标签: tree-traversal
广度优先与深度优先
遍历树/图时,广度优先和深度之间的区别首先是什么?任何编码或伪代码示例都会很棒.
algorithm breadth-first-search tree-traversal depth-first-search
推荐指数
解决办法
查看次数
jquery在课堂上找到最近的兄弟姐妹
这是我开始使用的粗略html:
<li class="par_cat"></li>
<li class="sub_cat"></li>
<li class="sub_cat"></li>
<li class="par_cat"></li> // this is the single element I need to select
<li class="sub_cat"></li>
<li class="sub_cat"></li>
<li class="sub_cat current_sub"></li> // this is where I need to start searching
<li class="par_cat"></li>
<li class="sub_cat"></li>
<li class="par_cat"></li>
我需要遍历.current_sub,找到最接近的先前.par_cat并做一些事情.
.find("li.par_cat")返回整个负载.par_cat(我在页面上有大约30个).我需要针对单一目标.
非常感谢任何提示:)
推荐指数
解决办法
查看次数
如何从jQuery对象中获取选择器
$("*").click(function(){
$(this); // how can I get selector from $(this) ?
});
有没有一种简单的方法来获得选择器$(this)?有一种方法可以通过选择器选择元素,但是从元素中获取选择器呢?
推荐指数
解决办法
查看次数
在不使用堆栈或递归的情况下解释Morris inorder树遍历
有人可以帮我理解下面的Morris inorder树遍历算法而不使用堆栈或递归吗?我试图了解它是如何工作的,但它只是逃避了我.
1. Initialize current as root
2. While current is not NULL
If current does not have left child
a. Print current’s data
b. Go to the right, i.e., current = current->right
Else
a. In current's left subtree, make current the right child of the rightmost node
b. Go to this left child, i.e., current = current->left
我理解的树被修改的方式,将current node在作出right child的的max node中right subtree和使用该财产序遍历.但除此之外,我迷失了.
编辑:找到这个附带的c ++代码.我很难理解修改后树的恢复方式.神奇在于else子句,一旦修改了正确的叶子就会被击中.请参阅代码了解详情:
/* Function to traverse binary …推荐指数
解决办法
查看次数
Python:超出了最大递归深度
我有以下递归代码,在每个节点我调用sql查询以获取属于父节点的节点.
这是错误:
Exception RuntimeError: 'maximum recursion depth exceeded' in <bound method DictCursor.__del__ of <MySQLdb.cursors.DictCursor object at 0x879768c>> ignored
RuntimeError: maximum recursion depth exceeded while calling a Python object
Exception AttributeError: "'DictCursor' object has no attribute 'connection'" in <bound method DictCursor.__del__ of <MySQLdb.cursors.DictCursor object at 0x879776c>> ignored
我调用以获取sql结果的方法:
def returnCategoryQuery(query, variables={}):
cursor = db.cursor(cursors.DictCursor);
catResults = [];
try:
cursor.execute(query, variables);
for categoryRow in cursor.fetchall():
catResults.append(categoryRow['cl_to']);
return catResults;
except Exception, e:
traceback.print_exc();
我实际上对上述方法没有任何问题,但我还是把它放在了正确的问题概述上.
递归代码:
def leaves(first, path=[]):
if first:
for elem in …推荐指数
解决办法
查看次数
使用常量空间和O(n)运行时编写二进制搜索树的非递归遍历
这不是作业,这是一个面试问题.
这里的问题是算法应该是恒定的空间.我对如何在没有堆栈的情况下做到这一点非常无能为力,我会发布我使用堆栈编写的内容,但无论如何它都不相关.
这是我尝试过的:我试图进行预订遍历,然后我到了最左边的节点,但我被困在那里.我不知道如何在没有堆栈/父指针的情况下"recurse"备份.
任何帮助,将不胜感激.
(我将它标记为Java,因为这是我很习惯使用的,但它显然是语言无关的.)
推荐指数
解决办法
查看次数
帮助我理解Inorder Traversal而不使用递归
我能够理解preorder遍历而不使用递归,但我很难进行inorder遍历.我也许似乎没有得到它,因为我还没有理解递归的内在工作.
这是我到目前为止所尝试的:
def traverseInorder(node):
lifo = Lifo()
lifo.push(node)
while True:
if node is None:
break
if node.left is not None:
lifo.push(node.left)
node = node.left
continue
prev = node
while True:
if node is None:
break
print node.value
prev = node
node = lifo.pop()
node = prev
if node.right is not None:
lifo.push(node.right)
node = node.right
else:
break
内部的while循环感觉不对劲.此外,一些元素被打印两次; 也许我可以通过检查之前是否打印过该节点来解决这个问题,但这需要另一个变量,这也是感觉不对.我哪里错了?
我没有尝试过postorder遍历,但我猜它类似,我也将面临同样的概念障碍.
谢谢你的时间!
PS:Lifo和的定义Node:
class Node:
def __init__(self, value, left=None, right=None):
self.value = value
self.left = left
self.right …推荐指数
解决办法
查看次数
有序树遍历
我之前的一篇学术课程中有以下关于二阶树(不是BST)的有序遍历(它们也称之为pancaking)的文本:
有序树遍历
在树的外面画一条线.从根的左侧开始,绕过树的外部,最后到根的右侧.尽可能靠近树,但不要越过树.(想想树 - 它的分支和节点 - 作为一个坚实的障碍.)节点的顺序是这条线在它们下面经过的顺序.如果您不确定何时"在节点下面",请记住"左侧"节点始终位于第一位.
这是使用的示例(从下面略微不同的树)
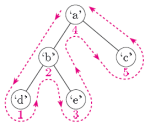
但是,当我在谷歌搜索时,我得到一个相互矛盾的定义.例如维基百科的例子:

顺序遍历序列:A,B,C,D,E,F,G,H,I(左子节点,根节点,右节点)
但根据(我的理解)定义#1,这应该是
A,B,D,C,E,F,G,I,H
任何人都可以澄清哪个定义是正确的?它们可能都描述了不同的遍历方法,但碰巧使用相同的名称.我很难相信同行评审的学术文本是错误的,但不能确定.
推荐指数
解决办法
查看次数
预订到订单后的遍历
如果二叉搜索树的预订遍历是6,2,1,4,3,7,10,9,11,那么如何获得后序遍历?
推荐指数
解决办法
查看次数
树遍历的时间复杂度是多少?
树遍历的时间复杂度是多少,我敢肯定它一定是显而易见的,但是我的可怜的大脑现在无法解决这个问题.
推荐指数
解决办法
查看次数
标签 统计
tree-traversal ×10
algorithm ×3
binary-tree ×3
jquery ×2
python ×2
traversal ×2
tree ×2
c++ ×1
depth ×1
html ×1
java ×1
javascript ×1
max ×1
recursion ×1