小编dat*_*eek的帖子
按行将矩阵列表组合到单个矩阵中
假设我有一个矩阵列表(所有列都相同).如何按行('row bind' rbind)追加/组合这些矩阵以获得单个矩阵?
样品:
> matrix(1, nrow=2, ncol=3)
[,1] [,2] [,3]
[1,] 1 1 1
[2,] 1 1 1
> matrix(2, nrow=3, ncol=3)
[,1] [,2] [,3]
[1,] 2 2 2
[2,] 2 2 2
[3,] 2 2 2
> m1 <- matrix(1, nrow=2, ncol=3)
> m2 <- matrix(2, nrow=3, ncol=3)
现在我们可以在列表中包含许多矩阵,假设我们只有两个:
l <- list(m1, m2)
我希望实现以下目标:
> rbind(m1, m2)
[,1] [,2] [,3]
[1,] 1 1 1
[2,] 1 1 1
[3,] 2 2 2
[4,] 2 2 2
[5,] …28
推荐指数
推荐指数
2
解决办法
解决办法
2万
查看次数
查看次数
在Cassandra中设计时间序列数据库
我正在寻找创建一个Cassandra时间序列数据库,用于存储数百万个可能总共高达100B数据点的日常数据系列.
我查看了这篇文章:http: //rubyscale.com/blog/2011/03/06/basic-time-series-with-cassandra/
这种设计非常完美.所以基本上我可以将每日时间戳作为列,如果需要,可以通过将日期附加到行来对列进行分片.
我有两个问题:
- 我期待存储多达20,000个带时间戳(每日)的列.是否有必要通过例如分割行.有这么多列的年份?分割行是否有任何优势/劣势,以减少每年365列的数量.
- 我的另一个想法是,不是逐行分割,而是每年创建列族.这样,当访问多年的数据时,我将不得不查询多个列族而不是一个列族,并在客户端加入结果.这种方法会加快速度还是降低速度?
5
推荐指数
推荐指数
1
解决办法
解决办法
5155
查看次数
查看次数
Cassandra表中的多列
我想知道当表中有多个非PK列时会发生什么.我读过这个例子:http: //johnsanda.blogspot.co.uk/2012/10/why-i-am-ready-to-move-to-cql-for.html
这表明单列:
CREATE TABLE raw_metrics (
schedule_id int,
time timestamp,
value double,
PRIMARY KEY (schedule_id, time)
);
我们得到:
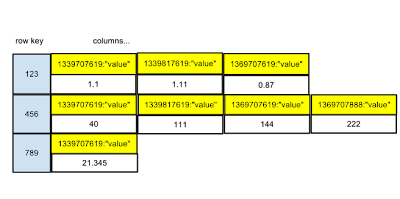
现在我想知道当我们有两列时会发生什么:
CREATE TABLE raw_metrics (
schedule_id int,
time timestamp,
value1 double,
value2 int,
PRIMARY KEY (schedule_id, time)
);
我们最终会得到这样的结果:
row key columns...
123 1339707619:"value1" | 1339707679:"value2" | 1339707784:"value2"
...
更确切地说:
row key columns...
123 1339707619:"value1":"value2" | 1339707679:"value1":"value2" | 1339707784:"value1""value2"
...
我想我要问的是,如果这只是一个稀疏表,因为我一次只插入"value1"或"value2".
在这种情况下,如果我想存储更多列(每个类型一个,例如double,int,date等),或许更好的是拥有单独的表而不是将所有内容存储在单个表中?
5
推荐指数
推荐指数
1
解决办法
解决办法
327
查看次数
查看次数