小编deo*_*ksu的帖子
如何使用ggplot2中的多个变量更好地创建堆积条形图?
我经常需要制作堆积的条形图来比较变量,因为我在R中完成所有的统计数据,所以我更喜欢使用ggplot2来完成R中的所有图形.我想学习如何做两件事:
首先,我希望能够为每个变量添加适当的百分比刻度标记,而不是按计数添加刻度标记.计数会令人困惑,这就是我完全取出轴标签的原因.
其次,必须有一种更简单的方法来重组我的数据以实现这一目标.看起来我应该能够在ggplot2中使用plyR进行本地操作,但是plyR的文档不是很清楚(我已经阅读了ggplot2书籍和在线plyR文档.
我最好的图表看起来像这样,创建它的代码如下:
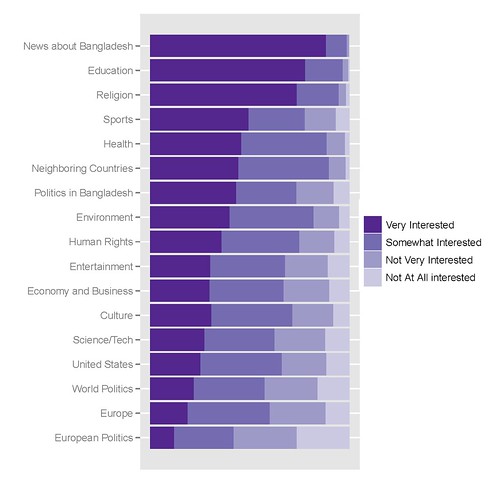
我用来获取它的R代码如下:
library(epicalc)
### recode the variables to factors ###
recode(c(int_newcoun, int_newneigh, int_neweur, int_newusa, int_neweco, int_newit, int_newen, int_newsp, int_newhr, int_newlit, int_newent, int_newrel, int_newhth, int_bapo, int_wopo, int_eupo, int_educ), c(1,2,3,4,5,6,7,8,9, NA),
c('Very Interested','Somewhat Interested','Not Very Interested','Not At All interested',NA,NA,NA,NA,NA,NA))
### Combine recoded variables to a common vector
Interest1<-c(int_newcoun, int_newneigh, int_neweur, int_newusa, int_neweco, int_newit, int_newen, int_newsp, int_newhr, int_newlit, int_newent, int_newrel, int_newhth, int_bapo, int_wopo, int_eupo, int_educ)
### Create a second vector to label the first vector by original variable ###
a1<-rep("News …推荐指数
解决办法
查看次数
编程R/Sweave以获得正确的\ Sexpr输出
我在为Sweave编程R时遇到了一些问题,#rstats twitter组经常指向这里,所以我想我会把这个问题提到SO人群中.我是一名分析师 - 而不是程序员 - 所以在我的第一篇文章中轻松一点.
问题在于:我正在起草一份带有R的Sweave调查报告,并希望报告边际收益\Sexpr{}.例如,而不是说:
只有14%的受访者表示'X'.
我想写这样的报告:
只有\ Sexpr {p.mean(variable)} $ \%$的受访者表示'X'.
的问题是,Sweave表达式的结果转换中\Sexpr{}为字符串,这意味着从在R和表达出现我的文档中的输出的输出是不同的.例如,上面我使用函数'p.mean':
Run Code Online (Sandbox Code Playgroud)p.mean<- function (x) {options(digits=1) mmm<-weighted.mean(x, weight=weight, na.rm=T) print(100*mmm) }
在R中,输出如下所示:
Run Code Online (Sandbox Code Playgroud)p.mean(variable) >14
但是当我使用时\Sexpr{p.mean(variable)},我的文档中会得到一个未连接的字符串(在本例中为13.5857142857143).我试图将函数的输出限制digits=1在全局环境,函数本身和各种命令中.它似乎只包含R打印,而不是表达式结果的字符转换,最终打印在LaTeX文件中.
Run Code Online (Sandbox Code Playgroud)as.character(p.mean(variable)) >[1] 14 >[1] "13.5857142857143"
有谁知道我可以,或者通过重新编程R函数或与Sweave或设置做以限制LaTeX的文件打印的数字\Sexpr{}?
推荐指数
解决办法
查看次数