小编bra*_*boy的帖子
这个游戏有解决方案吗?
我正在使用Java swing开发一个简单的游戏.我想知道这个特定游戏在以下场景中是否有解决方案.如果我确信理论上解决方案无法在这一点上达成,我会向用户发出通知.
3x3
http://img814.imageshack.us/img814/7449/screenshot20100924at206.png
{kind=link}
4x4
http://img39.imageshack.us/img39/1851/screenshot20100924at241.png
{kind=link}
这个游戏的目的是使用一个可用空间将数字填充到空白区域,从1到8(或1到15)填充数字.每次我最终得到上面显示的组合.我只想说服自己没有办法从上述方案中获得适当的解决方案.请帮忙.
推荐指数
解决办法
查看次数
链表中的循环检测:穷举理论
这不是使用着名的 Hare和Tortoise方法检测链表中的循环的问题.
在兔子和乌龟方法我们在倍和2米的速度运行,以确定它们满足指针和我深信,其最有效的方式和类型的搜索的顺序是O(n).
问题是我必须拿出一个证明(证明或反驳),有可能的是,当移动速度斧(A乘以x)和Bx(B次X)和不等于两个指针总是会遇到B.其中A和B是在链表上运行的两个随机整数,其中存在循环.
这是我最近参加的一次采访中被问到的,我无法全面向自己证明以上是否可行.任何帮助赞赏.
推荐指数
解决办法
查看次数
在rails中开发模式和生产模式有什么区别?
目前,我正在为我的应用程序使用开发模式,但我不知道是否应该使用生产模式.如果是这种情况,我如何将所有数据传输到生产模式?
是否存在在此过程中引入错误的风险?
推荐指数
解决办法
查看次数
如何在Ruby中查找String的所有循环?
我在Ruby中编写了一个方法来查找文本的所有循环组合
x = "ABCDE"
(x.length).times do
puts x
x = x[1..x.length] + x[0].chr
end
有没有更好的方法来实现这个?
推荐指数
解决办法
查看次数
关于Java多线程的一个问题
假设以下课程
public class TestObject{
public void synchronized method1(){
//some 1000 lines of code
}
public void method2(){
//some 1000 lines of code
}
}
假设有两个线程访问相同的TestObject类实例,让我们称它们为t1和t2.我想知道在以下场景中会发生什么.
- 当t1处于访问method1()的中途时.现在t2正在尝试访问method2().
- 当t1处于访问method2()的中途时.现在t2正在尝试访问method1().
我的理解是,对于第一个问题,线程t2将不被授予权限,因为对象将被t1锁定.对于第二个问题,线程t2将被授予访问权并锁定对象并将t1从执行中停止.但我的假设是错误的.有谁能解释一下?
谢谢
推荐指数
解决办法
查看次数
对象关系映射的缺点
我是ORM的粉丝 - 对象关系映射,过去一年半我一直在使用Rails.在此之前,我使用JDBC编写原始查询,并使数据库通过存储过程完成繁重的工作.使用ORM,我最初很乐意做类似的事情coach.manager,manager.coaches而且非常简单易读.
但是随着时间的推移,有许多协会在不断涌现,我最终还是在a.b.c.d幕后向所有方向发射查询.使用rails和ruby,垃圾收集器变得疯狂,并且花费了大量时间来加载一个非常复杂的页面,其中包含相对较少的数据.我必须通过一个简单的存储过程替换这个ORM样式代码,我看到的结果是巨大的.现在需要50秒才能加载的页面只需2秒钟.
有了这个巨大的差异,我应该继续使用ORM吗?很明显,与原始查询相比,它具有严重的开销.
一般来说,使用像Hibernate,ActiveRecord这样的ORM框架有哪些常见的缺陷?
推荐指数
解决办法
查看次数
从递归方法返回时需要帮助
我试图在二叉树(不是二叉搜索树)中跟踪节点的路径.给定一个节点,我试图从根打印路径的值.
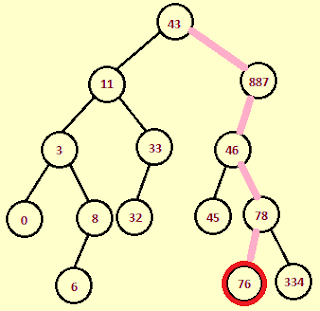
我写了以下程序.
package dsa.tree;
import java.util.Stack;
public class TracePath {
private Node n1;
public static void main(String args[]){
TracePath nodeFinder = new TracePath();
nodeFinder.find();
}
public void find(){
Tree t = getSampleTree();
tracePath(t,n1);
}
private Tree getSampleTree() {
Tree bsTree = new BinarySearchTree();
int randomData[] = {43,887,11,3,8,33,6,0,46,32,78,76,334,45};
for(int i=0;i<randomData.length;i++){
bsTree.add(randomData[i]);
}
n1 = bsTree.search(76);
return bsTree;
}
public void tracePath(Tree t, Node node){
trace(t,node);
}
Stack<Node> mainStack = new Stack<Node>();
public void trace(Tree t, Node node){
trace(t.getRoot(),node);
}
private void …推荐指数
解决办法
查看次数
SSIS - 动态列映射
我正在使用SSIS从excel到OLEDB SQL进行数据转换.我在一个文件夹中有一组工作表,我必须循环,并将每个工作表中的数据插入到表中.我有一个场景,我必须通过一组具有不同列结构的Excel工作表循环.我可以通过foreach循环枚举器循环遍历每个工作表找到文件名并将它们传递给Excel源.
我想知道是否有办法在目标组件中转义这个列映射,在我的情况下它将是一个OLEDB SQL表.因为这些映射对于每个文件都不同.有没有办法动态地这样做?
推荐指数
解决办法
查看次数
是否可以在Java中的指定时间内停止函数的执行?
我想知道如何在java中的指定时间内停止指定函数的执行.
例如:我可以调用一个名为print_data()的函数.如果执行需要更多时间,我将不得不停止该函数的执行.
可以像这样停止执行吗?
提前致谢
推荐指数
解决办法
查看次数
二叉搜索树
这是维基百科上有关BST的一些代码:
# 'node' refers to the parent-node in this case
def search_binary_tree(node, key):
if node is None:
return None # key not found
if key < node.key:
return search_binary_tree(node.leftChild, key)
elif key > node.key:
return search_binary_tree(node.rightChild, key)
else: # key is equal to node key
return node.value # found key
现在这是一个二叉树:
10
5 12
3 8 9 14
4 11
如果我正在搜索11,并且我在那里遵循算法,我从10开始,我右转到12,然后离开到9.然后我到达树的末端而没有找到11.但是我的树中存在11 ,它只是在另一边.
你能解释一下二叉树中这个算法在树上工作的限制吗?
谢谢.
推荐指数
解决办法
查看次数
标签 统计
java ×5
algorithm ×3
binary-tree ×2
activerecord ×1
graph-theory ×1
hibernate ×1
linked-list ×1
migration ×1
mode ×1
orm ×1
python ×1
ruby ×1
ssis ×1
string ×1
swing ×1
timer ×1
traversal ×1