小编ger*_*erm的帖子
是否可以从Python中的HDF5文件中的复合数据集中读取字段名称?
我有一个HDF5文件,其中包含一个带有列名的2D表.当我在这个对象上掠夺时,它会在HDFView中显示出来results.
事实证明,这results是一个"复合数据集",一个一维数组,其中每个元素都是一行.以下是HDFView显示的属性:
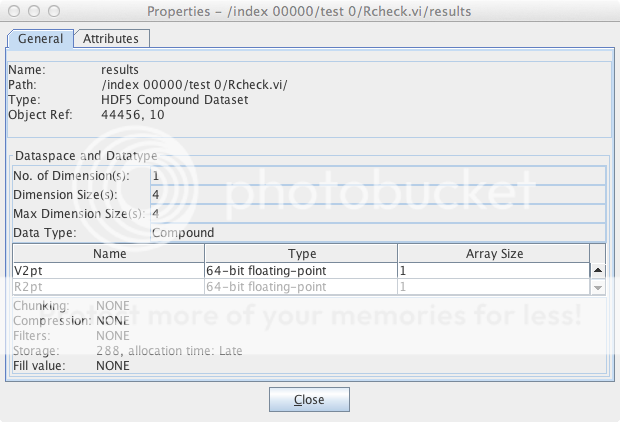
我可以得到这个对象的句柄,让我们称之为res.
列名V2pt,R2pt等等.
我可以将整个数组作为数据读取,我可以读取一个元素
res[0,...,"V2pt"].
这将返回列第一行中的数字V2pt.替换0为1将返回第二行值等.
如果我先知道colunm名称,那就行得通.但我没有.
我只是想获得整个数据集和它的列名.我怎样才能做到这一点?
我看到HDF5文档中的HDF5文档中有一个get_field_info函数,但我发现在h5py中没有这样的函数.
我搞砸了吗?
更好的是将此表作为pandas DataFrame读取的解决方案......
推荐指数
解决办法
查看次数
在 pandas 中按浮点列中的值选择行
我将 csv 数据文件导入到df带有.pandas DataFrame 的 pandas DataFrame 中pd.read_csv。该文本文件包含一列,其中包含如下字符串:
y
0.001
0.0003
0.0001
3e-05
1e-05
1e-06
如果我打印 DataFrame,pandas 会输出这些值的十进制表示形式,逗号后有 6 位数字,一切看起来都很好。
当我尝试按值选择行时,如下所示:
df[df['y'] == value],
通过输入值的相应十进制表示形式,pandas 可以正确匹配某些值(例如:第 0、2、4 行),但不会匹配其他值(第 1、3、5 行)。这当然是因为这些行值在基数 2 中没有完美的表示。
我能够通过以下方式解决这个问题:
df[abs(df['y']/value-1) <= 0.0001]
但似乎有些尴尬。我想知道的是: numpy 已经有一个方法.isclose,专门用于此目的。
.isclose像这样的情况有没有办法使用呢?或者 pandas 中有更直接的解决方案?
推荐指数
解决办法
查看次数
带有对数刻度的更好的刻度和刻度标签
我正在尝试获得更好看的双对数图,除了一个小问题之外,我几乎得到了我想要的。
我的示例偏离标准设置的原因是 x 值限制在不到十年的范围内,并且我想使用十进制,而不是科学记数法。
请允许我用一个例子来说明:
import matplotlib.pyplot as plt
%matplotlib inline
import matplotlib as mpl
import numpy as np
x = np.array([0.6,0.83,1.1,1.8,2])
y = np.array([1e-5,1e-4,1e-3,1e-2,0.1])
fig1,ax = plt.subplots()
ax.plot(x,y)
ax.set_xscale('log')
ax.set_yscale('log')
其产生:

x 轴有两个问题:
使用科学计数法,在这种情况下会适得其反
右下角可怕的“偏移”
经过大量阅读后,我添加了三行代码:
ax.xaxis.set_major_formatter(mpl.ticker.ScalarFormatter())
ax.xaxis.set_minor_formatter(mpl.ticker.ScalarFormatter())
ax.ticklabel_format(style='plain',axis='x',useOffset=False)
这会产生:

我对此的理解是,有 5 个小刻度和 1 个大刻度。它好多了,但仍然不完美:
- 我想要 1 到 2 之间的一些额外刻度
- 1 处的标签格式错误。应该是“1.0”
所以我在格式化语句之前插入了以下行:
ax.xaxis.set_major_locator(mpl.ticker.MultipleLocator(0.2))
我终于得到了我想要的刻度:

