小编Mat*_*ttV的帖子
将R data.frame复制到Excel电子表格
作为我工作的一部分,我必须将R Studio控制台的输出复制到excel工作表才能制作excel图表.但是,R Studio控制台使用格式化文本,excel读取效果不佳.为了补偿,我总是从R Studio控制台复制,粘贴到记事本,然后复制到Excel.这样,当我粘贴一个表时,我可以告诉excel它实际上是固定宽度分隔的数据,而不仅仅是一堆文本.
如何从R Studio控制台复制输出,使其作为无格式文本进入剪贴板,以便我可以将其直接粘贴到Excel中,从而将数字组织到不同的单元格中?这将非常有用,因为我不喜欢将表复制/粘贴到记事本中然后擅长制作图表.
推荐指数
解决办法
查看次数
像HTML构造函数一样可以旋转,没有聚合来显示分组元素
我正在尝试构建一个HTML组件,它将为我的数据提供类似于pivottable的视图,但是在pivotarea中使用自定义html元素而不是总和或计数; 在下面的例子中,我将只使用一串文本,但我希望它是任何HTML元素(img,div,文本等).
我发现很难选择一个方向,编写我自己的代码来生成它(使用jQuery)或使用像Pivottable这样的库.我已经尝试了后者,但甚至无法找到定制聚合器功能的正确方向.
我可以看到自己重新使用js pivottable生成的html(带有一个简单的计数),然后在jQuery中附加项目,但这似乎是一个相当hacky的解决方案,同时缺乏自定义选项.这种方法的优点包括这样一个事实,即在某些时候我想在web-ui中包含对colums的过滤/定制.
我在找什么?给定一个JSON数组,其中多行具有属性[Columngroup1,Columngroup2]和[Rowgroup 1,rowgroup2,rowgroup3],我想根据以下内容进行布局(在Tableau中内置):
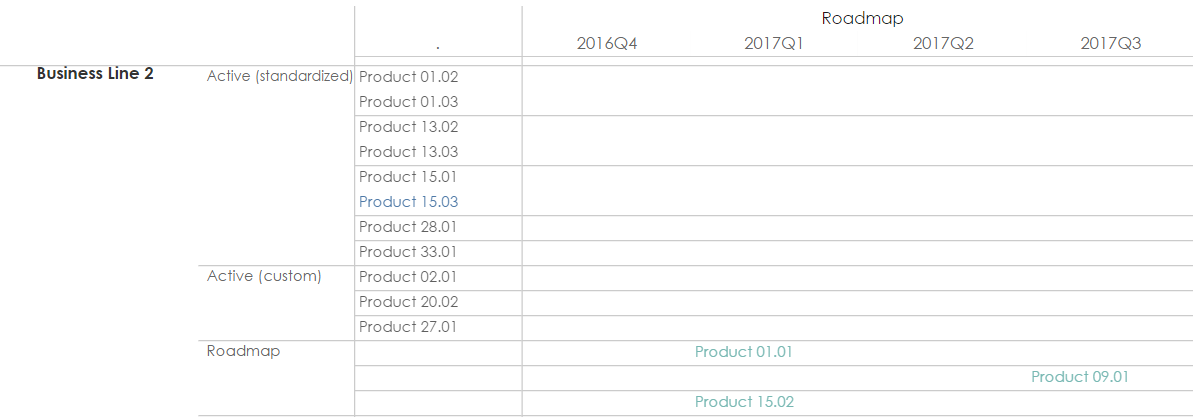
在上面的示例中,[Businessline,Type,Product]是行组,[Active_or_roadmap,Roadmap Quarter]是列组.数据集的粒度更深一层,每个"产品"可以包含多个子产品,这些子产品应放在"活动"列(句点标题)或路线图季度列之一.这可以通过子产品15.03和15.01在视觉上分组在同一"行"中看出.
我面临什么困难?
- 我是否使用HTML表格,我应该使用带有指示行/列的类的div,还是两者的组合?增加了复杂性:在某些时候,我希望非标题列水平"滚动"(如果太宽).
