950 5 -0.50
1950 6 0.25
1950 7 -1.23
1950 8 -0.19
1950 9 0.39
1950 10 1.43
1950 11 -1.46
1950 12 -1.03
1951 1 -0.42
1951 2 0.35
1951 3 -1.47
1951 4 -0.38
1951 5 -0.50
1951 6 -1.35
1951 7 1.39
1951 8 -0.41
1951 9 -1.18
1951 10 2.54
1951 11 -0.54
1951 12 1.13 …我已经下载了一些气候再分析数据,花了很多时间从grib转换为cdf,最后我已经设法让它在R中工作.我的下一个问题是时间是一个字符向量,类似于下列:
tt =c(
"20090101","20090101.25","20090101.5","20090101.75","20090102",
"20090102.25","20090102.5","20090102.75","20090103","20090103.25",
"20090103.5","20090103.75","20090104","20090104.25","20090104.5",
"20090104.75")
前四位数是年份,后面是月份,然后是白天,最后是一天中的一小部分:yyyymmdd ...
如何用格式yyyy-mm-dd HH:MM将其转换为posixct时间?
我会尝试
as.POSIXct(TT, '%Y%米%d')
但由于日间分数,这在这里不会有所帮助.
最终结果应该是:
tt
[1] "2009-01-01 00:00" "2009-01-01 06:00" "2009-01-01 12:00"
"2009-01-01 18:00" "2009-01-02 00:00"
谁有人建议解决方案?
注意:我可以用一半的方式
as.Date(tt, "%Y%m%d")
但不知道如何处理分数
如果我有两个时间序列,例如:
t <- seq(1,30)
y1 <- 4*sin(t*(2*pi/4) + 3)
y2 <- 4*cos(t*(2*pi/4) + 3)
plot(t,y1, type = 'l')
lines(t,y2, col = 'red')
我可以使用以下方法计算matlab中信号之间的相位差:
[Pxy,Freq] = cpsd(y1,y2);
coP = real(Pxy);
quadP = imag(Pxy);
phase = atan2(quadP,coP);
我如何在R中实现同样的目标?我可以使用什么函数来估计R中两个时间序列之间的相位差
我有一个问题,不确定我是否在这里完全傻了,或者这是一个真正的问题,还是我误解了这些功能的作用。
diff的对立与cumsum是否相同?我以为是。但是,使用此示例:
dd <- c(17.32571,17.02498,16.71613,16.40615,
16.10242,15.78516,15.47813,15.19073,
14.95551,14.77397)
par(mfrow = c(1,2))
plot(dd)
plot(cumsum(diff(dd)))
> dd
[1] 17.32571 17.02498 16.71613 16.40615 16.10242 15.78516 15.47813 15.19073 14.95551
[10] 14.77397
> cumsum(diff(dd))
[1] -0.30073 -0.60958 -0.91956 -1.22329 -1.54055 -1.84758 -2.13498 -2.37020 -2.55174
这些不一样。我哪里出问题了?
啊!星期五。
明显
我正在学习如何使用fortran进行一些数据分析.我正在通过以下示例:
program linalg
implicit none
real :: v1(3), v2(3), m(3,3)
integer :: i,j
v1(1) = 0.25
v1(2) = 1.2
v1(3) = 0.2
! use nested do loops to initialise the matrix
! to the unit matrix
do i=1,3
do j=1,3
m(i,j) = 0.0
end do
m(i,j) = 1.0
end do
! do a matrix multiplicationof a vector equivalent to v2i = mij v1j
do i = 1,3
v2(i) = 0.0
do j = 1,3
v2(i) = v2(i) + m(i,j)*v1(j)
end …如何在matlab中使用'find'来查找超过给定阈值的最长可能值序列.例如,如果我有:
X = [18 3 1 11 8 10 11 3 9 14 6 1 4 3 15 21 23 24];
并且想要找到大于8的值,我会输入:
find(X > 8)
但是,我想在数组中找到大于给定值的最长连续值序列.在这里,答案是:
15 21 23 24
有没有办法在matlab中实现这一目标?
使用以下方法估算MATLAB中的确定系数:
load hospital
y = hospital.BloodPressure(:,1);
X = double(hospital(:,2:5));
X2 = X(:,3);
mdl = fitlm(X2,y);
Estimated Coefficients:
Estimate SE tStat pValue
________ ________ ______ __________
(Intercept) 116.72 3.9389 29.633 1.0298e-50
x1 0.039357 0.025208 1.5613 0.12168
Number of observations: 100, Error degrees of freedom: 98
Root Mean Squared Error: 6.66
R-squared: 0.0243, Adjusted R-Squared 0.0143
F-statistic vs. constant model: 2.44, p-value = 0.122
如果我只在线性模型中使用一个预测变量,为什么R 2和adjust-R 2值不相同.如果模型中只有一个预测变量,则它们应该是可互换的.我在这里错过了什么?
我有一个以下列格式提供的日期时间:
ex <-2008123118
我正在尝试将其转换为日期时间格式.我尝试:
mytime2 <- as.POSIXct(ex, format = "%Y%m%d%H")
但收到错误:
Error in as.POSIXct.numeric(ex, format = "%Y%m%d%H") :
'origin' must be supplied
错误似乎是直截了当的,但唯一的问题是,如果我不知道原点.例如,我的代码的这部分将进入一个更大的代码,将处理大量的文件.
我希望我的例子能够回归:
2008-12-31 18:00
那可能吗?
r ×6
matlab ×5
arrays ×1
fortran ×1
geosphere ×1
phase ×1
posixct ×1
regression ×1
statistics ×1
{kind=link}