小编Ξέν*_*νος的帖子
理论上阿克曼函数可以优化吗?
我想知道是否可以有一个阿克曼函数的版本,其时间复杂度比标准变体更好。
\n这不是作业,我只是好奇。我知道阿克曼函数除了作为性能基准之外没有任何实际用途,因为它具有深度递归。我知道数字增长得非常快,而且我对计算它不感兴趣。
\n尽管我使用Python 3并且整数不会溢出,但我的时间确实有限,但我根据维基百科上的定义自己实现了它的一个版本,并计算了极小的值的输出,只是为了使确保输出正确。
\n
def A(m, n):\n if not m:\n return n + 1\n return A(m - 1, A(m, n - 1)) if n else A(m - 1, 1)\n上面的代码是直接翻译图片,速度极慢,不知道如何优化,难道就不能优化了吗?
\n我能想到的一件事是记住它,但是递归是向后运行的,每次递归调用函数时,参数都是以前没有遇到过的,每次连续的函数调用参数都会减少而不是增加,因此函数的每个返回值都需要要计算,当您第一次使用不同的参数调用函数时,记忆并没有帮助。
\n仅当您再次使用相同的参数调用它时,记忆化才有帮助,它不会计算结果,而是检索缓存的结果,但如果您使用 (m, n) >= (4, 2 )无论如何它都会使解释器崩溃。
\n我还根据这个答案实现了另一个版本:
\ndef ack(x, y):\n for i in range(x, 0, -1):\n y = ack(i, y - 1) if y else 1\n return y + 1\n但实际上它更慢:
\nIn [2]: …推荐指数
解决办法
查看次数
Python 3请求如何强制为每个请求使用新连接?
我使用请求和线程编写了一个可暂停的多线程下载器,但是下载在恢复后无法完成,长话短说,由于特殊的网络条件,连接通常会在需要刷新连接的下载过程中终止。
您可以在我之前的问题中查看代码:
我观察到下载恢复后可以超过 100% 并且不会停止(至少我没有看到它们停止),mmap 索引将超出范围并出现大量错误消息......
我终于发现这是因为先前请求的幽灵,导致服务器错误地从上次连接发送了未下载的额外数据。
这是我的解决方案:
- 创建一个新连接
s = requests.session()
r = s.get(
url, headers={'connection': 'close', 'range': 'bytes={0}-{1}'.format(start, end)}, stream=True)
- 中断连接
r.close()
s.close()
del r
del s
在我的测试中,我发现requests有两个名为session的属性,一个是Titlecase,一个是小写,小写的是一个函数,另一个是一个类构造函数,它们都创建了一个requests.sessions.Session对象,有没有他们之间的区别?
如何将 keep-alive 设置为 False?
这里找到的方法不再有效:
In [39]: s = requests.session()
...: s.config['keep_alive'] = False
---------------------------------------------------------------------------
AttributeError Traceback (most recent call last)
<ipython-input-39-497f569a91ba> in <module>
1 s = requests.session()
----> 2 s.config['keep_alive'] = False
AttributeError: 'Session' object has no attribute 'config'
这里的方法不会抛出错误:
s = requests.session()
s.keep_alive = False …推荐指数
解决办法
查看次数
在保持列表排序的同时将唯一整数附加到列表的最快方法是什么?