- 在我想过滤掉一些行的情况下,我应该重新生成整个表还是(误)使用可见性:隐藏?在后一种情况下:我将如何处理部分过滤的产品组(即副产品15.01不应该可见,副产品15.03确实需要可见)
- 我如何在DOM元素中"嵌入"对象细节?即,在hover/clickevent的情况下,我如何知道JSON对象中的哪一行对应于被点击的名称?
请注意,我不一定要找到一个完全按照我上面所说的完成的答案,我主要是寻找一个方向,使代码从结构上体面和灵活的方式从JSON转到上表.
非常感谢任何帮助,我有一个包含一些示例数据和相当差的尝试的codepen.
function load_data(callback){
$.getJSON('https://s3-us-west-2.amazonaws.com/s.cdpn.io/997352/data_portfolioroadmap.json', function(data){
callback(data)
});
}
推荐指数
解决办法
查看次数
如何使用BZ2 JSON twitter文件有效地读取大型(30GB +)TAR文件到PostgreSQL中
我正在尝试从archive.org存档中获取twitter数据并将其加载到数据库中.我试图首先加载特定月份的所有推文,然后选择推文并且只播放我感兴趣的那些(例如通过locale或hashtag).
我能够运行下面描述的脚本来完成我正在寻找的东西,但我有一个问题,那就是速度非常慢.它运行了大约半小时,只读取了一个TAR文件中的~6/50,000内部.bz2文件.
示例TAR文件的一些统计信息:
- 总大小:~30-40GB
- 内部.bz2文件的数量(排列在文件夹中):50,000
- 一个.bz2文件的大小:~600kb
- 一个提取的JSON文件的大小:~5 MB,~3600条推文.
在优化此流程以提高速度时,我应该寻找什么?
- 我应该将文件解压缩到磁盘而不是在Python中缓存它们吗?
- 我应该看一下多线程的一部分过程吗?该过程的哪一部分最适合这个?
- 或者,我目前获得的速度是否相对正常?
该脚本目前占用了我3%的CPU和约6%的RAM内存.
任何帮助是极大的赞赏.
import tarfile
import dataset # Using dataset as I'm still iteratively developing the table structure(s)
import json
import datetime
def scrape_tar_contents(filename):
"""Iterates over an input TAR filename, retrieving each .bz2 container:
extracts & retrieves JSON contents; stores JSON contents in a postgreSQL database"""
tar = tarfile.open(filename, 'r')
inner_files = [filename for filename in tar.getnames() if filename.endswith('.bz2')]
num_bz2_files = len(inner_files)
bz2_count = 1 …推荐指数
解决办法
查看次数
规范化大型表中的多值列
我在将此帖中看到的VBA代码转换为R脚本时遇到问题.
问题如下,我有一个列(来自源数据库,而不是选择)包含属性的多个值.我想规范化这个表并保留每个单元格中每个值出现的顺序.
示例数据集:
dat <- data.frame(
ID = c(1:3),
Multi = c("VAL1 VAL2 VAL3","VAL2 VAL3","VAL3 VAL1")
,stringsAsFactors=FALSE)
ID Multi
1 1 VAL1 VAL2 VAL3
2 2 VAL2 VAL3
3 3 VAL2 VAL3 VAL1
伪代码类似于:
- 循环遍历每一行
- 拆分字符串Multi,空格作为分隔符
- 对于每个拆分的字符串,将新行附加到单独的data.frame中,其中包含ID,总计字符串中的Order和值.
结果如下:
ID Order Multi
1 1 1 VAL1
2 1 2 VAL2
3 1 3 VAL3
4 2 1 VAL2
5 2 2 VAL3
6 3 1 VAL2
7 3 2 VAL3
8 3 3 VAL1
我目前正在考虑使用data.frame,我认为data.table更合适,因为我的表将有大约400.000这些行.
我为没有准备任何代码而道歉,我仍在考虑是否需要使用apply系列,data.table或简单的for循环.我将保持这篇文章更新我所取得的任何进展.
推荐指数
解决办法
查看次数
一个表中两个数据集的分类汇总统计(比较)
我在制作一个表格时遇到了问题,该表格总结了我的两个数据集及其分类变量,这是一个我在各种论文中经常看到的格式的表格.
