标签: wikidata
在Sparql查询中优先化属性
这是关于Sparql和Wikidata的问题.我想制定一个返回实例类型关系的查询,但如果它不可用则返回其子类.我试过了:
SELECT DISTINCT ?ent_type WHERE {
{ wd:Q7696957 wdt:P31 ?instanceof . } UNION
{ wd:Q7696957 wdt:P31/wdt:P279? ?subclass . } UNION
{ wd:Q7696957 wdt:P279* ?subclass . }
BIND ( IF (BOUND (?instanceof), ?instanceof, ?subclass ) as ?ent_type )
但不幸的是,这会返回所有解决方案,而我只想要一个解决方案
ent_type
----------
wd:Q811979
wd:Q386724
wd:Q811430
wd:Q7696957
推荐指数
解决办法
查看次数
使用Wikidata中的SPARQL获取实体标签数据
我正在使用Wikidata的查询服务来获取数据:https ://query.wikidata.org/
我已经设法通过两种方法使用实体的标签:
- 使用Wikibase标签服务。例如:
Run Code Online (Sandbox Code Playgroud)SELECT ?spouse ?spouseLabel WHERE { wd:Q1744 wdt:P26 ?spouse. SERVICE wikibase:label { bd:serviceParam wikibase:language "en" . } }
- 使用
rdfs:label属性:
Run Code Online (Sandbox Code Playgroud)SELECT ?spouse ?spouseLabel WHERE { wd:Q1744 wdt:P26 ?spouse. ?spouse rdfs:label ?spouseLabel. filter(lang(?spouseLabel) = "en"). }
但是,似乎对于复杂的查询,第二种方法的执行速度更快,这与MediaWiki用户手册指出的相反:
当您要检索标签时,该服务非常有用,因为它降低了SPARQL查询的复杂性,否则您将需要获得相同的效果。
(https://www.mediawiki.org/wiki/Wikidata_query_service/User_Manual#Label_service)
wikibase补充了我仅使用rdfs:label无法实现的功能?这似乎很奇怪,因为它们看起来都达到了相同的目的,但是rdfs:label方法似乎更快(这是合乎逻辑的,因为查询不需要联接来自外部源的数据)。
谢谢!
推荐指数
解决办法
查看次数
SPARQL - 返回主题列表的相互对象
如何在不知道这些主题的谓词/对象的情况下获取由主题列表共享的所有谓词+对象?
我们来看看维基数据中的这个示例查询:
SELECT ?chancellor WHERE{
?chancellor wdt:P39 wd:Q4970706. #P39 = position held, Q4970706 = Chancellor of Germany
}
此查询返回德国所有前任总理.
现在我想要返回每个谓词+对象,每个大臣都有共同点,例如每个主题都是人类的一个实例,出生在德国等等.
我想这很简单.但是我不知道.
推荐指数
解决办法
查看次数
Wikidata - SPARQL查询的请求限制
对维基数据的查询是否有限制(仅限SPARQL查询,而不是编辑)?我找不到任何关于此的官方文档.我想知道每分钟/每小时(以及每个IP地址)有多强的查询限制.
推荐指数
解决办法
查看次数
如何创建本地维基数据查询服务?
我正在尝试在 Wikidata 上运行 SPARQL 查询,但它超时了。我想下载转储并将其索引到某个数据库中,以便我可以使用 HTTP 请求运行本地 SPARQL 查询。我还需要支持特定于维基数据的扩展,如SERVICE wikibase:label. 我已经下载了一个 RDF 转储。什么是下一步?
推荐指数
解决办法
查看次数
Wikidata + SPARQL:根据股票代码查找公司
我正在尝试使用sparql查找基于其股票代码的公司。
此查询将列出企业及其代码(基本查询)
SELECT DISTINCT ?id ?idLabel ?ticker
WHERE {
?id wdt:P31/wdt:P279* wd:Q4830453 .
?id wdt:P249 ?ticker .
?id rdfs:label ?idLabel
FILTER(LANG(?idLabel) = 'en').
}
但是,不包括IBM,因为IBM已将其股票代码放置在P414属性(证券交易所)的“内部”。
https://www.wikidata.org/wiki/Q37156
如何扩大此列表的范围,使其包括“内部”带有P414和P249代码的公司?
这是我可以显示不包括ibm的方法:
SELECT DISTINCT ?id ?idLabel ?exchange ?ticker2
WHERE {
?id wdt:P31/wdt:P279* wd:Q4830453 .
?id wdt:P249 ?ticker . FILTER(LCASE(STR(?ticker)) = 'ibm') .
?id rdfs:label ?idLabel
FILTER(LANG(?idLabel) = 'en').
}
推荐指数
解决办法
查看次数
SPARQL中的GROUP和COUNT
我正在使用WikiData SPARQL端点搜索两个实体:具有instagram和twitter帐户以及它们来自哪个国家的博物馆(wd:Q33506)和图书馆(wd:Q7075)。我试图对它们进行计数并按国家/地区分组。
SELECT ?item ?instagram ?twitter ?countryLabel (COUNT(?country) AS ?ccount) WHERE {
{ ?item (wdt:P31/wdt:P279*) wd:Q33506. }
{ ?item (wdt:P31/wdt:P279*) wd:Q7075. }
?item wdt:P2003 ?instagram.