我需要将值一一附加到现有列表中,同时始终保持以下两个条件:
\n- \n
列表中的每个值都是唯一的
\n \n列表始终按升序排序
\n \n
这些值都是整数,而且数量巨大(字面意思是数百万,毫不夸张),并且列表是动态构建的,根据变化的条件添加或删除值,我真的需要一种非常有效的方法来做到这一点这。
\nsorted(set(lst))不符合解决方案的资格,因为首先列表不是预先存在的,之后我需要对其进行变异,解决方案本身效率不高,为了维持上述两个条件,我需要在之后重复低效的方法每个突变,这是不切实际的,并且需要花费难以想象的时间来处理数百万个数字。
一种方法是维护一个与列表具有相同元素的集合,并使用该集合进行成员资格检查,并且仅在集合中没有元素时才将元素添加到列表中,然后将相同的元素添加到两个位置同一时间。这保持了独特性。
\n为了保持顺序,请使用二分搜索来计算所需的插入索引并在索引处插入元素。
\n我想出的示例实现:
\nfrom bisect import bisect\n\nclass Sorting_List:\n def __init__(self):\n self.data = []\n self.unique = set()\n\n def add(self, n):\n if n in self.unique:\n return\n\n self.unique.add(n)\n if not self.data:\n self.data.append(n)\n return\n if n > self.data[-1]:\n self.data.append(n)\n elif n < self.data[0]:\n self.data.insert(0, n)\n elif len(self.data) == 2:\n self.data.insert(1, n)\n else:\n self.data.insert(bisect(self.data, n), n)\n我对这个解决方案不满意,因为我必须维护一个集合,这不是内存效率最高的解决方案,而且我认为这不是最节省时间的解决方案。
\n我做了一些测试:
\nfrom timeit import timeit\n\ndef test(n):\n setup …推荐指数
解决办法
查看次数
如何在 C++ 中高效应用多项式而无需循环?
我想获得一些复杂函数的准确近似值(pow, exp, log,log2比 C++ 标准库中 cmath 提供的函数更快地
为此,我想利用浮点编码方式并使用位操作获取指数和尾数,然后进行多项式近似。尾数在 1 和 2 之间,因此我使用 n 阶多项式来近似 [1, 2] 中域 x 中的目标函数,并对浮点表达式进行位操作和简单数学运算以使计算有效。
我用来np.polyfit生成多项式。作为示例,以下是我用来在 1 <= x <= 2 上近似 log2 的 7 阶多项式:
P = np.array(
[
0.01459855,
-0.17811046,
0.95074541,
-2.91450247,
5.67353733,
-7.39616658,
7.08511059,
-3.23521156,
],
dtype=float,
)
要应用多项式,请将第一项乘以 x 的 7 次方,第二项乘以 x 的 6 次方,依此类推...
在代码中:
P[0] * x**7 + P[1] * x**6 + P[2] * x**5 + P[3] * x**4 + P[4] …推荐指数
解决办法
查看次数
Python如何高效处理复杂的嵌套字典
我有一个复杂的嵌套字典,结构如下:
example = {
('rem', 125): {
('emo', 35): {
('mon', 133): {
('ony', 33): 0
},
('mor', 62): {
('ore', 23): 0
},
('mot', 35): {
('ote', 22): 0
},
('mos', 29): {
('ose', 29): 0
}
},
('emi', 32): {
('min', 109): {
('ine', 69): 0
},
('mit', 58): {
('ite', 64): 0,
('ity', 45): 0
}
},
('eme', 26): {
('mer', 68): {
('ere', 24): 0,
('ery', 20): 0
}
}
},
('iro', 30): {
('ron', 27): …推荐指数
解决办法
查看次数
如何从图像中提取多个旋转形状?
我参加了一个在线视觉智商测试,其中有很多问题如下:
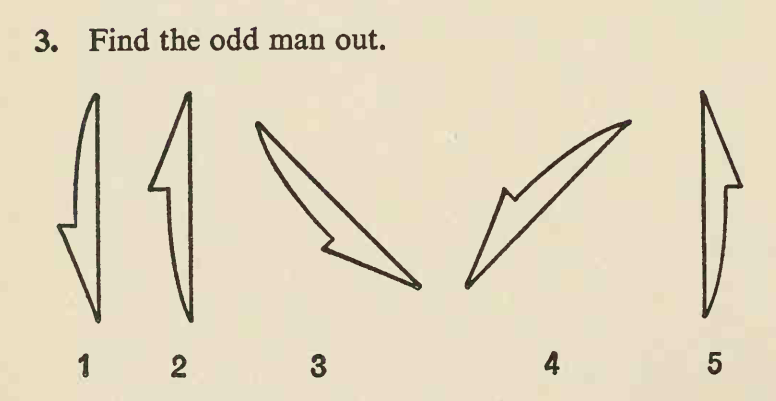
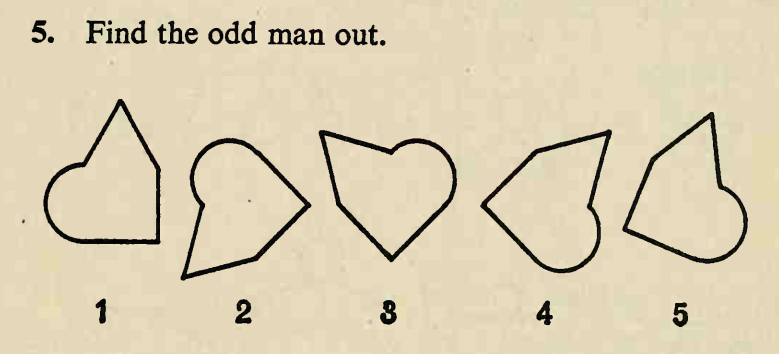
