小编Pop*_*Pop的帖子
如何在perl中获取文件的确切完整路径
我只有一个文件名,myfile.txt我不知道它保存在哪里.如何获得存储文件的确切完整路径.我试过了
$string=`ls /abc/def/*/*/*/*/myfile.txt`;
结果:完整路径是 /abc/def/ghi/jkl/mno/pqr/myfile.txt
我可以通过shell command使用上面的perl脚本运行来获取完整路径.但是,这需要很长时间才能返回路径.有没有办法通过使用perl找到文件的完整路径?
推荐指数
解决办法
查看次数
R的Kolmogorov-Smirnov检验
我尝试使用Kolmogorov-Smirnov检验来检验样本的正态性.这是我做的一个简单的例子:
x <- rnorm(1e5, 1, 2)
ks.test(x, "pnorm")
这是R给我的结果:
One-sample Kolmogorov-Smirnov test
data: x
D = 0.3427, p-value < 2.2e-16
alternative hypothesis: two-sided
p值非常低,而测试应该接受零假设.
我不明白为什么它不起作用.
推荐指数
解决办法
查看次数
PHP - 用openssl_random_pseudo_bytes()替换mcrypt_create_iv()
我需要提高我们网站的安全性,目前正在使用这里的指南:http://crackstation.net/hashing-security.htm,以及随机密码的生成:https://defuse.ca/generating -random-passwords.htm.我收集到两者都使用函数mcrypt_create_iv()生成随机字节(或位?),但由于某种原因,我在CentOS 6下安装php-mcrypt时遇到错误.幸运的是,第一个链接说openssl_random_pseudo_bytes()是CSPRNG(以及PHP文档和其他来源也支持该声明),并且可以在PHP 5.4的当前服务器安装上使用,因此我别无选择,只能使用它.考虑到这些,我想问以下问题:
直接代码替换是否足以影响安全性?(也就是说,只是将呼叫替换
mcrypt_create_iv()为openssl_random_pseudo_bytes()会这样做?)关于代码中提到的常量(http://crackstation.net/hashing-security.htm#properhashing),指南说"确保你的盐至少和哈希函数的输出一样长." 我是否正确地假设
PBKDF2_SALT_BYTES并且PBKDF2_HASH_BYTES都被设置为24字节,因为pbkdf2()函数的输出将只是24字节,而不是32(对于256位),因为使用的基础算法是sha256?(是的,我也在使用键拉伸.)在相关的说明中,是24字节,或者应该增加/减少,这会产生什么影响?
感谢那些愿意回答的人.
推荐指数
解决办法
查看次数
如何减少 Tensorlfow/Keras 使用的 CPU 数量?
我正在使用 Tensorflow 2.0 的 Keras api。
在调用fit我的 Keras 模型时,它使用所有可用的 CPU。
我想限制使用的 CPU 的数量。然而,它曾经在以前版本的 Tensorflow 中工作的方式不能再使用了:
tf.keras.backend.set_session(tf.compat.v1.Session(config=tf.compat.v1.ConfigProto(
intra_op_parallelism_threads=2, inter_op_parallelism_threads=2)))
AttributeError:模块“tensorflow.python.keras.api._v2.keras.backend”没有属性“set_session”
我怎么能那样做?
推荐指数
解决办法
查看次数
Snowball Stemmer只是最后一个词
我想使用R中的tm包来阻止纯文本文档语料库中的文档.当我将SnowballStemmer函数应用于语料库的所有文档时,只会阻止每个文档的最后一个单词.
library(tm)
library(Snowball)
library(RWeka)
library(rJava)
path <- c("C:/path/to/diretory")
corp <- Corpus(DirSource(path),
readerControl = list(reader = readPlain, language = "en_US",
load = TRUE))
tm_map(corp,SnowballStemmer) #stemDocument has the same problem
我认为这与文档被读入语料库的方式有关.用一些简单的例子说明这一点:
> vec<-c("running runner runs","happyness happies")
> stemDocument(vec)
[1] "running runner run" "happyness happi"
> vec2<-c("running","runner","runs","happyness","happies")
> stemDocument(vec2)
[1] "run" "runner" "run" "happy" "happi" <-
> corp<-Corpus(VectorSource(vec))
> corp<-tm_map(corp, stemDocument)
> inspect(corp)
A corpus with 2 text documents
The metadata consists of 2 tag-value pairs and a data frame
Available tags are: …推荐指数
解决办法
查看次数
删除ggplot多面图中的一些轴标签
我创建像一个阴谋在这里的人用ggplot2包和facet_wrap功能,我想抑制一些x轴的文字,使之更加清晰.