?item wdt:P2002 ?twitter.
SERVICE wikibase:label { bd:serviceParam wikibase:language "en". }
OPTIONAL { ?item wdt:P17 ?country. }
}
GROUP BY ?country
ORDER BY ?ccount
推荐指数
解决办法
查看次数
如何获得近似术语的Wikidata标签?
我正在使用下面提到的查询来获取给定术语的wikidata标签。
SELECT ?item WHERE {
?item rdfs:label "Word2vec"@en
}
输出为: wd:Q22673982
但是,当我拼写Word2vec为word2vec(即所有字符都是简单字母)时,上述查询没有任何结果。
因此,我想知道是否有一种方法来获取该术语的含义wikidata并获得其标志?
即,如果我输入的所有字符均小写,如何识别等效的wikidata术语并返回其对应的标签?
如果需要,我很乐意提供更多详细信息。
推荐指数
解决办法
查看次数
Wikidata api 如何根据维基百科页面 id 获取一些属性
所以我有这个页面 ID 12517871:https ://fr.wikipedia.org/wiki ? curid = 12517871
我想从这里的底部获取标识符https://www.wikidata.org/wiki/Q64007200
使用 sparql,但我不知道该怎么做。
我知道我必须使用类似的东西
SELECT ?sitelink ?itemLabel ?sitelinkLabel ?article ?cid WHERE {
?sitelink schema:isPartOf <https://fr.wikipedia.org/>.
}
但后来我不知道如何按页面 id 搜索以及如何获取标识符(imdb、allocine ..)
谢谢
编辑:我正在使用此查询https://w.wiki/GD5但它随机不返回任何内容。要测试这种随机性,请更改“限制”上的数字
SELECT ?propertyclaim ?value ?item WHERE {
hint:Query hint:optimizer "None" .
SERVICE wikibase:mwapi {
bd:serviceParam wikibase:endpoint "fr.wikipedia.org" .
bd:serviceParam wikibase:api "Generator" .
bd:serviceParam mwapi:generator "revisions" .
bd:serviceParam mwapi:pageids "12148688" .
?item_ wikibase:apiOutputItem mwapi:item .
bd:serviceParam wikibase:limit 3
}
BIND (COALESCE(?item_, " ") AS ?item)
?item ?propertyclaim ?value …推荐指数
解决办法
查看次数
如何使用 SPARQL 获取 Wikidata 实体的*所有*超类?
我对可视化维基数据类层次结构感兴趣,以创建像 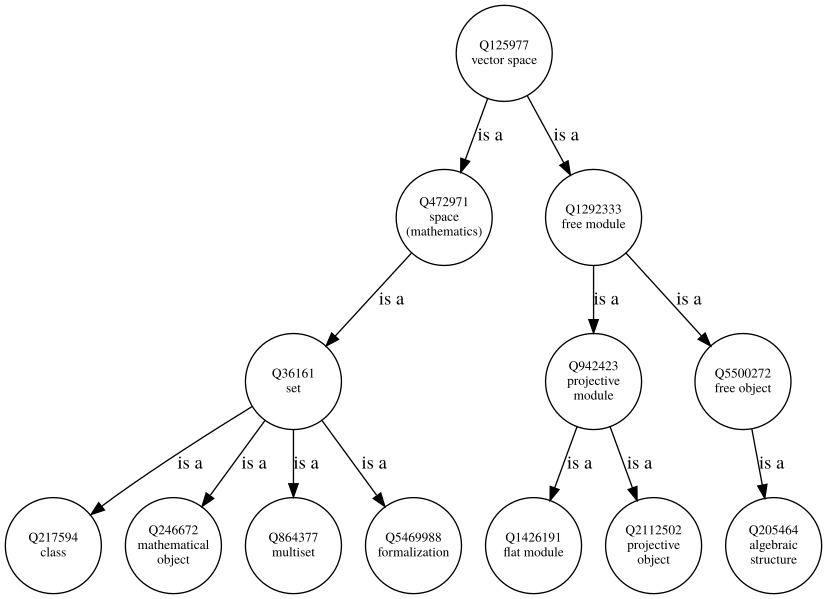
我知道如何获得维基数据实体的直接超类。为此,我使用 SPARQL 代码,例如:
SELECT ?item ?itemLabel
WHERE
{
wd:Q125977 wdt:P279 ?item.
SERVICE wikibase:label { bd:serviceParam wikibase:language "[AUTO_LANGUAGE],en". }
}
其中wdt:P279表示subclass of- 属性。
但是,这种直接方法需要对 Wikidata API 进行多次单一请求。
如何通过单个 SPARQL 查询获得相同的信息?
(请注意,上面的示例图仅显示了一个缩略版本。所有超类的最终所需图为 13 层深,有 69 个节点,这意味着 68 个单个请求,如果有兴趣,请参阅此 jupyter notebook。)
推荐指数
解决办法
查看次数
标签 统计
wikidata ×10
sparql ×9
rdf ×3
count ×1
dump ×1
grouping ×1
ontology ×1
semantic-web ×1
superclass ×1
wikidata-api ×1
wikipedia ×1