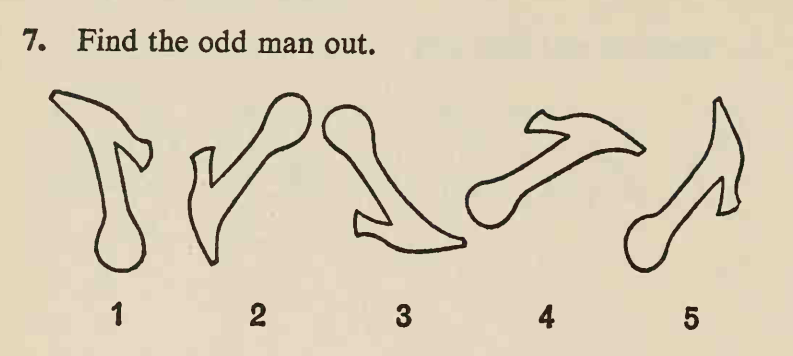
图片地址为:
[f"https://www.idrlabs.com/static/i/eysenck-iq/en/{i}.png" for i in range(1, 51)]
在这些图像中,有几个形状几乎相同且大小几乎相同。这些形状大多数都可以通过旋转和平移从其他形状中获得,但只有一种形状只能通过反射从其他形状中获得,这种形状具有与其他形状不同的手性,这就是“奇怪的人” 。任务就是找到它。
这里的答案分别是 2、1 和 4。我想将其自动化。
而我差一点就成功了。
首先,我下载图像,并使用cv2.
然后我对图像进行阈值处理并反转值,然后找到轮廓。然后我找到最大的轮廓。
现在我需要提取与轮廓相关的形状并使形状直立。这就是我陷入困境的地方,我几乎成功了,但也有一些边缘情况。
我的想法很简单,找到轮廓的最小面积边界框,然后旋转图像使矩形直立(所有边平行于网格线,最长边垂直),然后计算矩形的新坐标,最后使用数组切片来提取形状。
我已经实现了我所描述的目标:
import cv2
import requests
import numpy as np
img = cv2.imdecode(
np.asarray(
bytearray(
requests.get(
"https://www.idrlabs.com/static/i/eysenck-iq/en/5.png"
).content,
),
dtype=np.uint8,
),
-1,
)
def get_contours(image):
gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
_, thresh = cv2.threshold(gray, 128, 255, 0)
thresh = ~thresh
contours, _ = cv2.findContours(thresh, cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE)
return contours
def find_largest_areas(contours):
areas = [cv2.contourArea(contour) for contour in contours]
area_ranks = [(area, i) …推荐指数
解决办法
查看次数
C++ OpenMP 无法加速矩阵乘法
我用 C++ 编写了一个简单的矩阵乘法程序,并且它有效。我只是 C++ 的初学者,但我已经成功地让它工作了。
\n让我困惑的是它比 NumPy 慢得多。我已经对它进行了基准测试。
\n因此,我尝试使用 OpenMP 来加速,但我观察到性能完全没有变化:
\n#include <algorithm>\n#include <chrono>\n#include <iostream>\n#include <omp.h>\n#include <string>\n#include <vector>\n\n\nusing std::vector;\nusing std::chrono::high_resolution_clock;\nusing std::chrono::duration;\nusing std::chrono::duration_cast;\nusing std::chrono::microseconds;\nusing std::cout;\nusing line = vector<double>;\nusing matrix = vector<line>;\n\n\nvoid fill(line &l) {\n std::generate(l.begin(), l.end(), []() { return ((double)rand() / (RAND_MAX)); });\n}\n\nmatrix random_matrx(int64_t height, int64_t width) {\n matrix mat(height, line(width));\n std::for_each(mat.begin(), mat.end(), fill);\n return mat;\n}\n\nmatrix dot_product(const matrix &mat0, const matrix &mat1) {\n size_t h0, w0, h1, w1;\n h0 = mat0.size();\n w0 = mat0[0].size();\n h1 = mat1.size();\n w1 …推荐指数
解决办法
查看次数
如何在 C++ 中有效地计算 2 的分数次方?