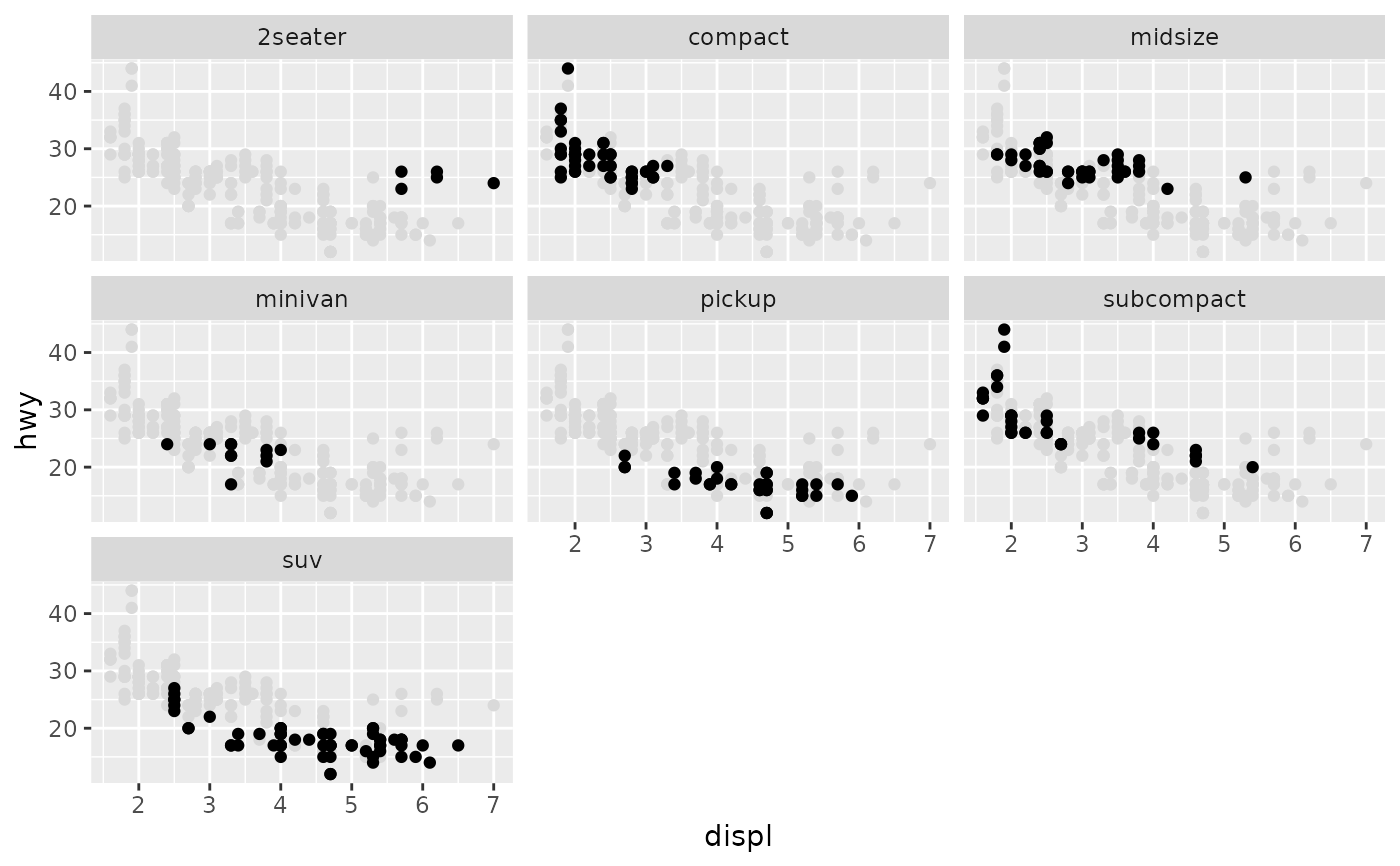{kind=link}
例如,如果x轴刻度仅出现在方框D,F,H和J上,那么它将更清晰.
我怎么能这样做?提前致谢!
