小编D W*_*D W的帖子
LaTeX 中的双行双语段落
行间光泽可用于布置文档的翻译。
http://en.wikipedia.org/wiki/Interlinear_gloss
通常这是一个词一个词或一个词素一个词素完成的。但是,我想以不同的方式做到这一点,一次翻译整个段落。以下链接和图像是我想要完成的示例,但我想为更大的不同文本执行此操作。
http://www.optimnem.co.uk/learning/spanish/three-little-pigs.php
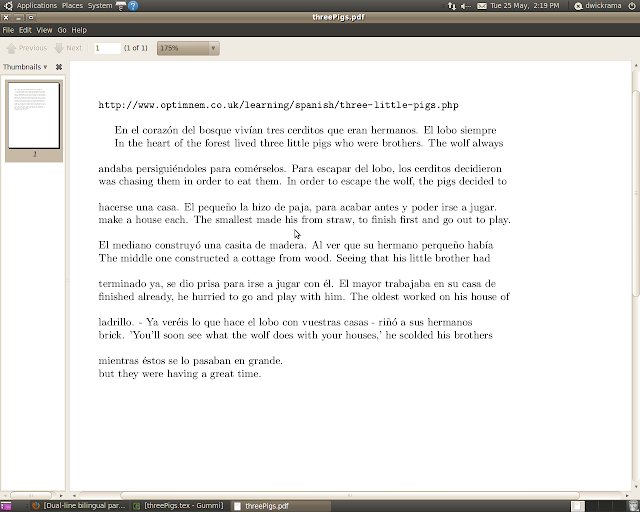
目前我对考虑在语言之间改变顺序的单词或短语的顺序不感兴趣。也就是说,我不介意段落中的单词是否对齐,或者一个段落的长度是否比另一个段落长得多,从而导致悬垂线。
据我所知,以下软件包不能满足我的需求:
covingtn.sty
cgloss4e.sty
gb4e.sty
lingmacros.sty - shortex
这是英文版本:
In the heart of the forest lived three little pigs who were brothers. The wolf always was chasing them in order to eat them. In order to escape the wolf, the pigs decided to make a house each. The smallest made his from straw, to finish first and go out to play. The middle one constructed a cottage from wood. Seeing that his little brother had finished …5
推荐指数
推荐指数
1
解决办法
解决办法
2848
查看次数
查看次数
使用LaTeX清单正确检测并语法突出显示脚本中不同语言的嵌入代码
我的脚本有单行或其他语言的脚本.如何让LaTeX列表检测到这一点并更改脚本中的语法格式化语言?这对于我认为的bash中的awk特别有用.
巴什
#!/bin/bash
echo "hello world"
R --vanilla << EOF
# Data on motor octane ratings for various gasoline blends
x <- c(88.5,87.7,83.4,86.7,87.5,91.5,88.6,100.3,
95.6,93.3,94.7,91.1,91.0,94.2,87.5,89.9,
88.3,87.6,84.3,86.7,88.2,90.8,88.3,98.8,
94.2,92.7,93.2,91.0,90.3,93.4,88.5,90.1,
89.2,88.3,85.3,87.9,88.6,90.9,89.0,96.1,
93.3,91.8,92.3,90.4,90.1,93.0,88.7,89.9,
89.8,89.6,87.4,88.9,91.2,89.3,94.4,92.7,
91.8,91.6,90.4,91.1,92.6,89.8,90.6,91.1,
90.4,89.3,89.7,90.3,91.6,90.5,93.7,92.7,
92.2,92.2,91.2,91.0,92.2,90.0,90.7)
x
length(x)
mean(x);var(x)
stem(x)
EOF
perl -n -e '
@t = split(/\t/);
%t2 = map { $_ => 1 } split(/,/,$t[1]);
$t[1] = join(",",keys %t2);
print join("\t",@t); ' knownGeneFromUCSC.txt
awk -F'\t' '{
n = split($2, t, ","); _2 = x
split(x, _) # use delete _ if supported …5
推荐指数
推荐指数
1
解决办法
解决办法
5834
查看次数
查看次数
Uniq in awk; 使用awk删除列中的重复值
我有一个大型数据文件,格式如下:
ENST00000371026 WDR78,WDR78,WDR78, WD repeat domain 78 isoform 1,WD repeat domain 78 isoform 1,WD repeat domain 78 isoform 2,
ENST00000371023 WDR32 WD repeat domain 32 isoform 2
ENST00000400908 RERE,KIAA0458, atrophin-1 like protein isoform a,Homo sapiens mRNA for KIAA0458 protein, partial cds.,
列是制表符分隔的.列中的多个值以逗号分隔.我想删除第二列中的重复值,结果如下所示:
ENST00000371026 WDR78 WD repeat domain 78 isoform 1,WD repeat domain 78 isoform 1,WD repeat domain 78 isoform 2,
ENST00000371023 WDR32 WD repeat domain 32 isoform 2
ENST00000400908 RERE,KIAA0458 atrophin-1 like protein isoform a,Homo sapiens mRNA for KIAA0458 protein, …4
推荐指数
推荐指数
1
解决办法
解决办法
4953
查看次数
查看次数
4
推荐指数
推荐指数
1
解决办法
解决办法
230
查看次数
查看次数
将bash中逗号分隔数据包装到固定行长度
您好我想包装以下逗号分隔数据:
-X, run, abs, absolute, accept, accept, alarm, schedule, atan2, arctangent, bind, binds, binmode, prepare, bless, create, caller, get, chdir, change, chmod, changes, chomp, remove, chop, remove, chown, change, chr, get, chroot, make, close, close, closedir, close, connect, connect, continue, optional, cos, cosine, crypt, one-way, dbmclose, breaks, dbmopen, create, defined, test, delete, deletes, die, raise, do, turn, dump, create, each, retrieve, endgrent, be, endhostent, be, endnetent, be, endprotoent, be, endpwent, be, endservent, be, eof, test, eval, catch, exec, abandon, exists, …1
推荐指数
推荐指数
2
解决办法
解决办法
1552
查看次数
查看次数
在R中绘制两条线,斜率是最佳拟合线的两倍和一半的值
我有最适合的线条绘制数据.我需要绘制另外两行.一个需要有两倍的斜率,另一个需要有一半的斜率.稍后我将使用该区域对其外部的点进行差分着色: 有条件地将颜色数据点放在R中的置信区间之外
示例数据集:
## Dataset from http://www.apsnet.org/education/advancedplantpath/topics/RModules/doc1/04_Linear_regression.html
## Disease severity as a function of temperature
# Response variable, disease severity
diseasesev<-c(1.9,3.1,3.3,4.8,5.3,6.1,6.4,7.6,9.8,12.4)
# Predictor variable, (Centigrade)
temperature<-c(2,1,5,5,20,20,23,10,30,25)
## For convenience, the data may be formatted into a dataframe
severity <- as.data.frame(cbind(diseasesev,temperature))
## Fit a linear model for the data and summarize the output from function lm()
severity.lm <- lm(diseasesev~temperature,data=severity)
# Take a look at the data
plot(
diseasesev~temperature,
data=severity,
xlab="Temperature",
ylab="% Disease Severity",
pch=16,
pty="s",
xlim=c(0,30),
ylim=c(0,30)
)
title(main="Graph of % …1
推荐指数
推荐指数
1
解决办法
解决办法
2110
查看次数
查看次数