我想有效地提高两个的有理数幂。这将是我所有其他数学函数实现的基础(log, log2, exp, sin, cos),因为我使用牛顿方法并且迭代方案的负载涉及求幂。
我想比 cmath 更快地实现方法。因为我们使用二进制计算机,所以很多与数字 2 相关的东西都可以被黑客入侵。
单精度浮点格式使用 32 位来表示分数,第一位是符号位,接下来的 8 位是偏差为 127 的指数,接下来的 24 位对分数进行编码。对于双精度,指数被编码为 11 位,偏差为 1023,尾数为 52 位。
我的想法很简单,我使用乘法的幂法则,在本例中为 2 a * 2 b = 2 a + b。对于小数指数 e,其小数部分 d 为 e % 1,则其整数部分为 i = e - d。由于浮点的编码方式,我们可以通过组合指数和尾数两部分来组装最终的浮点表示。i 及其偏差直接进入指数部分。
尾数部分有点棘手,但也有技巧。尾数被编码为二进制小数,其隐式整数部分为 1,我们只需将 1 加到 d 即可从浮点位获取二进制小数。请注意,如果 d 为负数,则应将其加到 2 而不是 1。
接下来的步骤很简单,第一位对应于 2 0.5 ,第二位对应于 2 0.25,第三位对应于 2 0.125等等。重要的是它们是常量,因此可以存储在查找表中。因此,对于分数幂,找到尾数的设置位,并将初始化为 1 的数字与查找表中的相应值相乘。
这给出了最终值的尾数。减一并将差值乘以 1 << 23(对于 float)和 1 << …
推荐指数
解决办法
查看次数
如何让数组中的所有值都落入一个范围内?
假设我有一个 NumPy 数组float,有正值和负值。我有两个数字,假设它们是a和b,a <= b并且[a, b]是一个(封闭的)数字范围。
我想让所有数组都落入 range [a, b],更具体地说,我想用相应的终端值替换范围之外的所有值。
我并不是试图缩放值以使数字适合一个范围,在 Python 中,这将是:
\nmina = min(arr)\nscale = (b - a) / (max(arr) - mina)\n[a + (e - mina) * scale for e in arr]\n或者在 NumPy 中:
\nmina = arr.min()\nscale = (b - a) / (arr.max() - mina)\na + (arr - mina) * scale \n我试图替换所有低于awith的值a和所有高于bwith 的值 …
推荐指数
解决办法
查看次数
如何检查变量是否是 Python 3 中 mpfr 的实例?
我想知道如何检查变量是否为 mpfr 类型,这可能听起来微不足道,但简单的方法isinstance(v, mpfr)无法解决问题。
示例:创建一个 mpfr 实例的变量,如何验证该变量是 mpfr 的实例?
import gmpy2
from gmpy2 import mpfr
f = mpfr('0.5')
最直观的方法失败了:
>>> isinstance(TAU, mpfr)
TypeError: isinstance() arg 2 must be a type or tuple of types
因为mpfr是一个函数:
>>> mpfr
<function gmpy2.mpfr>
gmpy2只有一个名为 的属性mpfr,它就是上面的函数。
然而,函数输出的类mpfr也称为mpfr:
>>> f.__class__
mpfr
但这mpfr不是mpfr主命名空间中的函数:
>>> type(f) == mpfr
False
到目前为止,我只能mpfr通过创建一个空mpfr实例并使用其__class__属性来检查变量是否是 的实例:
isinstance(f, mpfr().__class__)
怎样才能<class 'mpfr'>直接访问呢?