编辑:可重现的代码
library(ggplot2)
d <- ggplot(diamonds, aes(carat, price, fill = ..density..)) +
xlim(0, 2) + stat_binhex(na.rm = TRUE) + theme(aspect.ratio = 1)
d + facet_wrap(~ color, nrow = 1)

推荐指数
解决办法
查看次数
使用sbt编译spark项目时未解决的依赖问题
我试图编译sbt 0.13.8一个非常简单的火花项目,其唯一的功能是
Test.scala
import org.apache.spark.SparkContext
import org.apache.spark.SparkContext._
import org.apache.spark.SparkConf
object SimpleApp {
def main(args: Array[String]) {
val logFile = "YOUR_SPARK_HOME/README.md" // Should be some file on your system
val conf = new SparkConf().setAppName("Simple Application")
val sc = new SparkContext(conf)
val logData = sc.textFile(logFile, 2).cache()
val numAs = logData.filter(line => line.contains("a")).count()
val numBs = logData.filter(line => line.contains("b")).count()
println("Lines with a: %s, Lines with b: %s".format(numAs, numBs))
}
}
projet根目录中的build.sbt文件如下:
name := "Test"
version := "1.0"
scalaVersion := …推荐指数
解决办法
查看次数
在TF 2.0中使用Tensorflow / Keras模型时,嵌入层存在问题
我按照TF初学者教程之一的步骤创建了一个简单的分类模型。它们是:
from __future__ import absolute_import, division, print_function, unicode_literals
import numpy as np
import pandas as pd
import tensorflow as tf
from tensorflow import feature_column
from tensorflow.keras import layers
from sklearn.model_selection import train_test_split
URL = 'https://storage.googleapis.com/applied-dl/heart.csv'
dataframe = pd.read_csv(URL)
dataframe.head()
train, test = train_test_split(dataframe, test_size=0.2)
train, val = train_test_split(train, test_size=0.2)
def df_to_dataset(dataframe, shuffle=True, batch_size=32):
dataframe = dataframe.copy()
labels = dataframe.pop('target')
ds = tf.data.Dataset.from_tensor_slices((dict(dataframe), labels))
if shuffle:
ds = ds.shuffle(buffer_size=len(dataframe))
ds = ds.batch(batch_size)
return ds
batch_size = 5 # A …推荐指数
解决办法
查看次数
为什么用@ webapp2.cached_property装饰Jinja2实例
webapp2站点(http://webapp-improved.appspot.com/api/webapp2_extras/jinja2.html)有一个如何使用的教程webapp2_extras.jinja2,代码如下.
我的问题是:为什么缓存webapp2_extras.jinja2.Jinja2实例返回return jinja2.get_jinja2(app=self.app)?我检查了代码@webapp2.cached_property并发现它将Jinja2实例缓存在一个实例中BaseHandler,它会在请求后被销毁,所以为什么要费心去缓存呢?我在这里错过了什么吗?
import webapp2
from webapp2_extras import jinja2
class BaseHandler(webapp2.RequestHandler):
@webapp2.cached_property
def jinja2(self):
# Returns a Jinja2 renderer cached in the app registry.
return jinja2.get_jinja2(app=self.app)
def render_response(self, _template, **context):
# Renders a template and writes the result to the response.
rv = self.jinja2.render_template(_template, **context)
self.response.write(rv)
推荐指数
解决办法
查看次数
为什么执行者会被司机杀死?
我的 Spark 工作的第一阶段非常简单。
- 它读取大量文件(大约 30,000 个文件,总共 100GB)->
RDD[String] - 做一个映射(解析每一行)->
RDD[Map[String,Any]] - 过滤器->
RDD[Map[String,Any]] - 合并 (
.coalesce(100, true))
运行它时,我观察到一种非常奇怪的行为。执行者的数量不断增长,直到达到我指定的给定限制spark.dynamicAllocation.maxExecutors(在我的应用程序中通常为 100 或 200)。然后它开始快速减少(大约 14000/33428 个任务),只剩下少数执行程序。他们是killed by the drive。当这个任务完成后。执行者的数量增加回其最大值。
下面是执行者数量最低时的屏幕截图。

这是任务摘要的屏幕截图。

我猜这些执行者是因为闲着才被杀的。但是,在这种情况下,我不明白他们为什么会变得无所事事。这个阶段还有很多任务要做……
您知道为什么会发生这种情况吗?
编辑
有关执行程序被杀死时驱动程序日志的更多详细信息:
16/09/30 12:23:33 INFO cluster.YarnClusterSchedulerBackend: Disabling executor 91.
16/09/30 12:23:33 INFO scheduler.DAGScheduler: Executor lost: 91 (epoch 0)
16/09/30 12:23:33 INFO storage.BlockManagerMasterEndpoint: Trying to remove executor 91 from BlockManagerMaster.
16/09/30 12:23:33 INFO storage.BlockManagerMasterEndpoint: Removing block manager BlockManagerId(91, server.com, 40923)
16/09/30 12:23:33 INFO storage.BlockManagerMaster: Removed 91 successfully …推荐指数
解决办法
查看次数
标签 统计
r ×3
apache-spark ×2
keras ×2
python ×2
scala ×2
tensorflow ×2
caching ×1
facet ×1
ggplot2 ×1
gtable ×1
jinja2 ×1
mcrypt ×1
openssl ×1
perl ×1
php ×1
properties ×1
python-3.6 ×1
sbt ×1
statistics ×1
stemming ×1
tm ×1
webapp2 ×1