问题如下,我有两个数据集(一个比另一个过滤得多一点),我想并排显示他们的分类汇总统计数据.使用两个数据集:
A <- head(mtcars[, c(2, 8:11)])
cyl vs am gear carb
Mazda RX4 6 0 1 4 4
Mazda RX4 Wag 6 0 1 4 4
Datsun 710 4 1 1 4 1
Hornet 4 Drive 6 1 0 3 1
Hornet Sportabout 8 0 0 3 2
Valiant 6 1 0 3 1
B <- head(mtcars[3:6, c(2, 8:11)])
cyl vs am gear carb
Datsun 710 4 1 1 4 1
Hornet 4 Drive 6 1 0 3 1 …推荐指数
解决办法
查看次数
使用Marionette添加Firefox的第二个实例(更改端口)
我很难通过木偶创建两个firefox实例.有一个实例正常工作:
启用带有木偶的Firefox启动:
firefox.exe -marionette
用python控制它:
from marionette import Marionette
client = Marionette('localhost', port=2828)
client.start_session()
client.execute_script("alert('o hai there!');")
现在我想添加第二个客户端和当前客户端,快速搜索导致--address命令:
firefox.exe -marionette --address=localhost:2829
试图通过python控制它:
from marionette import Marionette
client = Marionette('localhost', port=2829)
client.start_session()
client.execute_script("alert('o hai there!');")
但是,我似乎无法使其工作:
error: [Errno 10061] No connection could be made because the target machine actively refused it
任何帮助是极大的赞赏.
推荐指数
解决办法
查看次数
使用参数对象调用 Powershell 函数
是否可以像这样创建一个对象
$Data = new-object PSObject
$Data | Add-member NoteProperty -Name "SiteName" -Value "Web Title"
$Data | Add-member NoteProperty -Name "SiteURL" -Value "https://www.test.url"
然后以某种方式调用一个函数
Do-CustomFunction $Data
这将解包对象并将其属性用作命名参数,以模拟以下行为:
Do-CustomFunction -SiteName "Web Title" -SiteURL "https://www.test.url"
推荐指数
解决办法
查看次数
AttributeError:'module'对象在TwitterAPI调用中没有属性'loads'(迭代推文)?
当运行TwitterAPI页面上的示例代码在这里,我收到以下错误.
Traceback (most recent call last):
File "D:/Cloud/Dropbox/Coding/Python/EUR - BigData & Analytics/Workshops/Tutorial 2/twitter_query_scraper_revisited.py", line 76, in <module>
for tweet in tweet_sequence:
File "C:\Python33\lib\site-packages\TwitterAPI\TwitterAPI.py", line 116, in __iter__
for item in self.get_iterator():
File "C:\Python33\lib\site-packages\TwitterAPI\TwitterAPI.py", line 113, in get_iterator
return RestIterator(self.response)
File "C:\Python33\lib\site-packages\TwitterAPI\TwitterAPI.py", line 139, in __init__
resp = response.json()
File "C:\Python33\lib\site-packages\requests\models.py", line 741, in json
return json.loads(self.text, **kwargs)
AttributeError: 'module' object has no attribute 'loads'
我试过运行各种代码,但我一直无法解决它.这是我正在运行的代码:
from TwitterAPI import TwitterAPI
api = TwitterAPI(consumer_key, consumer_secret, access_token_key, access_token_secret)
r = api.request('search/tweets', …推荐指数
解决办法
查看次数
通过一个快捷方式激活 Python 虚拟环境并更改目录(使用 cmd)
我正在尝试执行以下操作:
本质上,我需要顺序执行以下命令:
C:\Envs\djangorocks\Scripts\activate
cd "D:\GitHub\steelrumors"
我找到了这个链接,但是创建如下快捷方式没有给我带来任何好处(只是在当前活动目录中显示一个简单的 CMD 提示符):
cmd \k "C:\Envs\djangorocks\Scripts\activate" & "cd "D:\GitHub\steelrumors""
经过一段时间的搜索后,我仍然手动进行,任何帮助都是值得赞赏的。
推荐指数
解决办法
查看次数
标签 统计
python ×3
r ×3
batch-file ×1
cmd ×1
copy ×1
data.table ×1
excel ×1
firefox ×1
html ×1
javascript ×1
jquery ×1
json ×1
powershell ×1
rstudio ×1
twitter ×1
windows ×1