推荐指数
解决办法
查看次数
解构长度为 1 的“dict”,将其键和值分配给 Python 中的两个变量
我有一堆dict只有一个键值对的离子,有时是由我编写的一个脚本生成的,我需要摆脱它们。
为此,我需要获取dict. 说明我的意图的最小可重复示例:
d = {'a': 0}
assert len(d) == 1
k, v = list(d.items())[0]
不知道这是否重复,但我无法使用谷歌找到答案。
有没有更简单的方法来k, v获取d?
编辑
如果有人想知道,情况是这样的:
from pathlib import Path
def recur_dir(path, root=''):
first = False
if not root:
assert Path(path).is_dir()
root = path
first = True
report = {'folders': dict(), 'files': []}
for element in Path(path).iterdir():
if element.is_file():
report['files'].append(element.name)
elif element.is_dir():
report['folders'].update(recur_dir(str(element).replace('\\', '/'), root))
folders = report['folders']
for name, folder in list(folders.items()):
if not folder:
folders.pop(name)
if …推荐指数
解决办法
查看次数
如何优化 NumPy 埃拉托色尼筛?
我在 NumPy 中实现了自己的埃拉托斯特尼筛法。我相信你们都知道它是为了找到一个数字以下的所有素数,所以我不会进一步解释。
\n代码:
\nimport numpy as np\n\ndef primes_sieve(n):\n primes = np.ones(n+1, dtype=bool)\n primes[:2] = False\n primes[4::2] = False\n for i in range(3, int(n**0.5)+1, 2):\n if primes[i]:\n primes[i*i::i] = False\n\n return np.where(primes)[0]\n正如你所看到的,我已经做了一些优化,首先除了 2 之外所有素数都是奇数,所以我将 2 的所有倍数设置为False且仅是暴力奇数。
其次,我只循环遍历直到平方根下限的数字,因为平方根之后的所有合数都会因平方根以下素数的倍数而被消除。
\n但这不是最佳的,因为它循环遍历低于限制的所有奇数,并且并非所有奇数都是质数。随着数字的增大,素数变得更加稀疏,因此存在大量冗余迭代。
\n因此,如果候选列表是动态更改的,以这样的方式,已经识别的合数甚至不会被迭代,因此只有质数被循环,不会有任何浪费的迭代,因此算法将是最优的。
\n我写了一个优化版本的粗略实现:
\ndef primes_sieve_opt(n):\n primes = np.ones(n+1, dtype=bool)\n primes[:2] = False\n primes[4::2] = False\n limit = int(n**0.5)+1\n i = 2\n while i < limit:\n primes[i*i::i] = False\n i += 1 + …推荐指数
解决办法
查看次数
如何在全局级别定义 unordered_map?
我试图在全局级别定义两个无序映射,我用循环定义它们,并且我不想将循环放入main().
更具体地说,我试图定义一个基于 36 的字母表,我使用阿拉伯数字表示数字 0-9,然后使用基本拉丁字母表表示数字 10-35,一个映射用于将字符串转换为整数,并且它应该支持大写和小写,另一个用于将整数转换为给定基数的字符串表示形式,并且它只能是小写。
这是我的代码,显然它不起作用:
#include <unordered_map>
using namespace std;
const unordered_map<string, int> digits;
const unordered_map<int, string> alphabet;
for (int i = 0; i < 10; i++) {
string d = char(i + 48);
digits[d] = i;
alphabet[i] = d;
}
for (int i = 10; i < 36; i++) {
string upper = char(i + 55);
string lower = char(i + 87);
digits[upper] = i;
digits[lower] = i;
alphabet[i] = lower;
}
我知道如果我将循环放入函数中main(),它应该可以工作。但我不想那样做。 …
推荐指数
解决办法
查看次数
标签 统计
python ×9
python-3.x ×8
c++ ×4
c++20 ×4
algorithm ×3
numpy ×2
performance ×2
ackermann ×1
arrays ×1
dictionary ×1
gmpy ×1
isinstance ×1
nested ×1
opencv ×1
openmp ×1
primes ×1
recursion ×1