小编Eng*_*ica的帖子
在h2o随机森林中用于"重要性"的度量是多少?
这是我的代码:
set.seed(1)
#Boruta on the HouseVotes84 data from mlbench
library(mlbench) #has HouseVotes84 data
library(h2o) #has rf
#spin up h2o
myh20 <- h2o.init(nthreads = -1)
#read in data, throw some away
data(HouseVotes84)
hvo <- na.omit(HouseVotes84)
#move from R to h2o
mydata <- as.h2o(x=hvo,
destination_frame= "mydata")
#RF columns (input vs. output)
idxy <- 1
idxx <- 2:ncol(hvo)
#split data
splits <- h2o.splitFrame(mydata,
c(0.8,0.1))
train <- h2o.assign(splits[[1]], key="train")
valid <- h2o.assign(splits[[2]], key="valid")
# make random forest
my_imp.rf<- h2o.randomForest(y=idxy,x=idxx,
training_frame = train,
validation_frame = …推荐指数
解决办法
查看次数
如何在rstudio中为新的".R"文件设置默认模板
推荐指数
解决办法
查看次数
R 相当于微基准测试,包括内存和运行时
背景:
这是 R 的“微基准测试”包:https :
//cran.r-project.org/web/packages/microbenchmark/index.html
参考手册中的第一行说它是为“精确计时功能”而构建的。
与此有关的一个问题是固有的计算机时间与计算机内存的权衡。一些解决方案是内存密集型的,但 CPU 速度很快。有些是 CPU 密集型的,但内存占用非常小。
问题:
我如何以良好的分辨率同时对基准/微基准进行基准测试/微基准测试,不仅是执行时间,还包括在 R 中执行期间的内存使用?
推荐指数
解决办法
查看次数
如何快速将数据导入h2o
我的问题不是:
硬件/空间:
- 32个Xeon线程w/~256 GB Ram
- ~65 GB的数据上传.(约56亿个细胞)
问题:
将数据上传到h2o需要数小时.这不是任何特殊处理,只有"as.h2o(...)".
使用"fread"将文本放入空间需要不到一分钟,然后我进行一些行/列转换(差异,滞后)并尝试导入.
在尝试任何类型的"as.h2o"之前,总R内存是~56GB,所以分配的128不应该太疯狂,不是吗?
问题:
如果需要不到一个小时加载到h2o,我该怎么办?它应该需要一分钟到几分钟,不再需要.
我尝试过的:
- 'h2o.init'中撞击高达128 GB的ram
- 使用slam,data.table和options(...
- 在"as.h2o"之前转换为"as.data.frame"
- 写入csv文件(r write.csv chokes并永远占用.虽然我写了很多GB,所以我理解).
- 写入sqlite3,表的列数太多,这很奇怪.
- 检查驱动器缓存/交换以确保有足够的GB.也许java正在使用缓存.(还在工作)
更新:
所以看起来我唯一的选择是创建一个巨大的文本文件,然后使用"h2o.importFile(...)".我写了15GB.
Update2:
这是一个可怕的csv文件,大约22GB(~2.4Mrows,~2300 cols).对于它的价值,从下午12:53到下午2:44花了很多时间来编写csv文件.在编写之后,导入它的速度要快得多.
推荐指数
解决办法
查看次数
滚动将数据表中的多个分位数应用于多列
背景:
我可以使用 data.table(见附件)从我的数据中获取多个时刻,但这需要很长时间。我在想,对表格进行排序以获得特定百分位数的过程会更有效地找到几个。
像中值这样的一次性统计需要 1.79 毫秒,而非中值分位数需要 68 倍的时间,为 122.8 毫秒。必须有一种方法来减少计算时间。
问题:
- 有没有办法以更有效的方式从同一数据中调用多个分位数?
- 我可以从 data.table 中提取“lapply”并像我做名字列表一样编写它吗?
