小编Aur*_*ron的帖子
如何将我当前的更改提交到git中的另一个分支
有时我会在工作目录中进行一些更改,并且我意识到这些更改应该在与当前更改的分支中提交.这通常发生在我想尝试新事物或进行一些测试时,我忘记事先创建一个新分支,但我不想将脏代码提交给主分支.
那么,如何将未提交的更改(或存储在索引中的更改)提交到与当前更改不同的分支?
推荐指数
解决办法
查看次数
有多少参数太多了?
例程可以有参数,这不是新闻.您可以根据需要定义任意数量的参数,但是过多的参数会使您的日常工作难以理解和维护.
当然,您可以使用结构化变量作为解决方法:将所有这些变量放在单个结构中并将其传递给例程.实际上,使用结构简化参数列表是Steve McConnell在Code Complete中描述的技术之一.但正如他所说:
细心的程序员避免捆绑数据,这在逻辑上是必要的.
因此,如果您的例程有太多参数或使用结构来伪装一个大参数列表,那么您可能做错了.也就是说,你没有保持松耦合.
我的问题是,我什么时候可以考虑参数列表太大?我认为超过5个参数,太多了.你怎么看?
推荐指数
解决办法
查看次数
功能与存储过程
假设我必须实现一段必须返回表的T-SQL代码.我可以实现一个表值函数或一个返回一组行的存储过程.我该怎么用?
简而言之,我想知道的是:
哪些是函数和存储过程之间的主要区别?使用其中一个时需要考虑哪些因素?
推荐指数
解决办法
查看次数
如何在Python中记录模块?
而已.如果要记录函数或类,请在定义之后放置一个字符串.例如:
def foo():
"""This function does nothing."""
pass
但是模块怎么样?如何记录file.py的作用?
推荐指数
解决办法
查看次数
使用无符号索引进行反向'for'循环的最佳方法是什么?
我第一次尝试反向for循环 n次做的事情是这样的:
for ( unsigned int i = n-1; i >= 0; i-- ) {
...
}
这是失败的,因为无符号算术 i保证总是大于或等于零,因此循环条件将始终为真.幸运的是,在我不得不想知道为什么循环无限执行之前,gcc编译器警告我"无意义的比较".
我正在寻找一种解决这个问题的优雅方法,请记住:
- 它应该是一个倒退的循环.
- 循环索引应该是无符号的.
- n是无符号常数.
- 它不应该基于无符号整数的"模糊"环算术.
有任何想法吗?谢谢 :)
推荐指数
解决办法
查看次数
有官方的C文档吗?
我正在寻找C中所有语法和内置函数的文档,但我找不到任何在线网站,这似乎是标准C知识的终极官方来源.
除了Kernighan和Ritchie的着名书籍外,是否有任何在线C规范?也许有,我不知道如何找到它.或许问题是我不知道我在找什么.
推荐指数
解决办法
查看次数
如何异步处理?
假设我有一个实现IDisposable接口的类.像这样的东西:
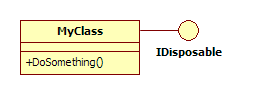
MyClass使用一些非托管资源,因此IDisposable的Dispose()方法会释放这些资源.MyClass应该像这样使用:
using ( MyClass myClass = new MyClass() ) {
myClass.DoSomething();
}
现在,我想实现一个异步调用DoSomething()的方法.我向MyClass添加了一个新方法:
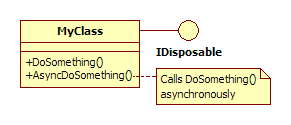
现在,从客户端来看,MyClass应该像这样使用:
using ( MyClass myClass = new MyClass() ) {
myClass.AsyncDoSomething();
}
但是,如果我不做任何其他事情,这可能会失败,因为在调用DoSomething()之前可能会释放对象myClass(并抛出意外的ObjectDisposedException).因此,应该延迟对Dispose()方法(隐式或显式)的调用,直到完成对DoSomething()的异步调用.
我认为Dispose()方法中的代码应该以异步方式执行,并且只有在解析了所有异步调用之后才能执行.我想知道哪个可能是实现这一目标的最佳方法.
谢谢.
注意:为简单起见,我没有详细介绍如何实现Dispose()方法.在现实生活中,我通常遵循Dispose模式.
更新:非常感谢您的回复.我感谢您的努力.正如chakrit 评论的那样,我需要多次调用异步DoSomething.理想情况下,这样的事情应该工作正常:
using ( MyClass myClass = new MyClass() ) …推荐指数
解决办法
查看次数
并发写入相同的全局内存位置
我有几个块,每个块都有一个大小为512的共享内存数组中的整数.如何检查每个块中的数组是否包含零作为元素?
我正在做的是创建一个驻留在全局内存中的数组.此数组的大小取决于块的数量,并初始化为0.因此,a[blockid] = 1如果共享内存数组包含零,则每个块都会写入.
我的问题是当我在一个块中同时写几个线程时.也就是说,如果共享内存中的数组包含多个零,则会写入多个线程a[blockid] = 1.这会产生任何问题吗?
换句话说,如果2个线程将完全相同的值写入全局内存中完全相同的数组元素,那会不会有问题?
推荐指数
解决办法
查看次数
将数组和矩阵传递给函数作为指针和指向C中的指针
给出以下代码:
void
foo( int* array )
{
// ...
}
void
bar( int** matrix )
{
// ...
}
int
main( void ) {
int array[ 10 ];
int matrix[ 10 ][ 10 ];
foo( array );
bar( matrix );
return 0;
}
我不明白为什么我会收到这个警告:
警告:从不兼容的指针类型传递'bar'的参数1
虽然'foo'电话似乎没问题.
谢谢 :)
推荐指数
解决办法
查看次数
自己开发
在我的公司里,每个开发人员都有自己的工作项目,因此几乎没有任何团队合作.一年以来,我一直在构建这样的软件,没有良好的开发方法学科.结果还可以,但我想改变并开始为我的下一个项目使用更严肃的开发方法.
您认为自己开发软件的最佳实践是什么?我可以使用哪些方法来避免软件开发中常见的陷阱?什么模型的软件开发(瀑布 - 我是开玩笑,极端,敏捷等)最适合我?
如果你向我指出一些我可以学习如何成为更好的开发人员的资源或教程,我会非常高兴:)
谢谢.
推荐指数
解决办法
查看次数
标签 统计
c ×4
parameters ×2
asynchronous ×1
branch ×1
c# ×1
c++ ×1
commit ×1
cuda ×1
database ×1
dispose ×1
for-loop ×1
function ×1
git ×1
methodology ×1
pointers ×1
python ×1
sql ×1
sql-server ×1