我正在尝试将拉丁语unicode字符规范化为小写形式.我以为我可以在unicode对象上使用.lower函数,但似乎没有覆盖unicode的某些部分 - 特别是这个块有一些不小写的字符:0xa7a0,0xa7a2,0xa7b6,0xa79e,0xa79a,0xa790 all调用.lower时返回相同的字符.我不期待看到很多这些字符,所以通过所有相关块来修复那些无法正确转换的块是浪费时间的.是否有更完整的小写unicode功能,或者这是一个区域设置问题?
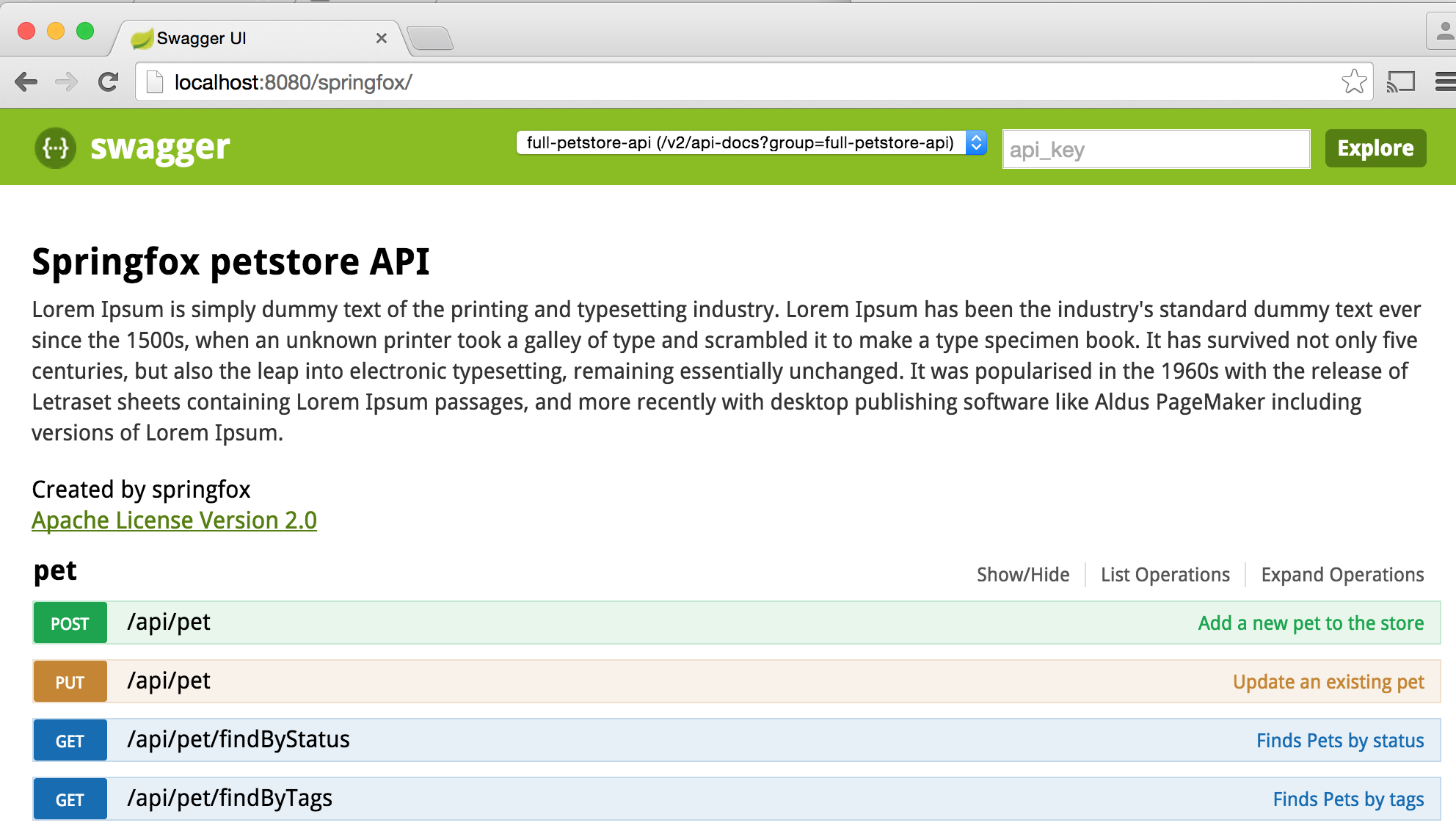
我正在构建一个Spring Boot应用程序,并使用Springfox Swagger UI的Swagger UI对其进行文档化。我已经记录了所有内容,但是想自定义标题和描述,但不知道如何做。例如,在此图像中:https : //springfox.github.io/springfox/docs/current/images/springfox-swagger-ui.png标题为“ Springfox petstore API”,描述为Lorem Ipsum。但是在我的Swagger UI中,标题和描述都说“ API Documentation”。我尝试使用@SwaggerDefinition批注,但是它似乎没有任何作用。
我试图使用re.UNICODE标志来匹配可能包含unicode字符的字符串,但它似乎没有工作.例如:
Python 2.7.12 (default, Dec 4 2017, 14:50:18)
[GCC 5.4.0 20160609] on linux2
Type "help", "copyright", "credits" or "license" for more information.
>>> import re
>>> r = re.compile(ur"(\w+)", re.UNICODE)
>>> r.findall(u"test test test", re.UNICODE)
[]
它可以工作,如果我没有指定unicode标志,但显然它不适用于unicode字符串.为了让这个工作,我需要做什么?
{kind=link}