我的带有微小合成数据的示例代码:
#libraries
library(data.table) #data.table
library(zoo) #roll apply
#reproducibility
set.seed(45L)
#make data
DT<-data.table(V1=c(1L,2L),
V2=LETTERS[1:3],
V3=round(rnorm(300),4),
V4=round(runif(150),4),
V5=1:1200)
DT
#get names
my_col_list <- names(DT)[c(3,4)]
#make new variable names
my_name_list1 <- paste0(my_col_list, "_", "33rd_pctile")
my_name_list2 <- paste0(my_col_list, "_", "77rd_pctile")
#compute values
for(i in 1:length(my_col_list)){
#first
DT[, (my_name_list1[i]) := unlist(lapply(.SD,
function(x) rollapply(x,
7,
quantile,
fill = NA,
probs = 1/3)),
recursive = F),
.SDcols = my_col_list[i]]
#second
DT[, (my_name_list2[i]) …推荐指数
解决办法
查看次数
如何使用JMP变异图制作嵌套x标签,但使用ggplot2
我喜欢JMP可变性图。(链接)这是一个强大的工具。
该示例的示例具有2个x轴标签,一个用于部件号,一个用于操作员。

在这里,JMP变异图显示了两个以上级别的变量。以下按油量,批量和爆米花类型划分。找到正确的序列以显示最强的分离可能需要花费一些工作,但这是信息交流的绝佳工具。

使用ggplot2库,如何用R使用多层x标签?
我能找到的最好的是这个(link,link),它根据圆柱数分开,但是不做x轴标签。
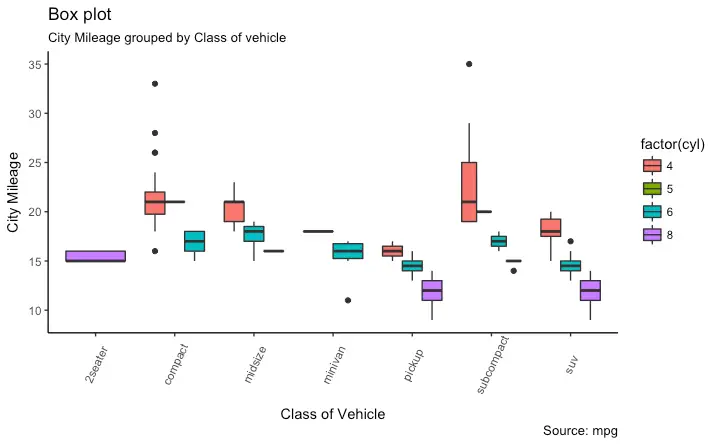{kind=link}
我的示例代码是这样的:
#reproducible
set.seed(2372064)
#data (I'm used to reading my own, not using built-in)
data(mtcars)
attach(mtcars)
#impose factors as factors
fact_idx <- c(2,8:11)
for(i in fact_idx){
mtcars[,i] <- as.factor(mtcars[,i])
}
#boxplot
p <- ggplot(mtcars, aes(gear, mpg, fill=cyl)) +
geom_boxplot(notch = TRUE)
p
这给出的图是:

如何使x轴标签同时显示齿轮和气缸?
在jmp中我得到这个:

推荐指数
解决办法
查看次数
如何将随机种子分配给 dplyr sample_n 函数?
这是来自 R 中 dplyr 的“sample_n”。
https://dplyr.tidyverse.org/reference/sample.html
为了可重复性,我应该放置一个种子,以便其他人可以获得我的确切结果。
是否有内置的方法来设置“sample_n”的种子?这是我在环境中做的事情并且“sample_n”响应它吗?
这些不是内置在“sample_n”函数中的。
.