我现在有 8 个主要刻度和 2 个次要刻度。现在,这看起来几乎是正确的,除了 0.6、0.8 和 2.0 处的刻度标签比其他刻度标签显得更粗这一事实之外。这是什么原因?我该如何纠正?
推荐指数
解决办法
查看次数
根据索引值的条件选择 Pandas DataFrame 中的行
假设我有以下多索引 DataFrame:
import pandas as pd
df = pd.DataFrame({'Index0':[0,1,2,3,4,5],'Index1':[100,200,300,400,500,600],'A':[5,2,5,8,1,2]})

现在我想选择 Index1 小于 400 的所有行。如果 Index1 是常规列,每个人都知道它是如何工作的:
df[df['Index1'] < 400]
因此,一种方法是reset_index执行选择,然后再次设置索引。这似乎很多余。
我的问题是:有没有办法直接做到这一点?当 DataFrame 有一个行多索引时如何做到这一点?
推荐指数
解决办法
查看次数
如何计算pandas multiindex DataFrame中的分位数?
我有一个pandas multiindex DataFrame,我想计算其在特定索引级别上的值的分位数.最好用一个例子来解释.
首先,让我们创建DataFrame:
import itertools
import pandas as pd
import numpy as np
item = ('A', 'B')
item_type = (0, 1, 2)
location = range(5)
idx = pd.MultiIndex.from_tuples(list(itertools.product(item, item_type, location)),names=('Item', 'Type', 'Location'))
df = pd.DataFrame(np.random.randn(len(idx), 3), index=idx,columns=('C1', 'C2', 'C3'))
df
假设我们想要计算所有位置上每个项目和类型的列值中值的表格.这很容易使用内置的.median方法:
median_df = df.median(level=[0,1])
median_df
这将生成一个带有multiindex =(Item,Type)的三列DataFrame.它适用于大多数常见功能,如.mean,.max,.min等.
但它对.quantile不起作用 - 奇怪的是,分位数没有'level'参数.
如何以与中位数等相同的方式计算给定的分位数?
推荐指数
解决办法
查看次数
如何在pandas中查找多索引groupby对象中的组数?
我的问题很简单,但在我看的任何地方都找不到答案.
我希望在多索引pandas groupby对象中拥有组的数量.请注意,这与组(使用.size())中的元素数量不同,也不是组的总数(使用len.请参见此处).
最好用一个例子来说明.
让我们创建一个简单的数据帧:
import pandas as pd
df = pd.DataFrame({'Group': ['gr1','gr1','gr2','gr2','gr3','gr3'],
'Kind': ['sweet','sour','sweet','sour','sweet','sour'],
'Values': [10,11,200,201,300,301]})
现在我们使用两列进行分组:
gr = df.groupby(['Group','Kind'])
这将生成所需的groupby对象.它总共有六个组,您可以通过以下方式进行验证:
len(gr)
我现在可以遍历这些组:
for key,group in gr:
print key
这产生以下结果:
('gr1', 'sour')
('gr1', 'sweet')
('gr2', 'sour')
('gr2', 'sweet')
('gr3', 'sour')
('gr3', 'sweet')
我们可以看到第一个键有3个唯一条目,第二个键有2个唯一条目.
我正在寻找的东西是gr返回(3,2)而无法访问生成的原始数据集,gr而无需遍历groupby对象,构建列表,以及查找其唯一元素.
推荐指数
解决办法
查看次数
是否可以将HTML表读入带有样式标签的大熊猫中?
我正在尝试使用pandas read_html函数阅读此处的 “众议院正式名单” 。
使用
df_list = pd.read_html('http://clerk.house.gov/member_info/olmbr.aspx',header=0,encoding = "UTF-8")
house = df_list[0]
我确实得到了一个不错的DataFrame,其中包含代表姓名,州和地区。标头正确,编码也正确。到目前为止,一切都很好。
但是,问题在于聚会。没有派对的专栏。而是用字体(罗马或斜体)表示聚会。查看HTML源代码,这是民主人士的条目:
<tr><td><em>Adams, Alma S.</em></td><td>NC</td><td>12th</td></tr>
这是共和党人的条目:
<tr><td>Anderholt, Robert B.</td><td>AL</td><td>4th</td></tr>
共和党人<em></em>在他们的名字周围缺少标签。
人们将如何检索这一信息?可以用熊猫吗?还是需要一些更复杂的HTML解析器?如果是这样,哪个?
推荐指数
解决办法
查看次数