推荐指数
解决办法
查看次数
使用data.table创建滞后列
背景:
假设我有这个代码
library(data.table)
#reproducibility
set.seed(45L)
#make table
dt <- data.table(V1=c(1L,2L),
V2=LETTERS[1:3],
V3=round(rnorm(4),4),
V4 = 1:12)
dt
我得到了
> dt
V1 V2 V3 V4
1: 1 A 0.3408 1
2: 2 B -0.7033 2
3: 1 C -0.3795 3
4: 2 A -0.7460 4
5: 1 B 0.3408 5
6: 2 C -0.7033 6
7: 1 A -0.3795 7
8: 2 B -0.7460 8
9: 1 C 0.3408 9
10: 2 A -0.7033 10
11: 1 B -0.3795 11
12: 2 …推荐指数
解决办法
查看次数
使用Conv1d在Python / Keras中自动过滤时间序列
它可能看起来像很多代码,但是大多数代码都是注释或格式,以使其更具可读性。
给定:
如果我定义感兴趣的变量“序列”,则如下:
# define input sequence
np.random.seed(988)
#make numbers 1 to 100
sequence = np.arange(0,10, dtype=np.float16)
#shuffle the numbers
sequence = sequence[np.random.permutation(len(sequence))]
#augment the sequence with itself
sequence = np.tile(sequence,[15]).flatten().transpose()
#scale for Relu
sequence = (sequence - sequence.min()) / (sequence.max()-sequence.min())
sequence
# reshape input into [samples, timesteps, features]
n_in = len(sequence)
sequence = sequence.reshape((1, n_in, 1))
问题:
如何在Keras的自动编码器中使用conv1d以合理的准确度估算此序列?
如果conv1d不适合此问题,您能告诉我编码器/解码器更合适的层类型是什么吗?
更多信息:
有关数据的要点:
- 它是10个不同值的重复序列
- 一个10步的滞后可以完美预测序列
- 包含10个元素的字典应给出“预测给出的下一个”
我曾尝试对编码器和解码器部分(LSTM,密集,多层密集)的其他层进行预测,并且它们不断在0.0833的mse处碰到“墙”……这是0到1之间均匀分布的方差对我来说,一个好的自动编码器在解决这个简单问题上应该至少能够获得99.9%的准确度,因此“ mse”的准确度大大低于1%。
我无法转换conv1d,因为我弄乱了输入。关于如何使其工作似乎没有真正的好例子,而且我对这种总体架构还很陌生,对我来说并不明显。
链接:
推荐指数
解决办法
查看次数
'R','鼠标',缺少变量插补-如何仅在稀疏矩阵中执行一列
我有一个半稀疏的矩阵。所有单元格中有一半是空白(na),所以当我尝试运行“鼠标”时,它将尝试对所有单元格起作用。我只对一个子集感兴趣。
问题:在下面的代码中,如何使“小鼠”仅在前两列上运行?有没有一种干净的方法使用行滞后或行前导来做到这一点,以便上一行的内容可以帮助修补当前行中的孔?
set.seed(1)
#domain
x <- seq(from=0,to=10,length.out=1000)
#ranges
y <- sin(x) +sin(x/2) + rnorm(n = length(x))
y2 <- sin(x) +sin(x/2) + rnorm(n = length(x))
#kill 50% of cells
idx_na1 <- sample(x=1:length(x),size = length(x)/2)
y[idx_na1] <- NA
#kill more cells
idx_na2 <- sample(x=1:length(x),size = length(x)/2)
y2[idx_na2] <- NA
#assemble base data
my_data <- data.frame(x,y,y2)
#make the rest of the data
for (i in 3:50){
my_data[,i] <- rnorm(n = length(x))
idx_na2 <- sample(x=1:length(x),size = length(x)/2)
my_data[idx_na2,i] <- NA
}
#imputation
est <- …推荐指数
解决办法
查看次数
标签 统计
r ×8
data.table ×2
h2o ×2
algorithm ×1
autoencoder ×1
boxplot ×1
dplyr ×1
ggplot2 ×1
gini ×1
import ×1
imputation ×1
keras ×1
median ×1
memory ×1
performance ×1
python-3.x ×1
r-mice ×1
random-seed ×1
rstudio ×1
sas-jmp ×1
sqlite ×1
tensorflow ×1
time-series ×1
zoo ×1